
AI systems have evolved so much that anyone can build highly agentic autonomous systems with no-code or low-code platforms/tools. We have come a long way from LLM chatbots to RAG systems to AI agents, but still there is one challenge that persists: context. LLMs are only as good as the information they have at the moment of reasoning. Without the right data, tools and signals, they hallucinate, make poor decisions or simply fail to execute reliably. Your AI systems should be equipped with proper context so that they are highly efficient and deliver value. This is where Context Engineering emerges as a discipline to optimally provide the right context at the right time to your AI systems.

In this article, we’ll dig deeper into the world of context engineering and understand everything about it. Let’s get started.
What is context engineering?
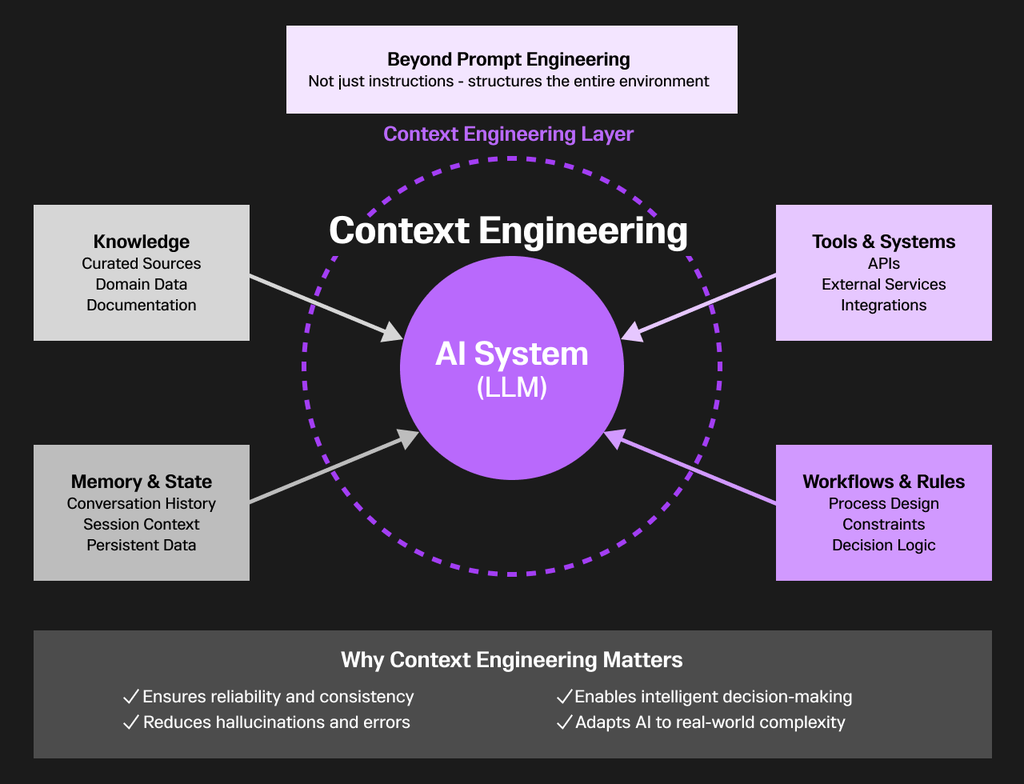
Unlike prompt engineering, which focuses mainly on crafting clever instructions for LLMs, context engineering is the systematic discipline of designing and optimizing the surrounding environment in which AI systems operate. It goes beyond prompts to carefully structure the data, tools, information and workflows that maintain the overall context for an AI system. By doing so, context engineering ensures that tasks are executed not just creatively, but reliably, consistently and intelligently.
At its core, context engineering acknowledges that an LLM by itself knows nothing relevant about a task. Its effectiveness depends on the quality and completeness of the context it receives. This involves curating the right knowledge sources, integrating external systems, maintaining memory across interactions, and aligning tools so the AI agent always has access to what it needs, when it needs it. Small gaps in context can lead to drastically different outcomes — errors, contradictions or hallucinations.
That’s why context engineering is emerging as one of the most critical practices in building robust AI applications. It’s not just about telling the model what to do; it’s about setting up the stage, the rules and the resources so the AI can make better decisions, reason effectively and adapt to real-world complexity.
Prompt engineering vs. context engineering
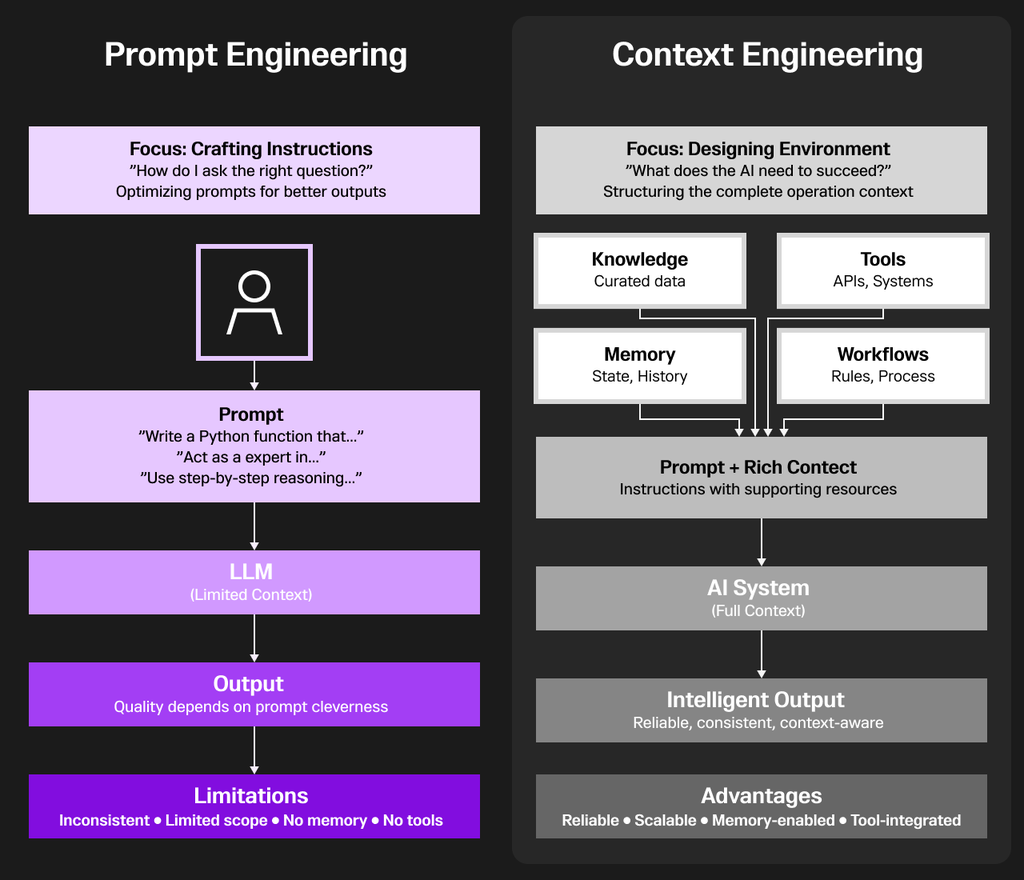
Context engineering is fundamentally superior to prompt engineering because it addresses the core limitation of AI systems: they only know what you give them.Prompt engineering is like giving someone instructions without any background information, tools or reference materials. You're constantly trying to cram everything into a single question, hoping the AI remembers enough to answer correctly. It's unreliable — the same prompt can produce different results, and there's no way to maintain consistency across interactions or access real-time data.
Context engineering treats the AI as part of a complete system. Instead of relying on clever wording, you architect the entire environment: you integrate knowledge databases so the AI accesses accurate information, connect external tools and APIs so it can perform real actions, implement memory systems so it remembers previous interactions, and establish workflows that ensure consistent, predictable behavior.
The difference is profound. Prompt engineering is about asking better questions. Context engineering is about building better systems. One produces occasionally impressive outputs; the other creates reliable, production-ready applications.
Small gaps in context lead to hallucinations, errors and failures. Context engineering eliminates these gaps systematically, ensuring the AI always has what it needs to make intelligent decisions and deliver consistent results in real-world applications.
RAG vs. context engineering
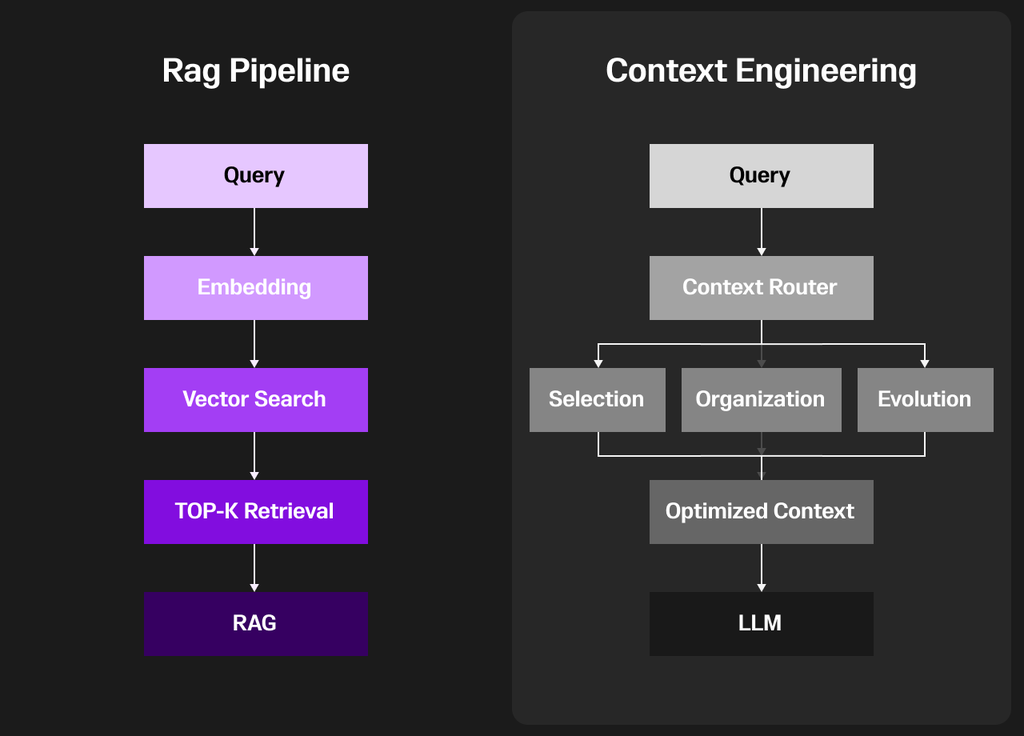
The RAG pipeline starts with a query from the user. That query is transformed into an embedding, a vector representation that captures semantic meaning. The system then performs a vector search across a knowledge base to find the most relevant pieces of information. Using Top-K retrieval, it selects a handful of the most similar results. These are then “stuffed into context” and fed into the LLM (Large Language Model). While this approach enriches the model with external knowledge, it is often rigid — relying heavily on similarity search and lacking adaptability in how context is used.
On the right, context engineering builds on this idea but adds sophistication. After the query, it introduces a context router that decides how best to process and route the information. This router supports three key processes: selection (choosing the most relevant pieces), organization (structuring information logically), and evolution (adapting and improving context dynamically). These steps produce an optimized context, which is then passed to the LLM.
The difference is clear: RAG fetches and dumps context, while context engineering curates, structures and evolves it, leading to more accurate, reliable and contextually aligned outputs.
The Role of MCP in Context Engineering
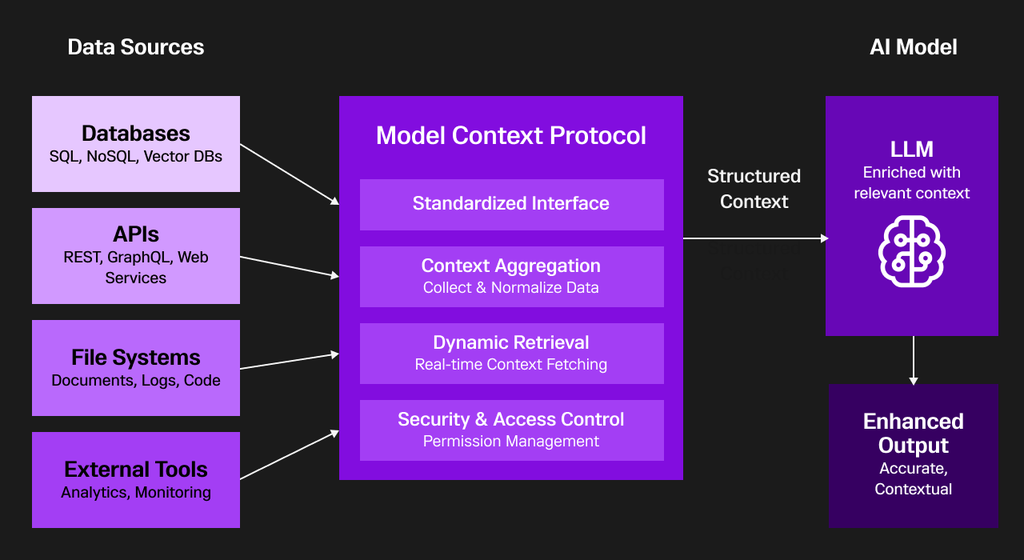
Model context protocol (MCP) has been the talk of the town for AI applications as a universal USB to plug & play with any tools & data sources. Instead of working with every API, MCP helps you manage everything in one place. The MCP serves as a critical foundation in context engineering, acting as a standardized intermediary between diverse data sources and AI models to deliver structured, actionable context for intelligent applications. MCP eliminates the complexity of bespoke integrations by providing a universal interface for databases (such as SQL, NoSQL, and vector stores), APIs, file systems, and external analytics tools. Through its four essential capabilities—standardized interface, context aggregation, dynamic retrieval, and security—MCP seamlessly collects, normalizes, and governs real-time data flow from multiple systems.
Within context engineering, MCP enables dynamic context elicitation: it fetches, assembles, and secures relevant information tailored to the AI model’s current intent or task, vastly improving response relevance and grounding output in real, up-to-date enterprise knowledge. Developers utilize MCP servers to expose organization-specific data and permissions, while AI agents (such as LLMs) connect through MCP clients to intake context in machine-understandable formats, respond to user queries, and adapt outputs based on the latest data.
SingleStore exemplifies the practical power of MCP in AI workflows. Its MCP server bridges LLMs and SingleStore’s high-performance databases, enabling natural language queries, workspace management, SQL execution, and even schema visualization—directly via AI assistants like Claude or development tools. The SingleStore MCP server authenticates with enterprise databases, manages user-specific sessions, enforces access control, and provides seamless, context-rich interactions for both operational and analytical tasks—making it a flagship implementation of context engineering in modern enterprise AI.
Building context-aware workflows with SingleStore

The diagram illustrates a simplified context engineering workflow built around SingleStore as the long-term memory layer. It begins with the user input, which serves as the query or problem statement. The system then performs retrieval and assembly, where relevant context is fetched from SingleStore using vector search and combined with short-term memory such as recent chat history to build a complete, context-rich prompt. This enhanced prompt is then passed to the LLM or AI agent, which processes it, performs reasoning and optionally executes external tool calls to generate a coherent, informed response.
The final stage is write-back memory, where the generated answer, conversation insights and any new knowledge are stored back into SingleStore. This ensures that every new interaction strengthens the system’s contextual understanding over time. The result is a self-improving, context-aware workflow — the essence of context engineering in action.
Context-aware tutorial with SingleStore
Go to SingleStore, create a workspace and a database to hold the context.
1pip install openai langchain langchain-community langchain-openai singlestoredb --quiet
1from langchain_openai import OpenAIEmbeddings # works after installing langchain-openai2from langchain_community.vectorstores import SingleStoreDB3from openai import OpenAI
1SINGLESTORE_HOST = "Add host URL" # your host2SINGLESTORE_USER = "admin" # your user3SINGLESTORE_PASSWORD = "Add your SingleStore DB password" # your password4SINGLESTORE_DATABASE = "context_engineering" # your database5OPENAI_API_KEY = "Add your OpenAI API key"
1connection_string = f"mysql://{SINGLESTORE_USER}:{SINGLESTORE_PASSWORD}@{SINGLESTORE_HOST}:3306/{SINGLESTORE_DATABASE}"
1embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)2client = OpenAI(api_key=OPENAI_API_KEY)
1from langchain_community.vectorstores import SingleStoreDB2from langchain_openai import OpenAIEmbeddings3 4embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)5 6vectorstore = SingleStoreDB(7 embedding=embeddings,8 table_name="context_memory",9 host=SINGLESTORE_HOST,10 user=SINGLESTORE_USER,11 password=SINGLESTORE_PASSWORD,12 database=SINGLESTORE_DATABASE,13 port=330614)
1docs = [2 {"id": "1", "text": "SingleStore unifies SQL and vector search in a single engine."},3 {"id": "2", "text": "Context engineering ensures AI agents always have the right context at the right time."},4 {"id": "3", "text": "SingleStore is ideal for real-time RAG pipelines due to low-latency queries."}5]6 7# Insert into vector DB8vectorstore.add_texts([d["text"] for d in docs], ids=[d["id"] for d in docs])9print("✅ Knowledge inserted into SingleStore")
1query = "Why is SingleStore useful for context engineering?"2results = vectorstore.similarity_search(query, k=2)3 4print("🔹 Retrieved Context:")5for r in results:6 print("-", r.page_content)
1from openai import OpenAI2client = OpenAI(api_key=OPENAI_API_KEY)3 4user_input = "Explain context engineering using SingleStore."5 6context = "\n".join([r.page_content for r in results])7 8prompt = f"""9You are a helpful AI agent.10User asked: {user_input}11Relevant context from memory:12{context}13"""14 15response = client.chat.completions.create(16 model="gpt-4o-mini",17 messages=[{"role": "user", "content": prompt}]18)19 20print("🔹 Agent Answer:\n", response.choices[0].message.content)
1vectorstore.add_texts([2 f"User: {user_input}", 3 f"Assistant: {response.choices[0].message.content}"4])5 6 7print("✅ Conversation stored back into SingleStore for future retrieval")
1followup_query = "What did we discuss earlier about context engineering?"2followup_results = vectorstore.similarity_search(followup_query, k=3)3 4print("🔹 Follow-up Retrieved Context:")5for r in followup_results:6 print("-", r.page_content)
The complete notebook code is present in this GitHub repository.
The future belongs to context-driven AI
As AI systems become more capable, the real differentiator won’t be bigger models — it will be better context. The ability to deliver the right data, at the right time, in the right format will define how useful and reliable AI truly becomes. Context engineering transforms isolated LLMs into intelligent systems that understand, remember and act with purpose.
By embracing this discipline, developers can move beyond clever prompts and instead build context-aware ecosystems where memory, reasoning and execution work in harmony. Frameworks like LangChain and databases like SingleStore make this vision practical — offering unified storage, hybrid search and high-speed retrieval that bring context to life.
In short, context engineering isn’t just a new buzzword — it’s the backbone of the next generation of AI. The sooner we master it, the closer we get to building AI systems that don’t just respond, but truly understand.
Frequently Asked Questions



-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)




