

Today, we are happy to announce the preview of Stage in Singlestore Helios.
What Is Stage, and How Does It Help?
As you have likely experienced, loading files in a database is not always fun. Previously, loading a local file required you to use a local client, specify the schema of that file and do pipeline mapping. With Stage, you can load your file into a SingleStoreDB staging area attached to every Workspace Group to help you quickly get your data into SingleStoreDB.
Combined with schema inference, we speed up the process of creating the table and pipeline mapping. So now, it should only take seconds to load your files into SingleStoreDB.
You can also export results from a query into Stage. You can then share data with other users having access to that specific Stage or download large result files locally in your machine. Stages supports CSV, parquet, avro, JSON and compressed formats like gz.
Follow along as I walk you through a step-by-step process of getting your files into SingleStoreDB:
Import a file
Let’s get a file from Kaggle. For this example, we’re using US historical stock prices with earnings data.
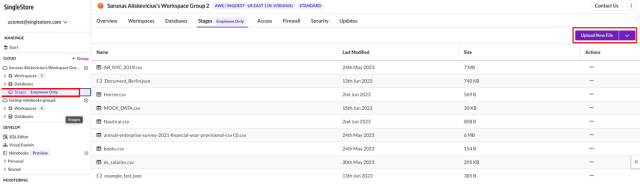
Click on Stages
- Select Upload New File
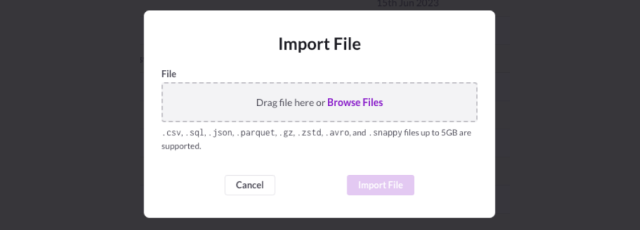
- Select Browse Files
- Select the file. In this case, you select dataset_summary.csv
Now, the file is imported into Stage.
Load a file into a database
- Select Load To Database

- In the load data screen, select your workspace, pick a database and edit the Table name (if needed).
We’ve created a notebook with pipelines, so you can edit or tweak if you are not satisfied with the definitions provided. Let me go over the sections of the notebook:
- We define the table schema, and create the default table with Universal Store (rowstore + columnstore)
- We define the pipeline
- We start the pipeline
- We monitor the pipeline in case of errors or warnings
- The final step is to check that the results are loaded correctly
Check That the Data Has Loaded
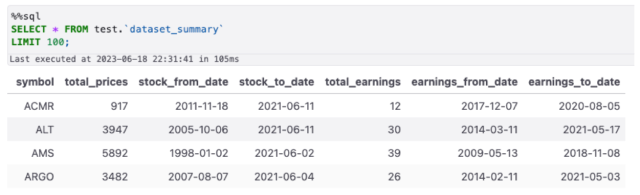
You can run all cells at once — but you might have to rerun the last cell a second time to see the results.
Export Query Results Into Stage
Now that the data has been loaded in the table, let’s do the reverse and export the results of a query to Stage. We will only select stocks with more than 40 earnings, and save the output into Stage as JSON. To avoid having multiple files from each leaf node, you need to use group by 1.
select * from test.dataset_summary where total_earnings > 40
group by 1
into stage 'stock_earnings.csv;Wrap-Up
That’s it! This is just the beginning for Stage, as we will integrate the notebook experience (import libraries, export to stage from dataframe, etc.) to let people create folders and start organizing their data for easily ingested more than just one file.
Stay tuned!

















.jpg?width=24&disable=upscale&auto=webp)

