

It doesn’t take more than a quick Google search to see why enterprises around the world are retiring Hadoop; “decline of Hadoop” produces nearly a half million points of reference. If you’re considering Hadoop exit strategies and alternatives, SingleStore is one of the best options — read on to learn about the top five reasons why.
Reason #1: Modern Distributed Architecture
SingleStore is a fast, distributed, highly scalable SQL data platform designed to power today’s data-intensive applications. It delivers maximum performance for both transactional (OLTP) and analytical (OLAP) workloads in a single unified engine to drive maximum performance for your modern applications and analytics.
Here’s a key differentiator: SingleStore’s patented Universal Storage offers an innovative breakthrough in database architecture, allowing both transactional and analytic workloads to be processed using a single table type across large, dynamic datasets queried at high concurrency.
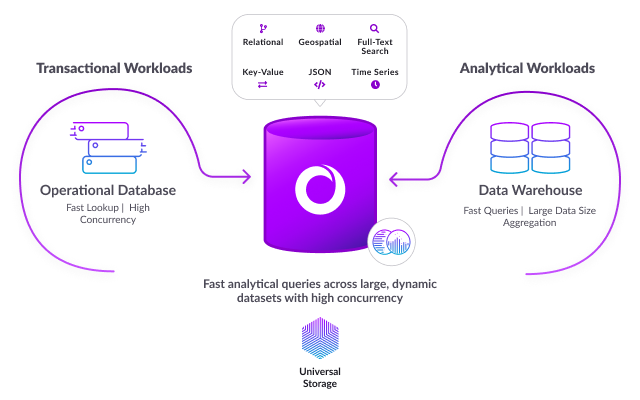
Additional SingleStore architecture highlights include:
- Connects to a wide variety of data sources: SingleStore Pipelines offer native, high-throughput data ingestion from external sources including Apache Kafka, Amazon S3, Microsoft Azure Blob, Filesystem, Google Cloud Storage (GCP) and HDFS. Data is ingested in parallel and in real time.
- Handles any type of data (multi-model): SingleStore breaks down the silos and requirements of specialized databases that have proliferated across the enterprise. Any type of data — relational, document, JSON, key-value, geospatial, time-series, full-text search and more — can be processed and analyzed with SingleStore.
- Supports separation of storage and compute: SingleStore cloud users can store limitless volumes of data without increasing query latency; compute resources can scale effortlessly to handle any workload, independent of storage.
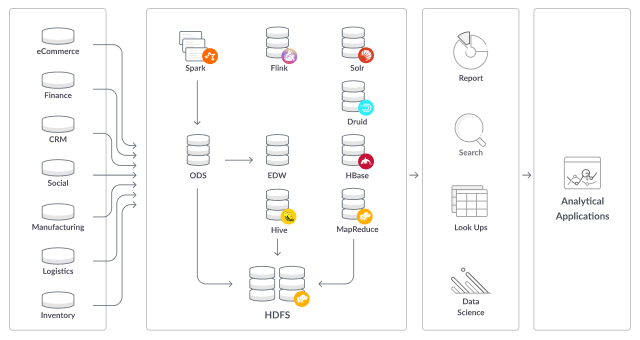
The technology mapping chart summarizes why SingleStore is the modern, ideal Hadoop replacement engine.

Reason #2: Drive 100-1000x Faster Analytics
From the ground up, SingleStore is a distributed SQL platform that allows you to achieve ultra-fast query response with high concurrency across both live and historical data using familiar ANSI SQL.
Hadoop was not built to execute fast analytics or support the data-intensive applications that enterprises demand, and its reliance on the Hive SQL engine to perform complex analytics adds complexity and latency. Its query performance is not optimized for modern workloads, lagging dangerously behind current enterprise requirements. Complex queries can take hours to execute in Hadoop.
In comparison, SingleStore can drive 100-1000x better performance and time-to-insight, enabled by key architecture features including:
- Patented Universal Storage: I mentioned this above and it merits a second mention: SingleStore unifies traditional database row stores and column stores into one patented, novel table type called Universal Storage. This design breakthrough allows transactions and analytics to be executed simultaneously on the same table type.
- Streaming ingestion and analytics: Hadoop’s batch operations make it impossible to perform analytics on fast-moving or streaming data. SingleStore readily handles both data-at-rest as well as data-in-motion with high ingestion rates of up to millions of rows per second, concurrently executing real-time analytics.
- Fastest event-to-insight response: SingleStore’s blazing fast performance delivers quick insights and enables real-time applications to meet the toughest service level agreements (SLAs). SingleStore regularly delivers single-digit millisecond response times for complex queries across both live and historical data — often 100-1000x faster than Hadoop.
Customers are actively migrating workloads off Hadoop into SingleStore to drive faster analytics while achieving dramatic speed improvements. Figure 2 shows how replacing Hadoop with SingleStore can greatly simplify enterprise data environments.
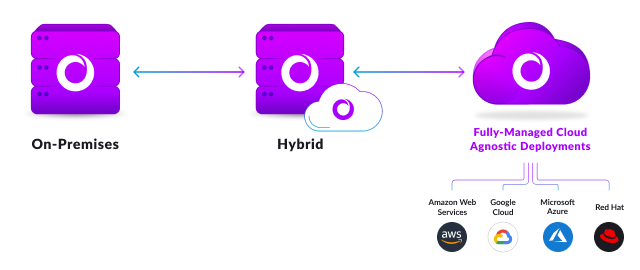
An important point: any replacement or augmentation of Hadoop can be deployed entirely on-premises, in the cloud with a provider of choice or in a hybrid mode as enterprises continue to navigate their way to the cloud.
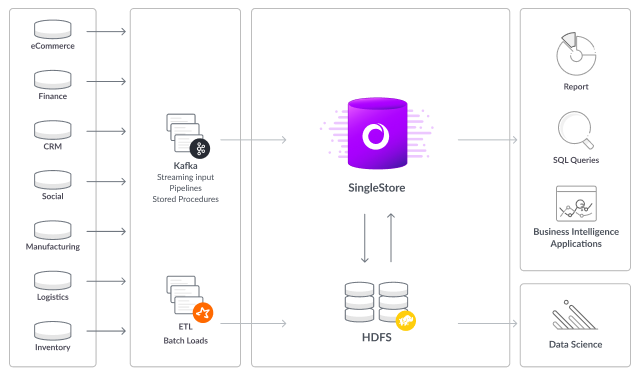
Reason #3: Up to 50% Lower Costs
Hadoop installations can cost up to \$10,000 per node in license fees alone. Moreover, Hadoop requires three times more hardware resources than a modern database like SingleStore. But its total cost of ownership (TCO) is truly prohibitive, with ongoing management and administration of Hadoop clusters typically requiring four to eight full-time high-value staff resources for every 100 nodes.
SingleStore can eliminate Hadoop’s high deployment and ongoing management costs with a modern architecture that is 65% more efficient, requiring only one-third the hardware of a comparable Hadoop implementation. More importantly, it eliminates the need for scores of dedicated high-end support personnel and resources. The teams who now tend to Hadoop installations can be deployed to higher-value tasks.
Reason #4: Zero Complexity
Because any Hadoop installation comprises a string of multiple open source projects, its architecture is inherently complex and failure-prone. Given the complexity of the architecture, Hadoop is fraught with multiple points of failure, driving up latency and risks. Some enterprises experience over 300 outages per month.
SingleStore is built on a robust, modern distributed architecture. A single instance of SingleStore can replace a daisy chain of Hadoop clusters, eliminating the need to stitch together and troubleshoot multiple open-source projects. And with its Singlestore Helios (database-as-a-service offering), SingleStore completely removes the need for users to manage infrastructure, provision clusters, handle upgrades or troubleshoot failures. Hadoop’s volatility — often hundreds of outages and failures per month — disappears, along with its operational complexity.
Reason #5: Runs Anywhere
Enterprises continue to demand flexibility to be able to run workloads anywhere–on-premises, in the cloud, or in a hybrid mode. SingleStore offers multiple options to retire or migrate workloads off Hadoop, with the flexibility to deploy and run anywhere. Not ready to move workloads to the cloud yet? No worries. With SingleStore, enterprises don’t have to lift and shift workloads to the cloud; SingleStore can run completely on-premises, in the data center, in any of the leading cloud environments or in a hybrid fashion.
However, if desired, on-premises Hadoop workloads can be moved to the cloud. SingleStore provides a phased approach to migrate some or all of the data and Hadoop workloads to the cloud. Singlestore Helios offers a multi- and hybrid-cloud solution that can be deployed on Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform, or directly in a customer datacenter with the SingleStore Dedicated offering.
If it seems like there are strong benefits to be gained from moving away from antiquated Hadoop architectures, you’re right. To learn more, check out our webinar, “Augmenting or Replacing Hadoop With SingleStore” today.













.png?width=24&disable=upscale&auto=webp)
