
The world of AI has come a long way. From initial hype to becoming a reality with tools like ChatGPT, it is an insanely amazing time for us all — who could have imagined a simple tool can write an entire article? Even if there were tools, they weren’t nearly as capable or powerful as the ones we see today that are backed by Large Language Models (LLMs).
These LLMs are able to perform various tasks just like a human brain. They store the meaning and context of the data fed in a specialized format known as embeddings. Imagine capturing the essence of a word, image or user in a single mathematical equation. That's the power of vector embeddings — one of the most fascinating and influential concepts in machine learning today.
What are vector embeddings?
Vector embeddings are dense representations of objects (including words, images or user profiles) in a continuous vector space. Each object is represented by a point (or vector) in this space, where the distance and direction between points capture semantic or contextual relationships between the objects. For example in NLP, similar words are mapped close together in the embedding space.
The significance of vector embeddings lies in their ability to capture the essence of data in a form that computer algorithms can efficiently process. By translating high-dimensional data into a lower-dimensional space, embeddings make it possible to perform complex computations more efficiently. They also help in uncovering relationships and patterns in the data that might not be apparent in the original space.
Types of vector embeddings
Generative AI applications are built using vector embeddings and the data source can range from text, audio, video and any type of structured and unstructured data. We can broadly divide these embeddings into four major categories:
- Word embeddings. These are the most common types of embeddings, used to represent words in NLP. Popular models include Word2Vec, GloVe and FastText.
- Sentence and document embeddings. These capture the semantic meaning of sentences and documents. Techniques like BERT and Doc2Vec are examples.
- Graph embeddings. These are used to represent nodes and edges of graphs in vector space, facilitating tasks like link prediction and node classification.
- Image embeddings. Generated by deep learning models, these represent images in a compact vector form, useful for tasks like image recognition and classification.
Creating vector embeddings
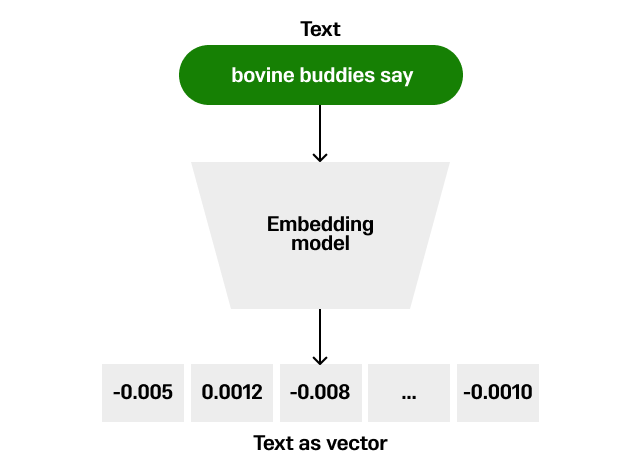
This process transforms text into numerical vectors, enabling algorithms to perform tasks including semantic search, text classification and sentiment analysis with enhanced accuracy and efficiency. The essence of vector embeddings lies in their ability to preserve semantic relationships; for instance, words with similar meanings are placed closer together in the vector space.
Techniques to generate these embeddings vary, with methods like Word2Vec, GloVe and more recently advanced transformer models like BERT and GPT from OpenAI. Each technique employs different algorithms to analyze text corpora and learn representations that reflect the context and usage patterns of words or phrases. Embeddings are instrumental in bridging the gap between human language and machine understanding, providing a foundation for numerous applications in AI, from chatbots to content recommendation systems.
Let’s create some text embeddings using SingleStore Notebooks and embedding models from OpenAI, Cohere and HuggingFace.
Once you sign up, click on the Develop tab to get started with Notebooks.
Never used Notebooks? Sign up for your free SingleStore trial to get started.

The Develop tab has options like SQL Editor, Kai Shell and Notebooks.

Click on Notebooks to create a new Notebook.

Launch AI-driven features. Without hitting limits.
- Free to start.
- Start building in minutes.
- Run transactions, analytics & AI.
OpenAI embeddings with ada-002
You'll need to have an OpenAI API key to use their models. Install the OpenAI Python package if you haven't already.

Next, import the required libraries and mention the OpenAI API key.

Mention the OpeAI API key

Use OpenAI’s format to generate text embeddings.
1def generate_embeddings(text):2 headers = {3 "Authorization": f"Bearer {api_key}",4 "Content-Type": "application/json"5 }6 7 data = {8 "input": text,9 "model": "text-embedding-ada-002",10 "encoding_format": "float"11 }12 13 response = requests.post("https://api.openai.com/v1/embeddings", headers=headers, data=json.dumps(data))14 return response.json()
Mention the text you would like to convert as embeddings. Let’s use the text ‘Pavan is a developer evangelist’ as input.
1text = "Pavan is a developer evangelist"2embeddings = generate_embeddings(text)3print(embeddings)
What you see here are the vector embeddings for the text ‘Pavan is a developer evangelist.' Similarly, we can use Cohere and HuggingFace to convert our text into embeddings.
Creating embeddings using Cohere
1!pip install cohere
Go to the Cohere website and get the API key (it is free) and mention it as shown here in your Notebooks.
1import cohere2co = cohere.Client('add your cohere api key')3 4response = co.embed(5 texts=['Pavan is a developer evangelist'],6 model='embed-english-v3.0',7 input_type='classification'8)9print(response)
Creating embeddings using HuggingFace
Like I said before, you can also create embeddings with HuggingFace. Start with installing the required libraries.
1!pip install transformers torch
Next, add the following code to create embeddings from HuggingFace and run:
1from transformers import AutoTokenizer, AutoModel2import torch3 4def get_huggingface_embedding(text, model_name='sentence-transformers/all-MiniLM-L6-v2'):5 tokenizer = AutoTokenizer.from_pretrained(model_name)6 model = AutoModel.from_pretrained(model_name)7 8 inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)9 with torch.no_grad():10 outputs = model(**inputs)11 12 # You can choose how to derive the final embeddings, e.g., mean pooling13 embeddings = outputs.last_hidden_state.mean(dim=1).squeeze().numpy()14 return embeddings15 16# Example usage17text = "Pavan is a developer evangelist."18embedding_huggingface = get_huggingface_embedding(text)19print(embedding_huggingface)
You can find the entire Notebook code in my GitHub repository.
Once you create your embeddings, you need to store them, right? You can easily store your vector embeddings in the SingleStore database. For this you need to create a workspace first, then a database under your workspace.

Once you create a workspace, it is easy to clear a database with just one click.

Now, let’s store our vector embeddings in the database we just created. I have created a database with the name ‘embeddings’ (as you can see in the preceding image).
Go to the SQL Editor from the Develop tab.

Select your workspace and the database from the dropdown. Let’s create a table to store our vector embeddings. As you can see, my table name is ‘vectortable’.

Let’s run the following code to store our embeddings into our table ‘vectortable’
1INSERT INTO vectortable (text, vector) VALUES ("your text", JSON_ARRAY_PACK("add the embeddings"))
In “your text,” add the text you converted into vector embeddings. In “add the embeddings,” add the corresponding embeddings.

Let’s go back to our database and the table we created, and confirm that our embeddings have been stored.

This way, you can create your vector embeddings and store them in SingleStore. Also to extend this, we can also do Indexed approximate-nearest-neighbor (ANN) search and much more. In the next blog, we will also show you how to do indexed ANN search with SingleStore.
Vector embeddings are an indispensable tool in machine learning and data science, offering a sophisticated means to represent and process data across various domains. Despite their challenges, the continuous development in embedding techniques and models promises to address these issues — broadening the scope of their application and effectiveness.
As we move forward, the exploration of embeddings will likely unveil even more innovative ways to capture the complexities of the world in the concise language of vectors.
Get started with SingleStore — including our brand new Free Shared Tier — today!



.png?width=24&disable=upscale&auto=webp)




