
AIシステムはここ数年で大きく進化し、いまではノーコードやローコードのプラットフォーム/ツールを使って、誰でも高い自律性を持つエージェント型システムを構築できる時代になりました。
LLMチャットボットからRAG(Retrieval-Augmented Generation)システム、そしてAIエージェントへと進化を遂げてきましたが、依然としてひとつの課題が残っています。――それは「コンテキスト(文脈)」です。
LLM(大規模言語モデル)は推論時点で持っている情報の質と量にしか依存できません。適切なデータ・ツール・シグナルがなければ、幻覚(ハルシネーション)を起こしたり、誤った判断を下したり、安定した実行に失敗することがあります。
したがって、AIシステムには「正しいタイミングで」「適切なコンテキスト」を与える仕組みが必要です。
これを実現するために登場したのが――「コンテキストエンジニアリング(Context Engineering)」という新しい分野です。
これは、AIシステムが最大限に効率的かつ価値を生み出すよう、最適なコンテキストを設計・提供するための新しい専門領域なのです。

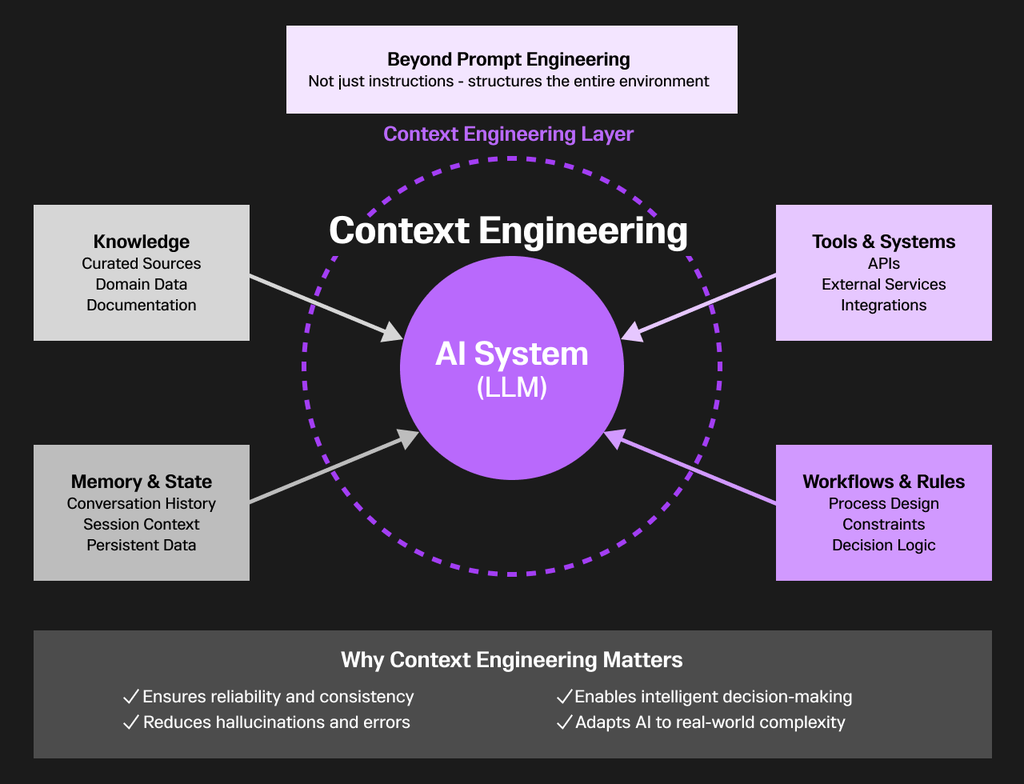
プロンプトエンジニアリングが主にLLM(大規模言語モデル)への指示文を工夫して作ることに焦点を当てているのに対し、コンテキストエンジニアリングは、AIシステムが動作する周辺環境を体系的に設計・最適化するための学問的アプローチです。
これは単なるプロンプト作成にとどまらず、AIシステムがタスクを実行する際に必要となるデータ、ツール、情報、ワークフローなどを緻密に構成し、全体的なコンテキスト(文脈)を維持・管理する仕組みを設計することを意味します。
その結果、コンテキストエンジニアリングは、AIのタスク実行を創造的であるだけでなく、信頼性が高く、一貫性があり、知的に行えるようにするのです。
コンテキストエンジニアリングの核心にある考え方は、LLMそのものはタスクに関する「本質的な知識」を持っていないという認識です。
その有効性は、与えられるコンテキストの質と完全性に大きく依存しています。
これを実現するためには、
- 適切なナレッジソース(知識源)の選定と管理
- 外部システムとの統合
- 対話をまたいだメモリの維持
- 必要なときに必要なツールへアクセスできる仕組みの整備
といった要素が不可欠です。
わずかなコンテキストの欠落であっても、結果が大きく変わることがあります。それは、誤り・矛盾・幻覚(ハルシネーション)といった形で現れます。
だからこそ、コンテキストエンジニアリングは、堅牢なAIアプリケーションを構築するうえで最も重要な実践領域の一つとして注目を集めています。
それは単に「モデルに何をさせるか」を指示することではなく、AIがより良い判断を下し、効果的に推論し、現実世界の複雑さに適応できるように、舞台・ルール・リソースを整えることなのです。
プロンプトエンジニアリング vs. コンテキストエンジニアリング
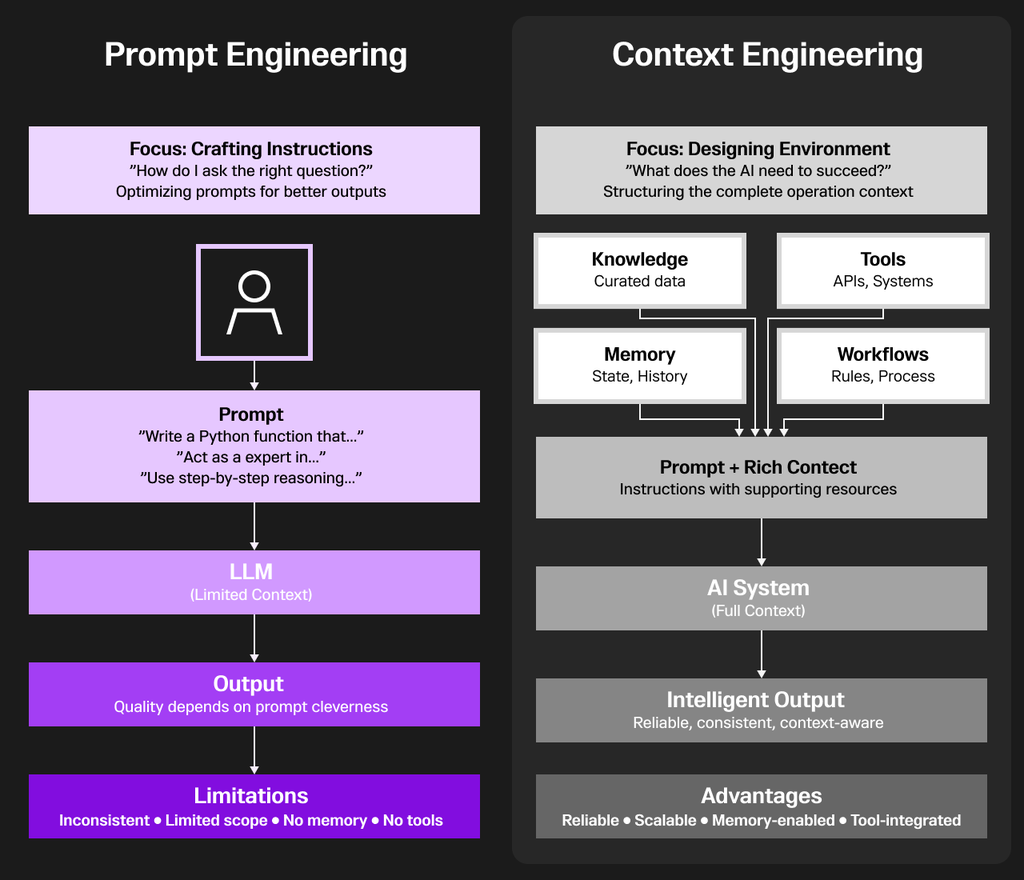
コンテキストエンジニアリングは、AIシステムの本質的な制約 ―「与えられた情報しか知らない」― を解決する点で、プロンプトエンジニアリングよりも根本的に優れています。
プロンプトエンジニアリングは、背景情報やツール、参照資料を一切与えずに人に指示を出すようなものです。
常に1つの質問の中にすべての情報を詰め込もうとし、AIがそれを覚えて正しく答えてくれることを期待するしかありません。
しかしこの方法は信頼性に欠けます。
同じプロンプトでも結果が毎回異なることがあり、対話間で一貫性を維持することも、リアルタイムデータへアクセスすることもできません。
コンテキストエンジニアリングは、AIを単体の存在ではなく、全体システムの一部として扱います。
巧妙な言い回し(プロンプト)に頼るのではなく、AIが正しく機能するための環境そのものを設計(アー��キテクト)するのです。
具体的には、
- 正確な情報にアクセスできるようナレッジデータベースを統合し、
- 外部ツールやAPIを接続して、AIが実際のアクションを実行できるようにし、
- 過去の対話を記憶するメモリシステムを実装し、
- 一貫性と予測可能性のある動作を保証するワークフローを整備する。
こうしてAIが「文脈を理解し、継続的に賢く行動できるシステム」として機能するようにするのが、コンテキストエンジニアリングなのです。
その違いは本質的で深いものです。
プロンプトエンジニアリングは「より良い質問をする」ことに焦点を当て、コンテキストエンジニアリングは「より良いシステムを構築する」ことを目的としています。
前者はときどき印象的な出力を生み出すに過ぎません��が、後者は信頼性が高く、本番環境で使えるAIアプリケーションを実現します。
わずかなコンテキストの欠落でも、幻覚(ハルシネーション)・誤り・失敗を引き起こします。
コンテキストエンジニアリングは、これらのギャップを体系的に排除し、AIが常に必要な情報を持ち、知的な判断を行い、一貫した結果を現実世界で提供できるようにするのです。
RAG vs. コンテキストエンジニアリング
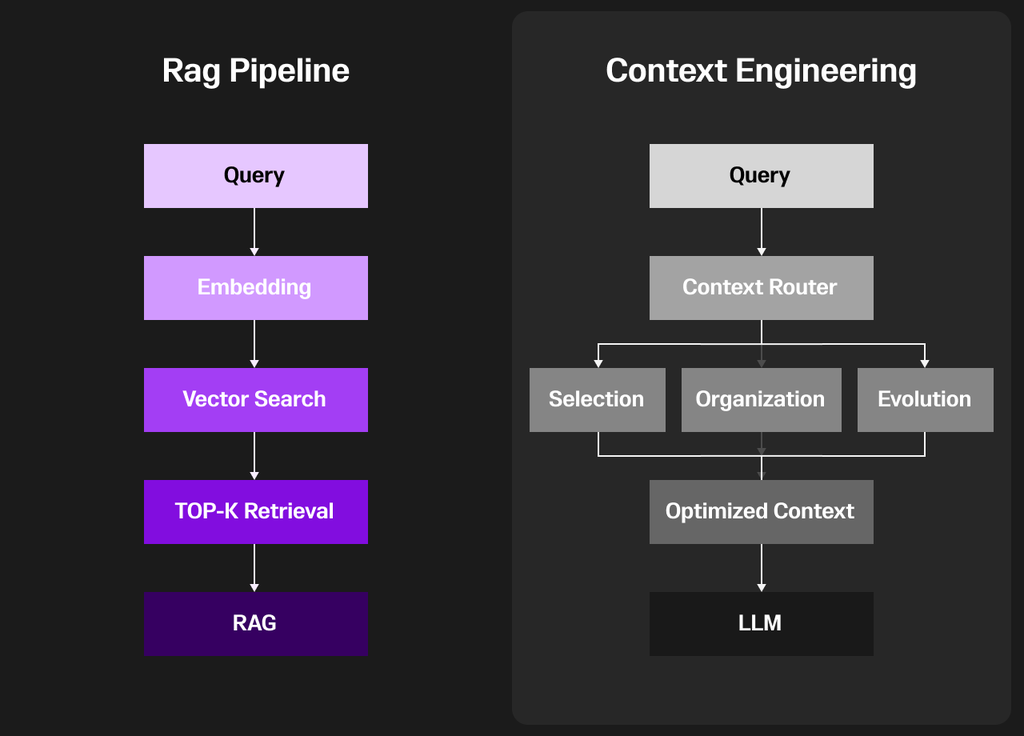
RAG(Retrieval-Augmented Generation)パイプラインは、まずユーザーからのクエリ(質問)から始まります。
そのクエリは埋め込み(embedding)と呼ばれる意味的な特徴を表現したベクトルに変換されます。
次に、システムはナレッジベース全体に対してベクトル検索を行い、最も関連性の高い情報を探し出します。
そしてTop-K検索によって、類似度の高い上位の情報をいくつか選び出し、それらをコンテキストとして詰め込み(stuffing into context)、LLM(大規模言語モデル)に入力します。
この手法により、モデルは外部知識を参照しながらより豊かな回答を生成できるようになりますが、一方で柔軟性に欠けるという課題もあります。
具体的には、類似度検索に過度に依存しており、コンテキストの使い方を動的に調整できないという制約があるのです。
右側の図(Context Engineeringの側)では、RAGの概念をさらに高度化・洗練しています。
ユーザーからのクエリを受け取ったあと、まず「コンテキストルーター(Context Router)」が導入され、どのように情報を処理・ルーテ�ィングするのが最適かを判断します。
このルーターは、主に以下の3つの重要なプロセスを担います:
- Selection(選定)
- Organization(整理)
- Evolution(進化)
これらのステップによって最適化されたコンテキストが生成され、最終的にそれがLLM(大規模言語モデル)に渡されて推論に利用されるのです。
The difference is clear: RAG fetches and dumps context, while context engineering curates, structures and evolves it, leading to more accurate, reliable and contextually aligned outputs.
コンテキストエンジニアリングにおけるMCPの役割
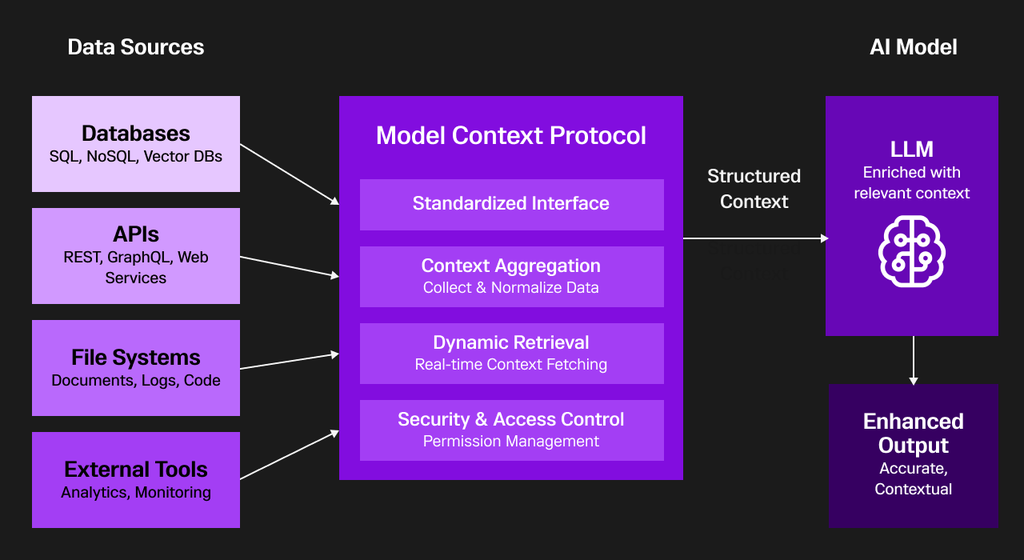
Model context protocol (MCP)は、現在のAIアプリケーション分野で「あらゆるツールやデータソースと接続できる“汎用USB”」として大きな注目を集めています。
従来のように個別のAPIごとに連携を構築する必要はなく、MCPを使えばすべてを一元的に管理できます。
このMCPはコンテキストエンジニアリングの中核的な基盤として機能し、多様なデータソースとAIモデルの間で標準化された仲介レイヤーとして動作します。
その結果、AIアプリケーションに対して構造化された・実行可能なコンテキストを提供できるのです。
MCPは、SQL・NoSQL・ベクトルストアといったデータベース、API、ファイルシステム、外部分析ツールなどとの間に共通のインターフェースを設けることで、複雑な個別統合の課題を解消します。
また、MCPは次の4つの主要機能を通じて、複数システムからのリアルタイムデータを統合・正規化・ガバナンスします:
- 標準化インターフェース(Standardized Interface)
- コンテキスト集約(Context Aggregation)
- 動的データ取得(Dynamic Retrieval)
- セキュリティ(Security)
これにより、MCPは多様なシステム間のデータフローをシームレスにつなぎ、AIが必要な情報をリアルタイムで安全に活用できる環境を実現します。
コンテキストエンジニアリングの領域において、MCP(Model Context Protocol)は「動的なコンテキスト抽出(Dynamic Context Elicitation)」を可能にします。
つまり、AIモデルの現在の意図やタスクに応じて、関連する情報を取得(fetch)し、組み立て(assemble)、安全に管理(secure)することで、応答の関連性を大幅に向上させ、最新かつ実在する企業知識に基づいた出力を実現します。
開発者はMCPサーバーを利用して、企業固有のデータやアクセス権限を外部に公開します。
一方、AIエージェント(たとえばLLM)はMCPクライアン�トを通じてこれらの情報源に接続し、機械が理解可能な形式でコンテキストを取り込み、ユーザーからの質問に応答し、
最新データに基づいて**動的に出力内容を適応(adapt)**させるのです。
要するに、MCPはAIと企業内知識の間をリアルタイムで橋渡しするプロトコルであり、AIが「常に文脈を理解し続ける」ための中核的なコンテキスト基盤として機能します。
SingleStoreは、AIワークフローにおけるMCP(Model Context Protocol)の実用的な力を体現する代表的な存在です。
SingleStoreの MCP server は、LLM(大規模言語モデル)とSingleStoreの高性能データベースを橋渡しし、自然言語によるクエリ実行、ワークスペース管理、SQLの実行、スキーマの可視化といった操作を、ClaudeのようなAIアシスタントや開発ツール上から直接行えるようにします。
- 企業データベースとの認証を行い、
- ユーザーごとのセッションを管理し、
- アクセス制御(Access Control)を適用し、
- 運用系・分析系の両方のタスクにおいてシームレスかつコンテキストに富んだ対話を提供します。
その結果、SingleStoreは“現代のエンタープライズAIにおけるコンテキストエンジニアリングの模範的な実装(flagship implementation)”として位置づけられています。
SingleStoreによるコンテキスト認識型ワークフローの構築

図は、SingleStoreを長期記憶レイヤーとして据えた簡易版のコンテキストエンジニアリングのワークフローを示しています。
まずユーザー入力がクエリ/問題提起として受け取られます。
次にシステムは検索(retrieval)と組み立て(assembly)を行い、SingleStoreからベクトル検索で関連コンテキストを取得し、直近のチャット履歴などの短期記憶と組み合わせて、十分に文脈を含んだプロンプトを構成します。
この拡張プロンプトがLLM/AIエージェントに渡され、モデルはそれを処理して推論を行い、必要に応じて外部ツール呼び出しも実行しながら、一貫性があり根拠のある応答を生成します。
最終段階はライトバックメモリ(Write-Back Memory)です。
ここでは、AIが生成した回答、会話を通じて得た洞察、そして新たに獲得した知識が再びSingleStoreに書き戻されます。
これにより、各インタラクションがAIシステムのコンテキスト理解を強化し続ける仕組みが形成されます。
その結果、システム全体は時間の経過とともに自己進化するコンテキスト認識型ワークフローとなり、まさに“コンテキストエンジニアリングの本質(essence in action)”が体現されるので�す。
SingleStoreによるコンテキスト認識チュートリアル
SingleStoreにアクセスし、ワークスペース(workspace)とコンテキストを保持するためのデータベース(database)を作成します。
1pip install openai langchain langchain-community langchain-openai singlestoredb --quiet
1from langchain_openai import OpenAIEmbeddings # works after installing langchain-openai2from langchain_community.vectorstores import SingleStoreDB3from openai import OpenAI
1SINGLESTORE_HOST = "Add host URL" # your host2SINGLESTORE_USER = "admin" # your user3SINGLESTORE_PASSWORD = "Add your SingleStore DB password" # your password4SINGLESTORE_DATABASE = "context_engineering" # your database5OPENAI_API_KEY = "Add your OpenAI API key"
1connection_string = f"mysql://{SINGLESTORE_USER}:{SINGLESTORE_PASSWORD}@{SINGLESTORE_HOST}:3306/{SINGLESTORE_DATABASE}"
1embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)2client = OpenAI(api_key=OPENAI_API_KEY)
1from langchain_community.vectorstores import SingleStoreDB2from langchain_openai import OpenAIEmbeddings3 4embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)5 6vectorstore = SingleStoreDB(7 embedding=embeddings,8 table_name="context_memory",9 host=SINGLESTORE_HOST,10 user=SINGLESTORE_USER,11 password=SINGLESTORE_PASSWORD,12 database=SINGLESTORE_DATABASE,13 port=330614)
1docs = [2 {"id": "1", "text": "SingleStore unifies SQL and vector search in a single engine."},3 {"id": "2", "text": "Context engineering ensures AI agents always have the right context at the right time."},4 {"id": "3", "text": "SingleStore is ideal for real-time RAG pipelines due to low-latency queries."}5]6 7# Insert into vector DB8vectorstore.add_texts([d["text"] for d in docs], ids=[d["id"] for d in docs])9print("✅ Knowledge inserted into SingleStore")
1query = "Why is SingleStore useful for context engineering?"2results = vectorstore.similarity_search(query, k=2)3 4print("🔹 Retrieved Context:")5for r in results:6 print("-", r.page_content)
1from openai import OpenAI2client = OpenAI(api_key=OPENAI_API_KEY)3 4user_input = "Explain context engineering using SingleStore."5 6context = "\n".join([r.page_content for r in results])7 8prompt = f"""9You are a helpful AI agent.10User asked: {user_input}11Relevant context from memory:12{context}13"""14 15response = client.chat.completions.create(16 model="gpt-4o-mini",17 messages=[{"role": "user", "content": prompt}]18)19 20print("🔹 Agent Answer:\n", response.choices[0].message.content)
1vectorstore.add_texts([2 f"User: {user_input}", 3 f"Assistant: {response.choices[0].message.content}"4])5 6 7print("✅ Conversation stored back into SingleStore for future retrieval")
1followup_query = "What did we discuss earlier about context engineering?"2followup_results = vectorstore.similarity_search(followup_query, k=3)3 4print("🔹 Follow-up Retrieved Context:")5for r in followup_results:6 print("-", r.page_content)
完全なノートブックコ�ードは、この GitHub repository に掲載されています。
コンテキスト駆動型AI(Context-Driven AI)が新たな未来を創り出す
AIシステムがより高性能になるにつれ、真の差別化要因は「モデルの大きさ」ではなく「コンテキストの質」になるでしょう。
適切なデータを、適切なタイミングで、適切な形式で提供できる能力こそが、AIの実用性と信頼性を決定づけます。
コンテキストエンジニアリングは、孤立したLLMを「理解し、記憶し、意図を持って行動する知的システム」へと変革します。
この新しいアプローチを取り入れることで、開発者は「巧妙なプロンプト設計」に依存する段階を超え、記憶(Memory)・推論(Reasoning)・実行(Execution)が調和して動作する“コンテキスト認識型エコシステム”を構築できるようになります。
LangChainのようなフレームワークや、SingleStoreのようなデータベースはこのビジョンを現実のものにします。
それらは、統合ストレージ・ハイブリッド検索・高速リトリーバルといった機能を提供し、AIに生きたコンテキスト(living context)を与えるのです。
要するに、コンテキストエンジニアリングは単なる流行語ではなく、次世代AIを支える中核的な基盤です。
これを早く習得すればするほど、私たちは「応答するだけのAI」ではなく、「本当に理解するAI」の実現に近づくことができるのです。









.png?width=24&disable=upscale&auto=webp)

