
In part I of this series we covered how to set up a data pipeline with SingleStore Jobs, and expose a hybrid search REST API with SingleStore Cloud functions.

In part II, we’ll dive into building an entire agent from scratch in Python Notebooks. A general purpose agent consists of:
- LLM integration. Using SingleStore's inference APIs for chat completions
- Tool calling. Implementing tools for web search (SerpAPI) and vector search
- Conversation management. Persisting and managing user conversations
- Streaming responses. Enabling real-time streaming of agent responses
- Evals, guardrails and observability. Ensures agents can be improved continually and debugged for security and tuning. We never go to this phase. But this is an essential factor to consider for any production-ready agent.
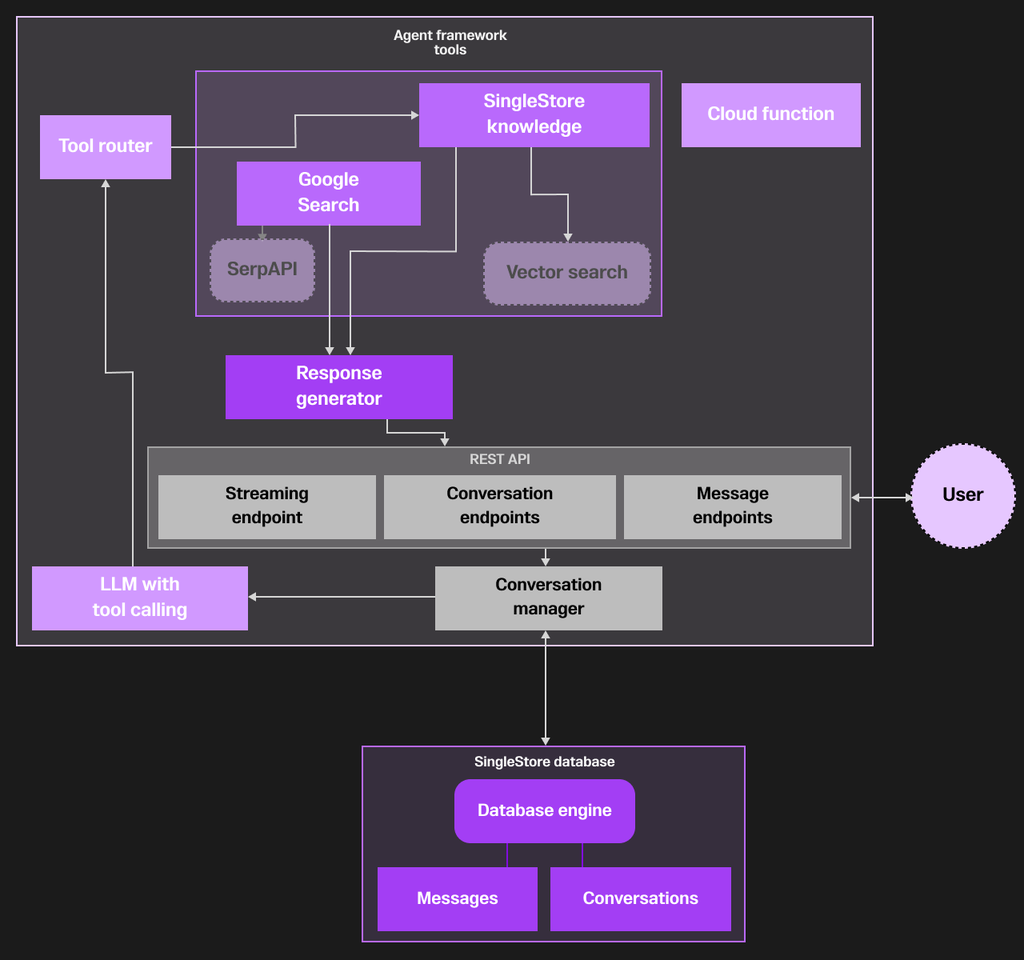
Benefits of this approach
By building our solution on SingleStore's platform, we can demonstrate several advantages:
- Unified data platform. Using a single system for both vector and text search simplifies the architecture
- Scheduled jobs. Automating the data pipeline using SingleStore's scheduled jobs feature
- Cloud functions. Deploying search functionality as serverless functions
- Scalability. Leveraging SingleStore's distributed architecture for future scalability and performance
- Flexibility. Building our own agent gave us complete control over its behavior and a possibility to extend it as needed for business requirements
Building an agent with web and vector search tools and persistence
The need for a complete reasoning agent
After implementing our hybrid search capabilities, the final step was to build an agent that could leverage these search tools along with web search to effectively answer user questions. We also needed to ensure all conversations could be properly persisted so users could revisit previous interactions, and the agent could maintain context across sessions.
Building blocks of our agent
Our agent consists of several essential components working together:
Database schema for conversation persistence
We designed a robust database schema to store all aspects of conversations:
1-- Conversations table to track top-level metadata2CREATE TABLE conversations (3 conversation_id VARCHAR(36) PRIMARY KEY,4 created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,5 last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP,6 metadata JSON DEFAULT '{}'7);8 9-- Messages table to store all conversation messages10CREATE TABLE messages (11 message_id VARCHAR(36) PRIMARY KEY,12 conversation_id VARCHAR(36) NOT NULL,13 role VARCHAR(10) NOT NULL, -- 'user', 'assistant', 'system', or 'tool'14 content MEDIUMTEXT NOT NULL,15 tool_calls JSON DEFAULT NULL,16 tool_call_id VARCHAR(255) DEFAULT NULL,17 sequence_order INT NOT NULL,18 timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP19);
This schema allows us to:
- Store complete conversation history with proper ordering
- Track tool calls and their results
- Maintain conversation metadata for future extensions
- Support efficient retrieval for context loading
Tool definitions and integrations
We implemented two primary tools for our agent:
Google search tool
For general knowledge and questions outside of SingleStore's domain:
1def google_search(parameters):2 """3 Makes a call to SerpAPI to search Google and returns results with sources.4 """5 api_key = SERPAPI_API_KEY6 if not api_key:7 return {"content": "SERPAPI_API_KEY not set. Please set your search API8key.", "sources": []}9 10 query = parameters.get("query", "")11 params = {12 "engine": "google",13 "q": query,14 "api_key": api_key,15 "num": "5", # Request top 5 results for more comprehensive sources16 }17 18 # Implementation details for making the request and formatting the results19 # ...
Vector search tool
For SingleStore-specific documentation and knowledge:
1def retrieve_singlestore_knowledge(parameters):2 query = parameters.get("query", "")3 if not query:4 return {"content": "No query provided for SingleStore knowledge 5retrieval.", "sources": []}6 7 # Implementation details for making the request to our hybrid search 8endpoint9 # ...10 11 # With automatic fallback to Google search if the vector search endpoint 12fails13 # ...
Both tools:
- Accept a standardized parameters format for consistency
- Return results in a structured format with content and sources
- Include proper error handling and fallback mechanisms
- Process and format results for consumption by the LLM
LLM integration with tool calling
The core of our agent's reasoning capability comes from the LLM with tool calling:
1def get_llm_response(history):2 """3 Uses the OpenAI client to get the assistant's response based on 4conversation history.5 6 Args:7 history (list): List of message dictionaries with role and content keys8 9 Returns:10 str: The assistant's response content11 """12 try:13 response = client.chat.completions.create(14 model=INFERENCE_MODEL_NAME,15 messages=history,16 temperature=MODEL_RESPONSE_TEMPERATURE,17 max_tokens=MODEL_RESPONSE_MAX_TOKENS,18 tools=tool_specs19 )20 21 # Process response, handle tool calls, etc.22 # ...
For streaming responses, we created a specialized version:
1async def get_llm_response_stream(history):2 """3 Uses the OpenAI client to get a streaming response based on conversation 4history.5 6 Args:7 history (list): List of message dictionaries from database8 9 Returns:10 AsyncGenerator: Yields chunks of the assistant's response and a final 11result12 """13 # Implementation for streaming responses with tool calling capability14 # ...
These functions:
- Provide consistent interfaces for both streaming and non-streaming scenarios
- Include tool definitions with the requests
- Handle the complexity of processing tool call requests and responses
- Format content appropriately for the end user
System message with instructions
We carefully crafted a system message to guide the agent's behavior:
1SYSTEM_MESSAGE = """2You are a helpful assistant. When a user's query requires up-to-date or 3external information, 4use the appropriate tool:5 61. For general knowledge queries, use the 'google_search' function.72. For queries related to SingleStore, databases, vector search, or any 8SingleStore-specific technology, 9 use the 'retrieve_singlestore_knowledge' function.10 11After receiving tool results, carefully analyze the information and use it as 12the primary source for your answer. 13This information is the most up-to-date and should be prioritized over your 14pre-existing knowledge.15IMPORTANT: Format your response using these guidelines:161. Write your response in Markdown format.172. Include inline citations that combine the source number and direct link, 18like this: 19 [[1]](https://example.com). For example: SingleStore supports 20vectorization[[1]](https://docs.singlestore.com).213. At the end of your response, include a '## Sources' section with a numbered 22list of all the sources you cited.234. Format each source in the list as a Markdown link with the title as the link 24text.255. Ensure every significant claim or piece of information has a citation.26 27Example format:28SingleStore supports vectorization through its built-in vector 29functions[[1]](https://docs.singlestore.com/managed-service/en/reference/vector30-functions.html). This capability enables efficient 31similarity search operations for machine learning 32applications[[2]](https://www.singlestore.com/blog/vector-search-for-ai/).33 34## Sources35[1] [SingleStore Vector Search 36Documentation](https://docs.singlestore.com/managed-service/en/reference/vector37-functions.html)38[2] [Building AI Applications with 39SingleStore](https://www.singlestore.com/blog/vector-search-for-ai/)40"""41
This message:
- Defines the agent's role and capabilities
- Provides clear instructions for tool selection
- Establishes formatting requirements for responses, including citations
- Shows examples of proper format for clarity
The REST API endpoints
To make our agent accessible to applications, we implemented a comprehensive REST API:
Conversation management endpoints
1@app.post("/conversation", response_model=ConversationResponse)2async def create_conversation():3 """Create a new conversation with a unique ID"""4 # Implementation details for creating a new conversation5 # ...6 7@app.get("/conversation/{conversation_id}", 8response_model=ConversationResponse)9async def get_conversation(conversation_id: str):10 """Get the conversation history for a specific conversation ID"""11 # Implementation details for retrieving conversation history12 # ...13 14@app.delete("/conversation/{conversation_id}")15async def delete_conversation(conversation_id: str):16 """Delete a conversation and all its messages"""17 # Implementation details for deleting a conversation18 # ...19 20@app.get("/conversations/recent")21async def get_recent_conversations(limit: int = 10):22 """Get list of recent conversations"""23 # Implementation details for listing recent conversations24 # ...25 26@app.get("/conversation/{conversation_id}/preview")27async def get_conversation_preview(conversation_id: str, message_limit: int = 283):29 """Get conversation with preview of recent messages"""30 # Implementation details for generating a conversation preview31 # ...
These endpoints provide:
- Complete conversation lifecycle management
- Efficient previews for UI display
- Pagination and filtering capabilities
- Proper error handling and response codes
Messaging endpoints
The core of our agent's interaction happens through the messaging endpoints:
1@app.post("/message", response_model=MessageResponse)2async def send_message(request: MessageRequest):3 # Initialize or retrieve conversation4 # ...5 6 # Get current messages from database7 # ...8 9 # Add user message10 # ...11 12 # Get initial response and check for tool calls13 # ...14 15 # Execute selected tool and process results16 # ...17 18 # Get final response incorporating tool results19 # ...20 21 # Add citations and return the response22 # ...
For real-time interaction, we implemented a streaming endpoint:
1@app.post("/message/stream")2async def send_message_stream(request: MessageStreamRequest):3 # Implementation details for streaming responses4 # ...5 6 async def stream_generator():7 # Generate streamed responses with tool execution8 # ...9 10 return StreamingResponse(stream_generator(), 11media_type="text/event-stream")
These endpoints:
- Support both standard and streaming response modes
- Handle the complete messaging flow, including tool execution
- Manage database persistence automatically
- Add proper citations to responses with source links
- Return structured data for client consumption
Tool execution flow
The intelligent routing between different tools is a key feature of our implementation:
- Initial analysis. The LLM determines whether a query relates to SingleStore, or is a general question
- Tool selection
- For SingleStore queries: Use
retrieve_singlestore-knowledge - For general questions: Use
google_search
- For SingleStore queries: Use
- Execution with fallback
- If the selected tool fails, the system can fall back to an alternative
- For example if vector search fails, fall back to web search
- Result processing
- Tool results are processed to extract content and sources
- Large responses are appropriately truncated
- Sources are extracted for citation generation
- Final response generation
- The LLM receives tool results and generates a final response
- Citations are automatically added to reference sources
- The response is formatted according to the system message guidelines
Enhancing response quality with citations
To improve the quality and verifiability of responses, implement automatic citation handling:
1def add_citation_numbers(text, sources):2 """3 Enhances text with inline citations that include both numbers and links.4 5 Args:6 text (str): The response text7 sources (list): List of source dictionaries8 9 Returns:10 str: Text with properly formatted citations11 """12 # Implementation details for adding inline citations13 # ...14 15 # Add sources section if needed16 # ...17
This function:
- Detects existing citations in the text
- Adds source links to citation numbers
- Adds a sources section if one doesn't exist
- Formats each source as a proper markdown link
Deployment as a FastAPI cloud function
The entire agent system is packaged as a SingleStore cloud function:
1# Create FastAPI app2app = FastAPI(3 title="SingleStore Chatbot API",4 lifespan=lifespan5)6 7# Run the Cloud function8connection_info = await apps.run_function_app(app)
By building this complete agent with database persistence, we've created a system that:
- Effectively leverages our vector search capabilities for SingleStore documentation
- Falls back to web search for general knowledge questions
- Maintains conversation context across multiple sessions
- Provides both real-time streaming and standard request/response interaction modes
- Formats responses with proper citations for verifiability
The user experience flow
From the user's perspective, interacting with our agent follows this flow:
- The user sends a message through one of the API endpoints
- The agent processes the message and determines if it needs external information to respond effectively
- If the query relates to SingleStore, the agent uses the vector search tool to retrieve relevant documentation
- If the query is about general knowledge — or if vector search fails — the agent uses the Google search tool
- The agent receives the search results, processes them and integrates the information into its response
- The response is formatted with proper citations and sources, then returned to the user
- All interactions are persisted in the database, allowing continued conversation and context retention
Putting it all together
The result is a simple agentic chatbot that can effectively answer questions about SingleStore, supplement that knowledge with web search when needed and maintain conversational context across sessions.
Looking to the future
While our current implementation provides a solid foundation, there are several exciting directions for future enhancement:
1. Enhanced retrieval techniques
We could further improve our search capabilities by implementing:
- Query expansion. Automatically expanding queries with related terms to improve recall
- Re-ranking. Using a second-stage model to re-rank initial search results
- Query intent classification. Adapting the search approach based on query type
- Document-level filters. Adding metadata filters for narrowing results by document type
2. Advanced agent capabilities
Our agent framework could be extended with:
- Multi-step reasoning. Breaking complex questions into sub-questions before answering
- Memory management. Implementing more sophisticated conversation memory mechanisms
- Tool combination. Enabling the agent to use multiple tools in a coordinated way
- Self-evaluation. Having the agent critique and improve its own responses
3. Personalization features
We could enhance the user experience with:
- User preferences. Storing and respecting individual preferences for response style and detail level
- Topics of interest. Tracking user interests to provide more relevant responses over time
- Interaction history. Using long-term memory across conversations to build deeper context
4. Performance optimizations
For production environments, we might consider:
- Caching common queries. Storing results for frequently asked questions
- Query similarity detection. Identifying when new questions are similar to previously answered ones
- Batched embedding generation. Optimizing embedding creation for larger document sets
- Distributed processing. Scaling the system across multiple nodes for higher throughput
5. Compliance and security enhancements
For enterprise deployment, we would add:
- Source tracking. Maintaining provenance for all information in responses
- Data retention policies. Implementing configurable policies for conversation history
- Access controls. Adding fine-grained permissions for different user roles
- Audit logging. Tracking all interactions for compliance and debugging
One of the most exciting aspects of this project is the same techniques can be applied to create domain-specific agents for other knowledge bases or applications. Whether you're building a product support bot, internal knowledge assistant or a research tool, the architecture outlined provides a flexible foundation.
Key components you can adapt and improve include:
- The scraping and processing pipeline for your specific content sources
- The chunking strategy based on your document structure
- The embedding model selection appropriate for your domain
- The agent's tool definitions and reasoning prompts — with this being a major area of research and progress. The MCP server makes implementing tool calling logic trivial, fine-tuning your prompts with a robust eval framework.
- Adding guardrails for both agent input and output to prevent malicious prompt injection, or hallucinated response detection and so much more.
Final thoughts
This chatbot demonstrates that building a sophisticated AI agent doesn't require complex frameworks or black-box solutions. With a clear understanding of the problem, thoughtful architecture and the right platform capabilities, it's possible to create a useful chatbot.
By leveraging SingleStore as the unified, performant data layer for both vector and full-text search — along with features like scheduled jobs and cloud functions — we've created a system that not only works well today but can evolve with changing requirements and technologies.
Frequently Asked Questions


.png?width=24&disable=upscale&auto=webp)









