

Microservices architectures have focused heavily on compute services, with data storage and retrieval – a crucial topic – sidelined, and left as an exercise for the developer. Crucially, Kubernetes did not include direct support for stateful services (ie, databases) initially. The Red Hat developers blog has suggested that data management is The Hardest Part About Microservices. In response, in this blog post, we suggest that a NewSQL database, such as SingleStore, can provide data services to multiple microservices implementations in a manageable way, simplifying the overall architecture and boosting performance.
There are many ways to tackle data needs for a microservices architecture. Because microservices architectures have such a strong following in the open source community, and because Kubernetes was slow to support stateful services such as databases, many architects and developers seem to assume several predicates:
- Every service in a microservices architecture will have its own data store
- Across data stores, data will be eventually consistent – not, well, consistently consistent (ie, not meeting ACID guarantees)
- The application developer will be responsible for managing data across services and for ultimate consistency.
But not every microservices thinker is ready to throw out the baby – the valuable role that can be played by a relational database – with the bathwater of a restriction to open source, and usually NoSQL, databases.
Kubernetes Operators and Microservices
Both the tools available for using databases with microservices, and the thinking that a developer can draw on when considering their options, are evolving. In the area of tools, Kubernetes has developed stateful services support. Additions such as PersistentVolume, PersistentVolumeClaim, and StatefulSet make these services workable. The emergence of Operators in the last few years makes it much, much easier to use Kubernetes for complex apps that include persistent data, as most apps do. (You can see the blog post that introduces, and explains, Operators here.)
You can learn how to build an Operator from Red Hat’s OpenShift site.
As an example, SingleStore has used Kubernetes to build and manage its, well, managed service, Singlestore Helios. After earlier attempts to develop such a service ran into difficulties, Kubernetes, and the development of a SingleStore Kubernetes Operator (in beta) by the team, made it possible for SingleStore to bring Singlestore Helios to market with just a few months of work by a few individuals. With an elastic, on-demand, cloud database as the very definition of a stateful service, this is just one example that the Kubernetes Operator, as well as Kubernetes as a whole, are fully ready for prime time.
New Thinking About the State (of Data)
Some daring thinkers – in one particular case, at RedHat – have focused on reminding their fellow developers of some of the advantages of a single, central, relational database, long taken for granted: ACID transactions; one place to find and update data, a single thing to manage, and a long history of research and development. The authors then go on to develop a primer on how best to share a relational data store among multiple services. In their sample, they use MySQL as the relational data store.
One microservices maven, Chris Richardson, offers both options. He gives robust descriptions of the use of both a database-per-service approach and a shared database approach in microservices development.
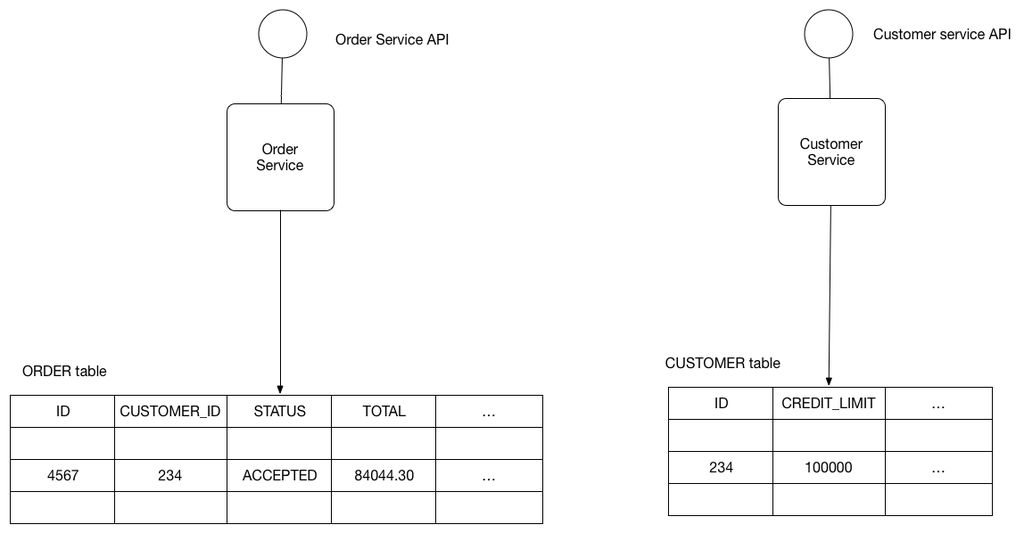
Microservices maven Chris Richardson describes varied
approaches to database access in microservices apps.
But RedHat’s reference to MySQL, as a venerable and widely used relational database, incidentally highlights one of the primary objections to the use of legacy relational databases for microservices development: their lack of scalability. Scalability is one of the chief, if not perhaps even the single most important, attributes of a microservices architecture. It’s so important that many microservices developers restrict themselves to NoSQL architectures, which assume scalability as an attribute, simply to avoid having to deal with artificial constraints on things like database size or transaction volume.
A Modest Proposal (for Microservices Data)
We would like to suggest here that SingleStore is a solid candidate for use as a shared relational database for microservices applications. This choice is not restrictive; specific services can still use local databases, and they can be of any type needed. But for complex operations such as transactions, and even for many incidental operations such as logging users, a relational database which can be shared or sectioned as needed, and used on a database-per-service database when that’s required, and that works well alongside NoSQL data stores, might be a valuable asset.
NewSQL databases in general, and SingleStore in particular, have the attributes needed to serve this role, including:
- Speed. SingleStore is very fast, for ingest, processing, and transaction responsiveness.
- Scalability. SingleStore retains its speed across arbitrarily large data sizes and concurrency demands, such as application queries.
- SQL support. Not only is the SQL standard ubiquitous, and therefore convenient, it’s also been long optimized for both speed and reliability.
- Multiple data types. SingleStore supports an unusually wide range of data types, for a relational, SQL database: relational data, JSON data, time series data, geospatial data, and can import in the AVRO format typically used in Kafka, as well as offering full-text search on data.
- Transactions plus analytics. SingleStore supports both transactions and analytics in a single database; you simply create rowstore tables for some data and columnstore tables for others. Also, with SingleStoreDB Self-Managed 7.0 having reached GA last December, you can now use Universal Storage features to depend more often on just one table type or the other.
- Cloud-native. SingleStore is truly cloud-native software that runs unchanged on-premises, on public cloud providers, in virtual machines, in containers, and anyplace you can run Linux. Singlestore Helios, which is itself built on Kubernetes, offers a managed service, reducing operational cost and complexity.
While SingleStore has other features that are beneficial in any context, these are the key features that stand out the most in a microservices environment.
Getting Started
SingleStore offers free use of the software for an unlimited time, within a generous footprint limit, and with community support, rather than a support restriction. You can typically run an entire proof of concept on SingleStore before you are likely to need to scale up enough to purchase an Enterprise license. So we suggest that you try SingleStore for free, and get started with your next big project, today.












