SingleStore Notebooks
New

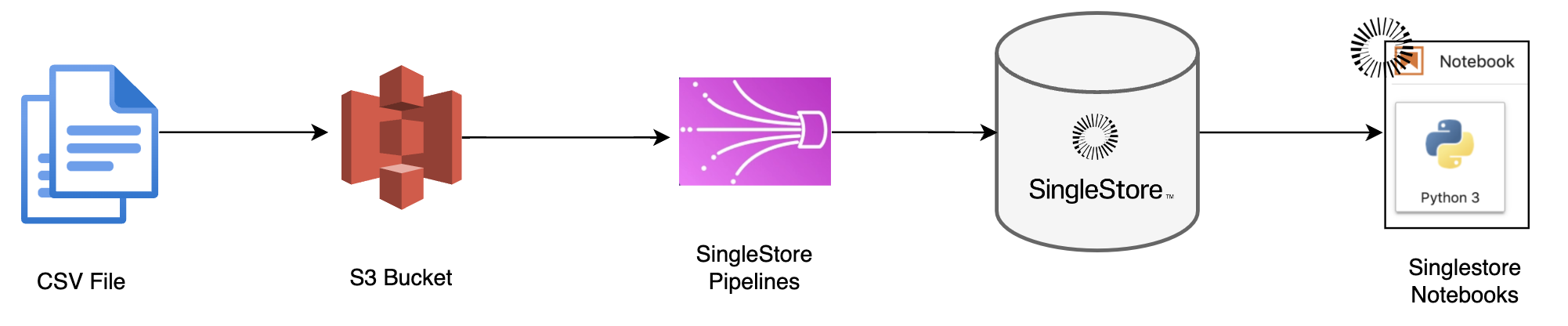

Importing Data from S3 into SingleStore using Pipelines
Notebook
Note
This notebook can be run on a Free Starter Workspace. To create a Free Starter Workspace navigate to Start using the left nav. You can also use your existing Standard or Premium workspace with this Notebook.
Input Credentials
Define the URL, REGION, ACCESS_KEY, and SECRET_ACCESS_KEY variables below for integration, replacing the placeholder values with your own.
In [1]:
1
URL = 's3://your-bucket-name/your-data-file.csv'2
REGION = 'your-region'3
ACCESS_KEY = 'access_key_id'4
SECRET_ACCESS_KEY = 'access_secret_key'
This notebook demonstrates how to create a sample table in SingleStore, set up a pipeline to import data from an Amazon S3 bucket, and run queries on the imported data. It is designed for users who want to integrate S3 data with SingleStore and explore the capabilities of pipelines for efficient data ingestion.
Pipeline Flow Illustration
Creating Table in SingleStore
Start by creating a table that will hold the data imported from S3.
In [2]:
1
%%sql2
/* Feel free to change table name and schema */3
4
CREATE TABLE IF NOT EXISTS my_table (5
id INT,6
name VARCHAR(255),7
age INT,8
address TEXT,9
created_at TIMESTAMP10
);
Create a Pipeline to Import Data from S3
You'll need to create a pipeline that pulls data from an S3 bucket into this table. This example assumes you have a CSV file in your S3 bucket.
Ensure that: You have access to the S3 bucket. Proper IAM roles or access keys are configured in SingleStore. The CSV file has a structure that matches the table schema.
Using these identifiers and keys, execute the following statement.
In [3]:
1
%%sql2
CREATE PIPELINE s3_import_pipeline3
AS LOAD DATA S3 '{{URL}}'4
CONFIG '{\"REGION\":\"{{REGION}}\"}'5
CREDENTIALS '{\"AWS_ACCESS_KEY_ID\": \"{{ACCESS_KEY}}\",6
\"AWS_SECRET_ACCESS_KEY\": \"{{SECRET_ACCESS_KEY}}\"}'7
INTO TABLE my_table8
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"'9
LINES TERMINATED BY '\n'10
IGNORE 1 lines;
Start the Pipeline
To start the pipeline and begin importing the data from the S3 bucket:
In [4]:
1
%%sql2
START PIPELINE s3_import_pipeline;
Select Data from the Table
Once the data has been imported, you can run a query to select it:
In [5]:
1
%%sql2
SELECT * FROM my_table LIMIT 10;
Check if all data of the data is loaded
In [6]:
1
%%sql2
SELECT count(*) FROM my_table
Conclusion
We have shown how to insert data from a Amazon S3 using Pipelines to SingleStoreDB. These techniques should enable you to
integrate your Amazon S3 with SingleStoreDB.
Clean up
Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created.
Drop Pipeline
In [7]:
1
%%sql2
#STOP PIPELINE s3_import_pipeline;3
4
#DROP PIPELINE s3_import_pipeline;
Drop Data
In [8]:
1
%%sql2
#DROP TABLE my_table;
Details
About this Template
This notebook demonstrates how to create a sample table in SingleStore, set up a pipeline to import data from an Amazon S3 bucket.
This Notebook can be run in Shared Tier, Standard and Enterprise deployments.
Tags
starterloaddatas3
License
This Notebook has been released under the Apache 2.0 open source license.
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.