



Note: This is a preview feature that you can request access through Get Early Access
Python and data are inseparable in today's analytics landscape. We're excited to announce a game-changing feature that brings them closer together than ever before: Python User-Defined Functions (UDFs) for SingleStore. This powerful new capability lets you write and execute Python code directly within your SingleStore database, eliminating data movement and bridging the worlds of data storage and advanced analytics.
Extending SingleStore with Python's analytical power
Python UDFs allow you to define custom functions in Python that can be called directly from SingleStore SQL queries. This seamlessly extends SingleStore's native functionality with Python's extensive ecosystem of data processing and machine learning libraries, all while maintaining the security, performance and scalability you expect from SingleStore.
Why Python UDFs matter
This integration addresses several key challenges in modern data architecture:
Bridges the SQL-Python gap. Allows data teams to leverage both technologies without compromise
Eliminates data movement. Reduces latency and security concerns by keeping computation close to data
Empowers data scientists: Lets Python specialists work with database data without learning complex SQL
Simplifies architecture. Consolidates data pipelines by removing the need for separate Python processing services
Democratise access to complex domain logic through simple SQL functions calls greatly improving user experience
Enables advanced analytics. Brings cutting-edge ML and statistical techniques directly to your database
Getting started
Python UDFs strike a balance between the performance and security of SQL, and the flexibility and extensive libraries of Python. We've designed the implementation to be secure, performant and easy to use for both SQL experts and Python enthusiasts.
The feature will be available in our upcoming release, with support for common Python data science libraries out of the box. Stay tuned for detailed documentation and tutorials to help you leverage this powerful new capability.
How to work with Python UDFs
Python UDFs in SingleStore are designed to be intuitive for both database administrators and data scientists.
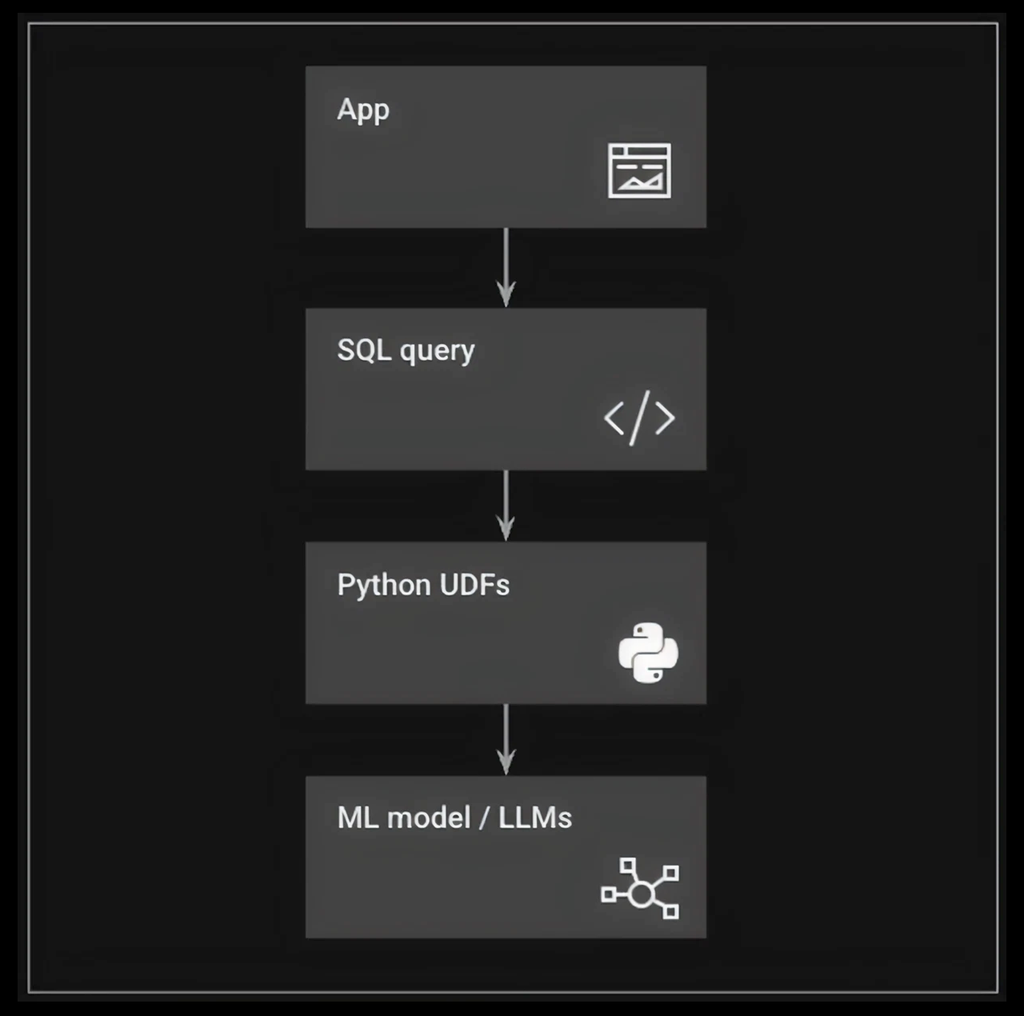
Creating a Python UDF from a new empty notebook
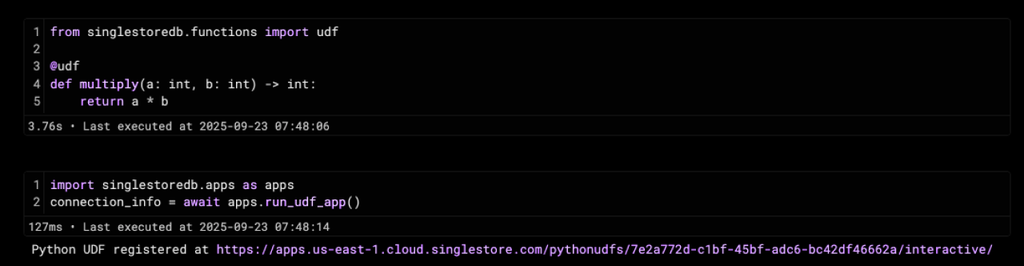
Open an empty shared notebook and in an empty notebook cell, import the needed library and then using a simple@udfdecorator syntax annotate a python function that you want registered as a Python user defined function as shown below:
1from singlestoredb.functions import udf2 3@udf4def multiply(a: int, b: int) -> int:5 return a * b
Publishing the Python UDF
After defining any additional UDFs, add the following boilerplate code at the end of the notebook that registers the UDF in the selected current database
1import singlestoredb.apps as apps2connection_info = await apps.run_udf_app(replace_existing=True)
You can either Run All the cells in the current notebook to register the UDFs in interactive Notebook mode
For testing purpose create a dummy table and populate with data for testing python UDFs
1DROP TABLE IF EXISTS products; 2 3CREATE TABLE IF NOT EXISTS products (4 product_id INT PRIMARY KEY,5 quantity INT,6 price DECIMAL(10, 2)7);8 9INSERT INTO products (product_id, quantity, price) VALUES10(1, 2, 150.00),11(2, 4, 20.00),12(3, 6, 60.00),13(4, 1, 300.00),14(5, 5, 100.00)
Using Python UDFs in SQL Editor / SQL cell in a notebook
PythonUDFs are registered as external functions and you can view all available external functions
1SHOW functions;
Note the python UDFs registered by running interactive notebooks have suffix _test to differentiate them from production ready UDFs. These functions after testing can be dropped and cleared. You can use your Python function in SQL queries just like any built-in function
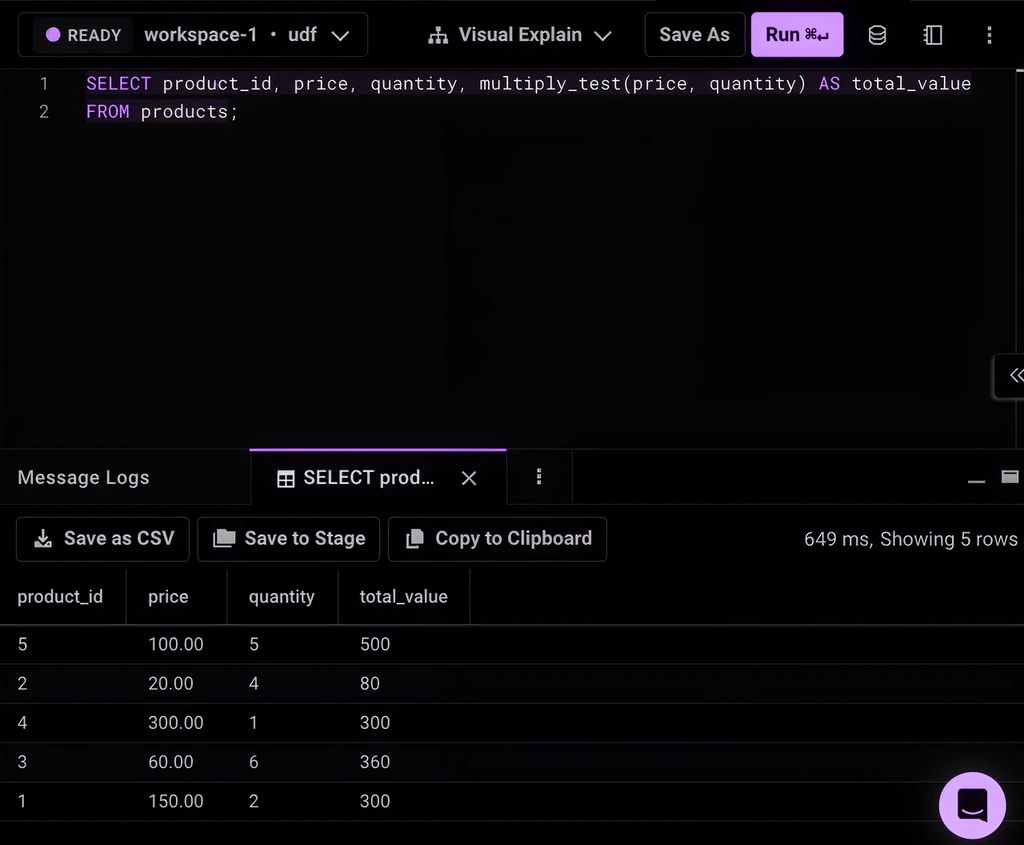
Publishing a Python UDF for production use
Once you are satisfied with the interactive notebook published UDF , you can hit publish to publish a production version of python UDF that persists and is served through a serverless Aura container for use in SQL editor and workflows.
Note that after publishing the python UDF you can run queries in SQL editor like:
1SELECT product_id, price, quantity, multiply(price, quantity) AS total_value2FROM orders;
Start from a template
Alternatively you can start with a predefined template right from the Notebook creation dialog.
Performance optimized for data processing
Understanding that Python performance can be a concern when processing large datasets, we've built two powerful options:
Scalar UDFs. Process data row by row (great for complex logic on individual records)
Vectorized UDFs. Process data in batches using NumPy, Pandas or other vector operations (perfect for high-performance numerical processing)
We have extensive documentation available with more in depth examples on how you can use Python UDFs for your production workloads.
Real-world example use cases
Text analytics and NLP
Process and analyze text data using Python's rich NLP libraries right where your data lives:
1@udf2def sentiment_score(text: str) -> float:3 # Use a Python NLP library to analyze sentiment4 return sentiment_model.predict(text)
1@udf2def predict_churn(customer_age: int, purchase_frequency: float, 3 last_purchase_days: int) -> float:4 # Apply your pre-trained churn prediction model5 return churn_model.predict([[customer_age, purchase_frequency, last_purchase_days]])[0]
Vector embeddings for AI applications
Generate vector embeddings for semantic search or AI applications:
1@udf2def vectorize_text(text: str) -> bytes:3 # Convert text to embedding vector4 embedding = model.encode(text)5 return embedding
1@udf2def parse_complex_json(json_data: str) -> str:3 # Extract nested information from complex JSON4 data = json.loads(json_data)5 return process_nested_structure(data)
Just show me the code!!!
We have also made available a full notebook with code that you can directly import into your workspace. Try it out at: https://www.singlestore.com/spaces/run-your-first-python-udf
Conclusion
Python UDFs in SingleStore represent a significant step forward in our mission to make data processing more accessible, efficient and powerful. By bringing Python's analytical capabilities directly into the database, we're enabling new use cases and workflows that were previously difficult to implement.
We can't wait to see what you'll build with this powerful new capability!
Frequently Asked Questions










