

With the release of SingleStoreDB Self-Managed 6.5, the SingleStore team is announcing our latest innovation in data ingestion: Pipelines to stored procedures. By marrying the speed and exactly once semantics of SingleStore Pipelines with the flexibility and transactional guarantees of stored procedures, we’ve eliminated the need for complex transforms and unlocked the doors to a variety of new, groundbreaking use cases. This blog post will walk you through how to use Pipelines to stored procedures to break data streams up into multiple tables, join them with existing data, and update existing rows, but this is just the tip of the iceberg of what is possible with this exciting new functionality.
How Does it Work?
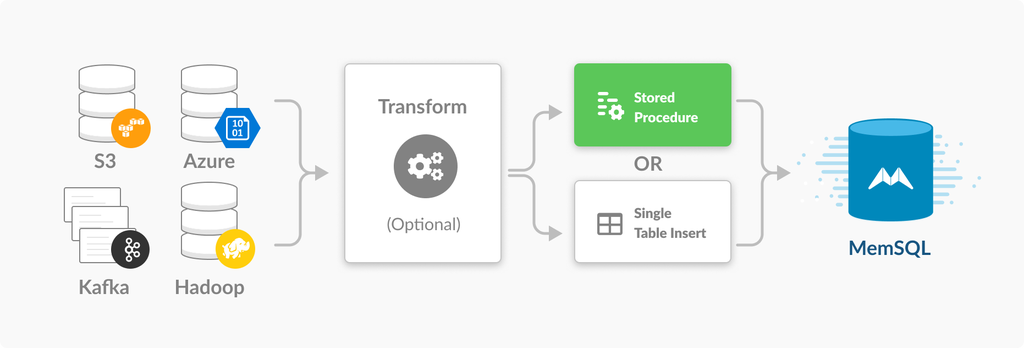
Pipelines to stored procedures augments the existing SingleStore Pipelines data flow by providing the option to replace the default Pipelines load phase with a stored procedure. The default Pipelines load phase only supports simple insertions into a single table, with the data being loaded either directly after extraction or following an optional transform. Replacing this default loading phase with a stored procedure opens up the possibility for much more complex processing, providing the ability to insert into multiple tables, enrich incoming streams using existing data, and leverage the full power of SingleStore Extensibility.
Pipelines Transforms vs. Stored Procedures
Those familiar with SingleStore Pipelines might be wondering, “I already have a transform in my pipeline….should I use a stored procedure instead?” Leveraging both a transform and a stored procedure in the same Pipeline allows you to combine the third-party library support of a traditional transform alongside the multi-insert and data-enrichment capabilities of a stored procedure.
| Traditional Transform | Stored Procedure |
|---|---|
| Pros - Can be written in any language (BASH, python, Go, etc.) - Can leverage third-party libraries - Easily portable to systems outside of SingleStore Cons - More difficult to debug and manage - Less performant for most use cases - Only allows inserting into a single table - No transactional guarantees | Pros - Insert into multiple tables - SingleStore native - High performance querying of existing SingleStore tables - Transactional guarantees Cons - SingleStore-specific language - No access to third-party libraries for more complex transformations |
Example Use Cases
Insert Into Multiple Tables
Pipelines to stored procedures now enables you to insert data from a single stream into multiple tables in SingleStore. Consider the following stored procedure:
CREATE PROCEDURE proc(batch query(tweet json))
AS
BEGIN
INSERT INTO tweets(tweet_id, user_id, text)
SELECT tweet::tweet_id, tweet::user_id, tweet::text
FROM batch;
INSERT INTO users(user_id, user_name)
SELECT tweet::user_id, tweet::user_name
FROM batch;
END
This procedure takes in tweet data in JSON format, separates out the tweet text from the user information, and inserts them into their respective tables in SingleStore. The entire stored procedure is wrapped in a single transaction, ensuring that data is never inserted into one table but not the other.
Load Into Table and Update Aggregation
There are many use cases where maintaining an aggregation table is a more performant and sensible alternative to running aggregation queries across raw data. Pipelines to stored procedures allows you to both insert raw data and update aggregation counters using data streamed from any Pipelines source. Consider the following stored procedure:
CREATE PROCEDURE proc(batch query(tweet json))
AS
BEGIN
INSERT INTO tweets(tweet_id, user_id, text)
SELECT tweet::tweet_id, tweet::user_id, tweet::text
FROM batch;
INSERT INTO retweets_counter(user_id, num_retweets)
SELECT tweet::retweeted_user_id, 1
FROM batch
ON DUPLICATE KEY UPDATE num_retweets = num_retweets + 1
WHERE tweet::retweeted_user_id is not null;
END
This procedure takes in tweet data as JSON, inserts the raw tweets into a “tweets” table, and updates a second table which tracks the number of retweets per user. Again, the transactional boundaries of the stored procedure ensures that the aggregations in retweets_counter are always in sync with the raw data in the tweets table.
Use Existing Data to Enrich a Stream
It’s also possible to use a stored procedure to enrich an incoming stream using data that already exists in SingleStore. Consider the following stored procedure, which uses an existing SingleStore table to join an incoming IP address batch with existing geo data about its location:
CREATE PROCEDURE proc(batch query(ip varchar, ...))
AS
BEGIN
INSERT INTO t
SELECT batch.*, ip_to_point_table.geopoint
FROM batch
JOIN ip_to_point_table
ON ip_prefix(ip) = ip_to_point_table.ip;
END
These use cases only scratch the surface of what is possible using Pipelines to stored procedures. By joining the speed of Pipelines with the flexibility of stored procedures, SingleStoreDB Self-Managed 6.5 gives you total control over all of your streaming data. For more information on the full capabilities of SingleStore Extensibility, please see our documentation.



.png?width=24&disable=upscale&auto=webp)








