

Whenever I am talking with customers or old colleagues looking to migrate an on-prem database to cloud using SingleStore, I regularly hear a few questions: What objects are available in the new platform? And which different table types are available, and what are the advantages?
To make it easy, I’ve put together a blog series to summarize object types available in SingleStore and answer those high-level questions — starting with part one.
First, a quick brief on SingleStore
SingleStoreDB is a distributed, relational database that handles both transactions and real-time analytics at scale. Benefitting both OLTP and OLAP workloads, it’s designed to run on on-prem systems, as well as major cloud systems like AWS, Azure and GCP. SingleStore is ANSI SQL-compatible and natively supports structured, semi-structured and unstructured data. The SingleStore database maintains broad compatibility with common technologies in the modern data processing ecosystem like orchestration platforms, developer IDEs and BI tools — and powers data-intensive applications.
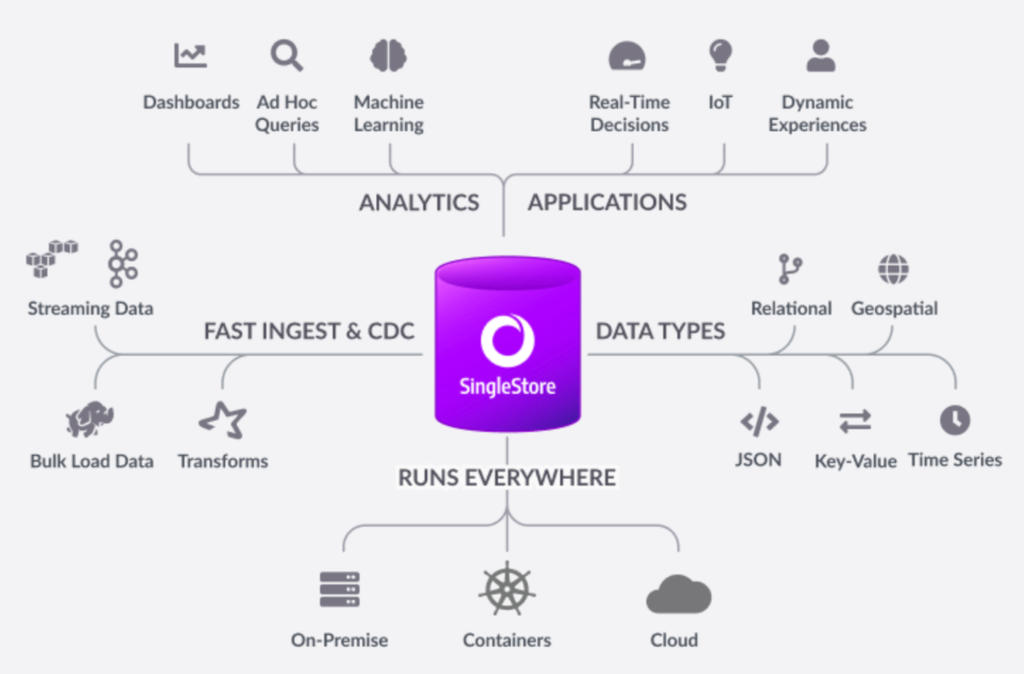
Objects in SingleStore
Objects are nothing but a data structure, used to store or reference data in SQL queries. Developers, applications or queries interact with tables and/or views. Likewise, other objects include indexes, stored procedures and functions. Here, I will walk through objects in SingleStore.
Database: The first object you need to create in a SingleStore cluster is a database. Database is a collection of other objects like tables, views, stored procedures, etc. By default, object names are case-sensitive in SingleStore. The engine variable table_name_case_sensitivity defines the case sensitivity of a database object. When this variable is set to ON (the default setting), all database objects are case-sensitive, except:
- Stored procedures
- User-defined scalar-valued functions (UDFs)
- User-defined aggregate functions (UDAFs)
- information_schema table names
You can only change the setting of the variable table_name_case_sensitivity when the cluster is empty — that is, the cluster must contain no user databases.
Tables: SingleStore helps customers store data in different physical storages, which delivers a variety of performance benefits. Different table types we’ll explore are:
- Rowstore table
- Columnstore table
- Reference table
- Temporary table
- Global temporary table
Rowstore table: Most relational databases use row-oriented stores, or row stores. As the name indicates, a row/tuples are stored in a table as a single unit. This means it stores all fields for a given row together in the same physical location. This makes rowstores great for transactional workloads, where the database frequently selects, inserts, updates and deletes individual rows, often referencing either most or all columns. In SingleStore, the rowstore table gets stored in a memory of leaf nodes. So it is important to reserve a reasonable amount of RAM on leaf nodes. For applications doing OLTP-type work, (small inserts, updates and deletes), rowstore performs much better than columnstore.
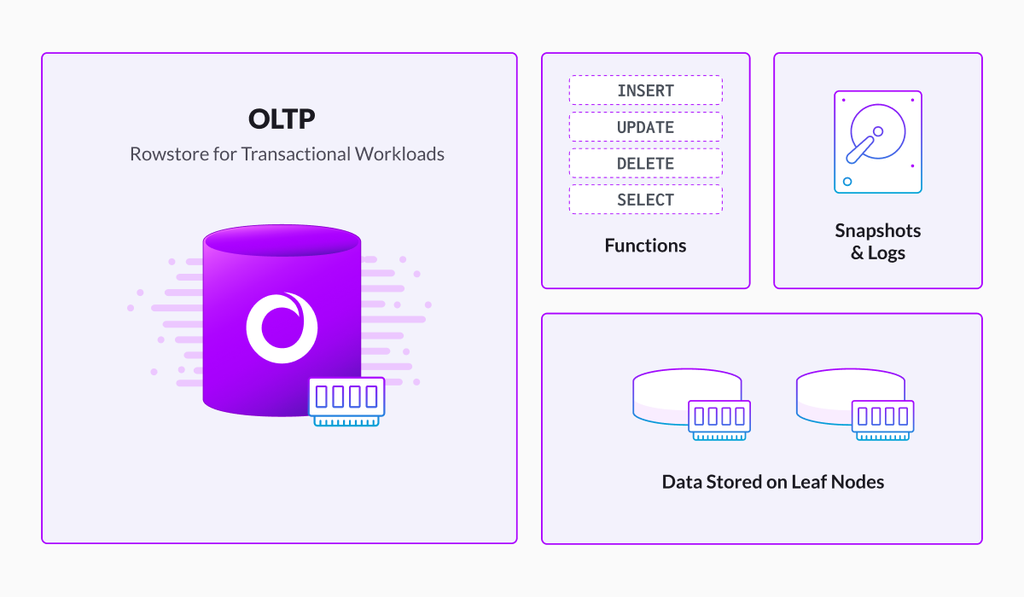
Here is an example of a statement that creates a rowstore table:
CREATE ROWSTORE TABLE products (
ProductId INT,
Color VARCHAR(10),
Price INT,
dt DATETIME,
KEY (Price),
SHARD KEY (ProductId)
);
You can find more information on understanding SHARD KEY selection here.
Columnstore table: Columnstore is a default table type in SingleStore. Columnstore stores data on disk, stores each column as a single unit and stores segments of data for each column together in the same physical location. This helps when queries are referencing a few columns in a table. It will only scan columns, which are needed or specified in a query. Another important benefit of columnstores is they lend themselves well to compression.
When creating a columnstore index, one or more columns need to be defined as the key column(s) for the columnstore index, aka SORT KEY. The data in the columnstore is stored in key column order.
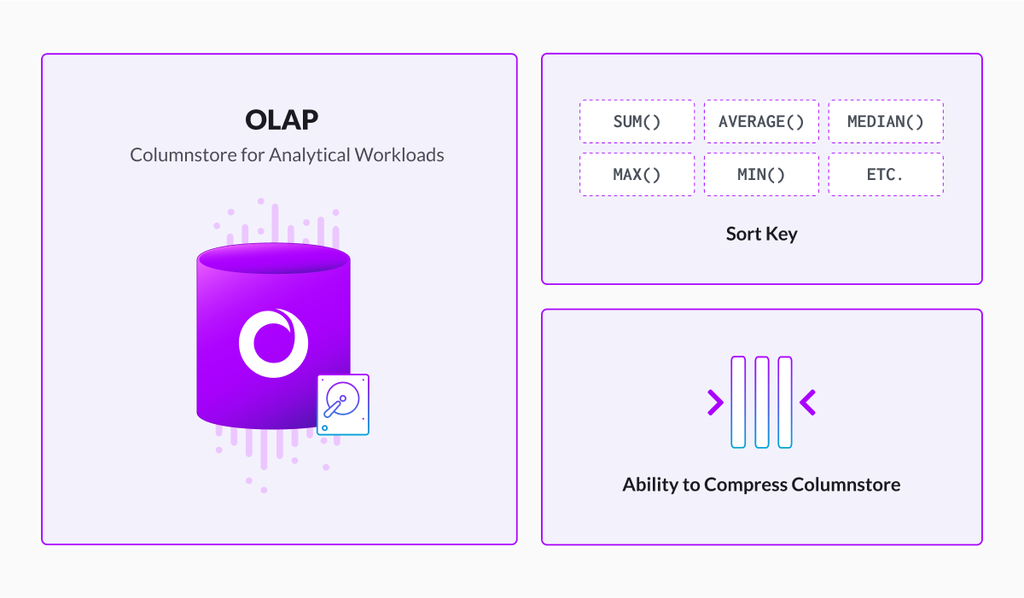
CREATE TABLE sales(
productId bigint null,
timeId int null,
customerId bigint null,
promotionId int null,
storeId int null,
storeSales decimal(12,2) null,
storeCost decimal(12,2) null,
unitSales decimal(12,2) null,
SORT KEY(timeId)
);
DML/Write operations in columnstore: SingleStore supports very fast, small-batch writes directly into columnstore tables. INSERT into the columnstore table, write first into the rowstore-backed memory and then write it to the disk. This makes INSERT performance fast. Deleting a row in a columnstore causes the row to be marked as deleted in the segment metadata, leaving the data in place within the row segment. Segments that only contain deleted rows are removed, and the optimization process covered here will compact segments that require optimization. An UPDATE in a columnstore is internally performed as a delete, followed by an insert within a transaction.
The following table enumerates the strengths and intended uses of the rowstore and columnstore:
| Rowstore (In memory) | Columnstore (On disk) |
|---|---|
| Operational/transactional workloads | Analytical workloads |
| Fast inserts and updates over a small or large number of rows | Fast inserts over a small or large number of rows |
| Random seek performance | Fast aggregations and table scans |
| Updates/deletes are frequent | Updates/deletes are rare |
| Null compression (Sparse index) | Compression |
Looking for more? Find out if a rowstore or columnstore is right for your use case.
Reference table: I am sure that most of you have seen run-time data distribution for JOIN operations. This happens when we don't have JOIN conditions on indexes. The best option in SingleStore is the Reference table. Reference tables are replicated on every node in the cluster, eliminating the need to transfer data across the network during query execution. Reference tables are best for relatively small tables that rarely change, because the write operation on reference tables consumes a lot more resources. In general, reference tables are a convenient way to implement dimension tables. You can read more about it here. Reference tables can be created as a rowstore, as well as a columnstore. Here are sample DDLs:
/* Columnstore reference table */
CREATE REFERENCE TABLE region(
regionId int,
salesCity nvarchar(50),
salesStateProvince nvarchar(50),
salesRegion nvarchar(50),
salesCountry nvarchar(50),
salesDistrictId int,
key(salesDistrictId) using clustered columnstore
);
/* Rowstore reference table */
CREATE REFERENCE TABLE productLine(
productLineId int primary key not null,
productLineName varchar(50) not null,
textDescription text not null,
image blob not null
);
Temporary tables: As the name suggests, these tables are temporarily created and exist for the duration of a client session. These tables cannot be queried by other users, and are dropped once the connection has ended. They can also be dropped manually without removing the connection. Temporary tables can be created as columnstore or rowstore tables. SingleStoreDB does not write logs or take snapshots of temporary tables.
Temporary tables are designed for temporary, intermediate computations. Since temporary tables are neither persisted nor replicated in SingleStoreDB, they have high availability disabled. This means that if a node in a cluster goes down and a failover occurs, all the temporary tables on the cluster lose data. It’s important to note that views cannot reference temporary tables.
CREATE TEMPORARY TABLE IF NOT EXISTS temp1 (id INT AUTO_INCREMENT
PRIMARY KEY, a INT, b INT, SHARD KEY(id));
CREATE ROWSTORE TEMPORARY TABLE IF NOT EXISTS temp1 (id INT
AUTO_INCREMENT PRIMARY KEY, a INT, b INT, SHARD KEY(id));
Global temporary tables: Another type of temporary table is the global temporary table. Global temporary tables are shared across sessions. This means these temporary tables exist beyond the duration of the session, and are not dropped automatically. These tables can be queried by other users as long as they have required privileges.
If failover occurs, global temporary tables lose data and enter an errored state — then need to be dropped and recreated. However, dropping a global or non-global temporary table does not drop its plancache from the disk, and retains the cache if the table is recreated with the same schema.
Note: Global temporary tables are only ROWSTORE tables.
CREATE ROWSTORE GLOBAL TEMPORARY TABLE IF NOT EXISTS temp4_gtt (id INT
AUTO_INCREMENT PRIMARY KEY, a INT, b INT, SHARD KEY(id));
Views: In a database, a view is the result set of a stored query in the data, which the database users can query just like they would in a persistent database collection object. This pre-established query command is kept in the database dictionary. Unlike ordinary base tables in a relational database, a view does not form part of the physical schema. Since it is a result set, it is a virtual table computed or dynamically collated from data in the database: Changes applied to the data in a relevant underlying table are reflected in the data shown in subsequent invocations of the view.
Views provide several advantages over tables, including:
- Representing a subset of the data contained in a table. Consequently, a view can limit the degree of exposure of the underlying tables to the outer world. Given users may have permission to query the view — but can still be denied access to the remaining base table.
- Joining and simplifying multiple tables into a single virtual table.
- Views can act as aggregated tables, where the database engine aggregates data (sum, average, etc.), presenting the final calculated results as part of the data.
- Hiding data complexities. For example, a view could appear as Sales2000 or Sales2001, transparently partitioning the actual underlying table.
- Views take very little space to store. That means the database contains only the definition of a view, not a copy of all the data that it presents.
- Depending on the SQL engine used, views can provide extra security.
Additional remarks regarding views:
- Views in SingleStoreDB are not writable. Attempts to INSERT, UPDATE or DELETE data in a view will result in an error.
- SingleStoreDB Self-Managed does not support MySQL’s CREATE OR REPLACE VIEW syntax. To modify an existing view, use ALTER VIEW.
- Views can reference views or tables from other databases.
- Any function (including CURRENT_USER() and NOW()) used in a view are evaluated during execution.
Stay tuned for part two of this series, where I’ll provide additional detail about indexes.
Interested in seeing how objects in SingleStore work? Try it out for free today.
.png?height=187&disable=upscale&auto=webp)
.png?width=24&disable=upscale&auto=webp)









