

You run a database. You try to anticipate the future. You try to provide sufficient, even generous, resources to accommodate future growth in your service. But sometimes, growth far exceeds even your most optimistic expectations, and now you have to figure out how to accommodate that.
One obvious way of increasing your database’s ability to handle and service more data is to simply add more machines to your cluster. That should increase the number of cores, and the amounts of memory and disk space available in your cluster. But with a limited number of partitions, at some point, adding the number of cores and memory and disk won’t be able to increase the parallelism and breadth of your database.
Since partitions cannot span leaves, you cannot share data storage and processing between N leaves unless you have at least N partitions. Additionally, parallel query performance will be best when we have one or two cores per partition.
Therefore, it would seem that being able to increase the number of partitions among which the data is spread out is critical for the cluster’s scalability. Until now, however, there has not been an easy and convenient way to do this in SingleStore.
Introducing Backup with Split Partitions
In order to split the number of partitions in your database, we’ve come up with a clever strategy that adds partition splitting to the work of a backup operation. Normally, a full backup will create one backup for each partition database, with a .backup file for the snapshots of the rowstore portion of data, and a .backup_columns_num_tar file, or files, for the columnstore blobs of the partition. There is also rowstore backup for the reference database and a BACKUP_COMPLETE file for a completed backup.
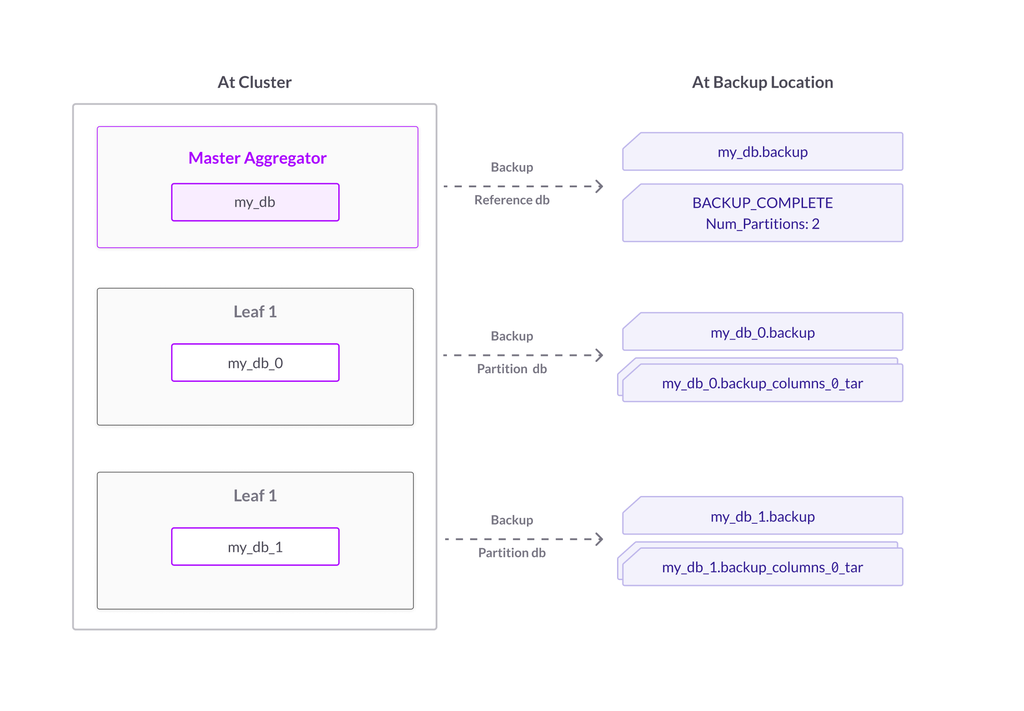
Figure 1. Normal backup – no split partitions
But for splitting partitions, each partition will actually generate backup files for two partitions – each of these split partitions will have the data required to create half of the original partition upon a restore. A multi-step hash function determines which of the new split partitions any row in the original partition should belong to, and this function splits all rows between the new split partitions in the backup.
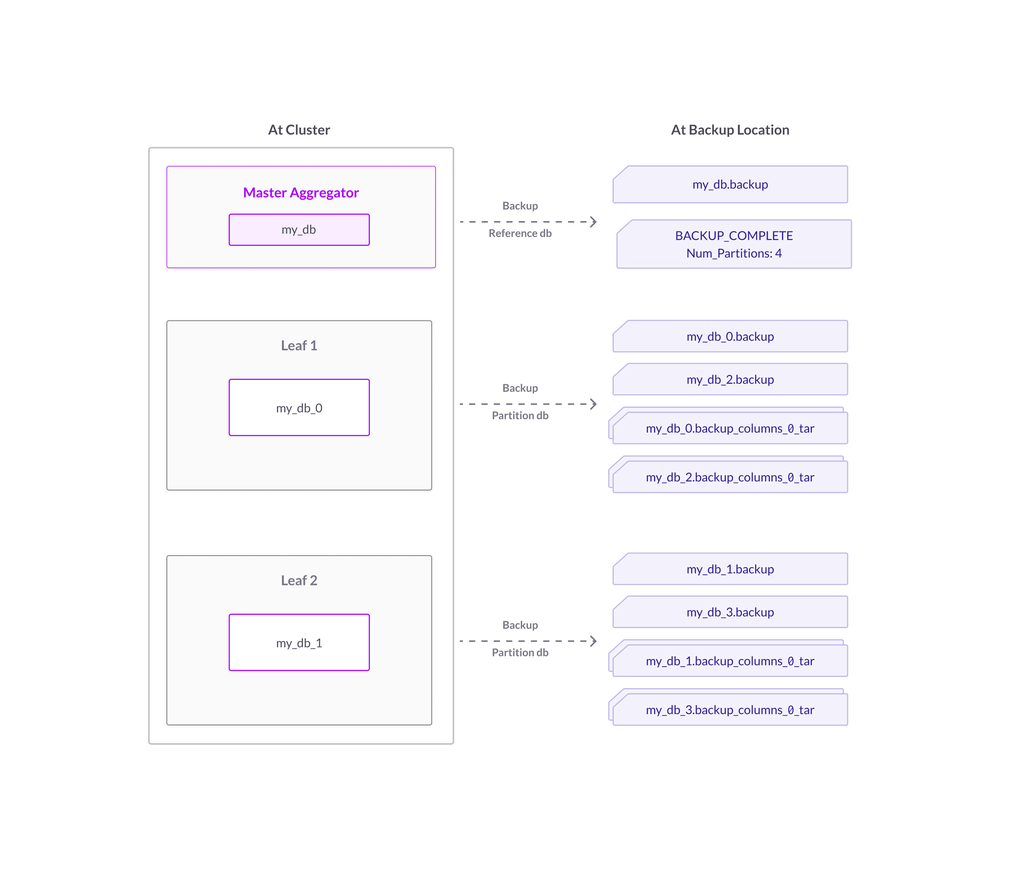
Figure 2. Backup with split partitions
We chose to piggyback on backup, because it was already a very sturdy and reliable operation that succeeds or fails very transparently and because backup already makes sure that we have a consistent image of the whole distributed database.
When we restore our split backup, the split partitions in the backup will restore as split partitions in the cluster.
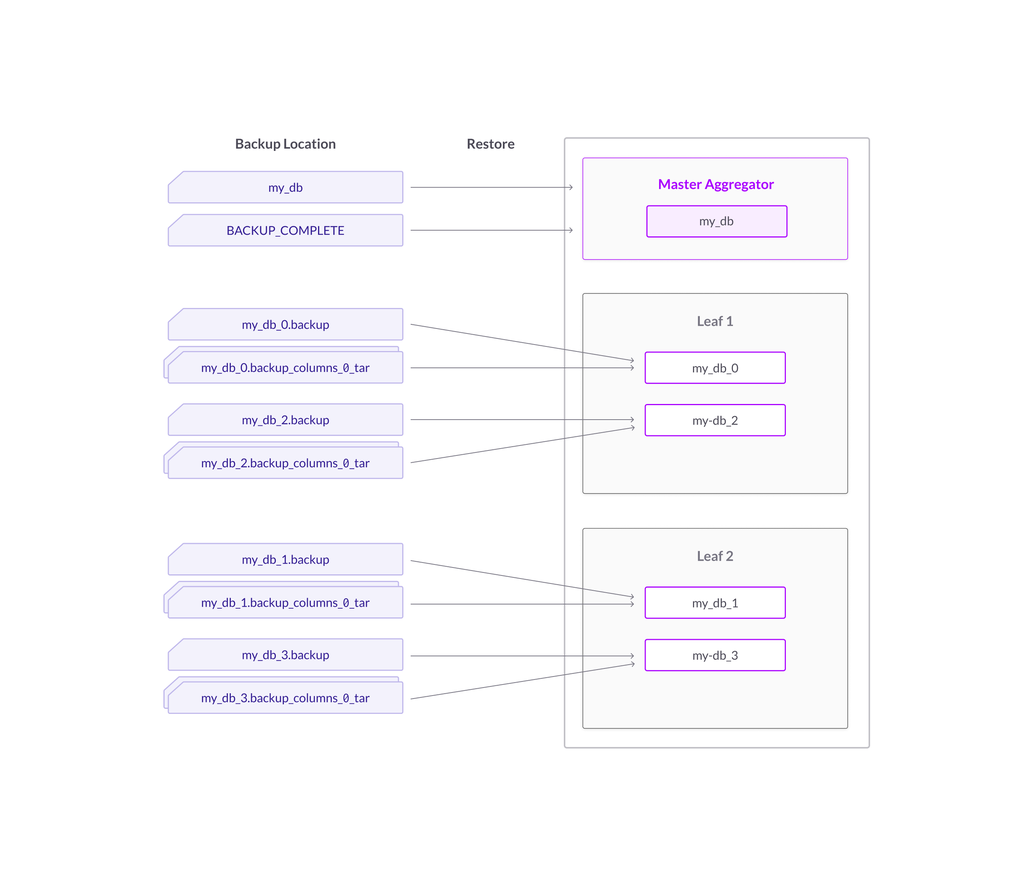
Figure 3. Restore of backup with split partitions
As you can see, splitting partitions is actually a three-stage process consisting of taking a split backup, dropping the database, and restoring the split backup. Now let’s now see this in practice.
Example Workflow
Pre-Split-Partitions Work
(Optional) Add Leaves
If you’re expanding your database’s resources by adding new leaves, you will want to add the leaves first before taking a split backup.
This could save you an extra step of rebalance partitions at the end of restore, since for all backups except for local filesystem backups, restore will start with creating partitions in a balanced way to begin with. An extra bonus is that recovery will be faster if recovery is spread out among more leaves and resources.
The command would look something like this:
ADD LEAF user[:'password']@'host'[:port] [INTO GROUP{1|2} ]
The reason I recommend doing it before backup is because although you can add leaves anytime, if you were going to pause your workload for backup split, you would want to avoid any action like add leaves that would prolong your workload downtime. If you do end up adding leaves after restoring the split backup, or you did a backup with split partitions to a local filesystem location on each leaf, you will need to remember to run REBALANCE PARTITIONS after the restore completes.
(Optional, But Recommended) Pause Workload
It is true for all backups that backups only contain writes up to the point of that backup. If you restore an old backup, you will not have new rows added after the old backup was taken. This holds true for our split backups as well. If you do not wish to lose any writes written after the split backup was taken, you should make sure that writes are blocked when the backup starts until the database is restored.
Split Partitions Work
(Step 1) Backup with split partitions command:
BACKUP [DATABASE] db_name WITH SPLIT PARTITIONS
TO [S3|GCS|AZURE] ‘backup_location’ [S3 or GCS or Azure configs and credentials]
Rowstore data will be split between the split backups, so the total size of rowstore split backups should be roughly the same as rowstore unsplit backups. In your backup location, these will have the .backup postfix. Columnstore blobs of a partition will be duplicated between the split backups of that partition, and so columnstore blobs will take twice the disk space in a backup with split partitions. I recommend leaving enough space for at least two full backups in order to attempt one backup with split partitions. Once the split backups are restored and columnstore merger has run, the blobs will no longer be duplicated (more details in the optimize table portion below).
You can verify that the backup succeeded by looking at information_schema.MV_BACKUP_STATUS`` and/or information_schema.MV_BACKUP_HISTORY and
For more details about backup, refer to the backup database command documentation and the documentation on backup and restore.
(Step 2) Normal drop database command:
DROP DATABASE db_name
(Step 3) Normal restore database command:
RESTORE [DATABASE] db_name
FROM [S3|GCS|AZURE] "backup_location" [S3 or GCS or Azure configs and credentials]
For more details on restore, refer to the restore database command documentation.
Post-Split-Partitions Work
(Optional, but Recommended) Unpause Workload
If you paused your write workload earlier, your workload can be unpaused as soon as restore runs.
(Recommended) Explain Rebalance Partitions
If you backed up to NFS, S3 or Azure, and you did not add any leaves after you restored, there should be no rebalance work suggested by the EXPLAIN REBALANCE PARTITIONS command. If you backed up to the local filesystem, which creates individual backups on every preexisting leaf and you increased the number of leaves, EXPLAIN REBALANCE PARTITIONS will most likely suggest a rebalance, which you should execute to optimize future query performance.
(Optional, but Sometimes Recommended) Optimize Table
After the split database backups are restored, the background columnstore merger will automatically be triggered. So although backup with split partitions duplicated the columnstore blobs, the columnstore merger will eventually compact the columnstore blobs so that they use less space on disk. The columnstore merger will eventually compact the columnstore blobs so that they use less space on disk. After the merger has finished running on all columnstore blobs, the database should get back to using roughly the same amount of disk space for the same amount of data as before the backup split, and all future normal backups will take a normal amount of space. Expect to see more CPU usage from this background process while it is reducing the disk usage of the blobs.
During our testing, we found that overly sparse columnstore segments incurred a temporary performance hit for queries like select and range queries before the columnstore merger or optimize table finished running. A performance-sensitive user may want to manually run optimize table on all the tables of the newly split database to explicitly trigger columnstore merger rather than waiting around for the background columnstore merger to eventually get to tidying up a particular table.




-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)





