
![[r]evolution Summer 2022: Distributed SQL “Workspaces” Power Modern Applications](https://images.contentstack.io/v3/assets/bltac01ee6daa3a1e14/blte4a5e6fc2c34627b/6433d905fbe24d10f96bc1a7/featured_distributed-sql-workspaces-power-modern-applications.png?width=736&disable=upscale&auto=webp)
We designed SingleStoreDB to be the world’s fastest distributed SQL database, and currently it powers some of the largest mission-critical applications at enterprises such as Uber, Comcast, Disney and Sirius XM.
These organizations are leveraging ultra-fast ingest, low latency queries, and the ability to support extreme concurrency to drive data-intensive SaaS, telemetry and operational machine learning workloads.
Many of our customers start with SingleStoreDB powering a single workload, but as companies leverage data across the organization to inform decision making and introduce new products and services, the need for shared data grows. Traditionally, companies copy data across various storage solutions and applications, and build a complex web of data and applications resulting in convoluted data pipelines between disparate data solos. This introduces cost, complexity and latency, resulting in critical applications operating on stale data.
Solution: Workspaces
Workspaces is our newest feature, which enables customers to run multiple workloads on isolated compute deployments, while providing ultra low-latency access to shared data. This is possible because of the unique SingleStoreDB architecture, leveraging our native internal data replication engine to ensure applications are always operating on fresh data.
Users can create and terminate workspaces directly using the cloud portal, or through our scalable Management API. Databases are created and attached to one or more workspaces concurrently, allowing simultaneous operation of multiple workloads on shared data. Databases can be attached and detached from workspaces on-the-fly, allowing organizations to manage and meet rapidly changing needs.
Because workspaces are stateless, they can be created and terminated at will, making it easy to run reporting or custom telemetry applications on the fly. When a workspace is terminated it no longer incurs charges, offering simple cost optimization of any workload while ensuring data is retained as long as needed.
Unique Design
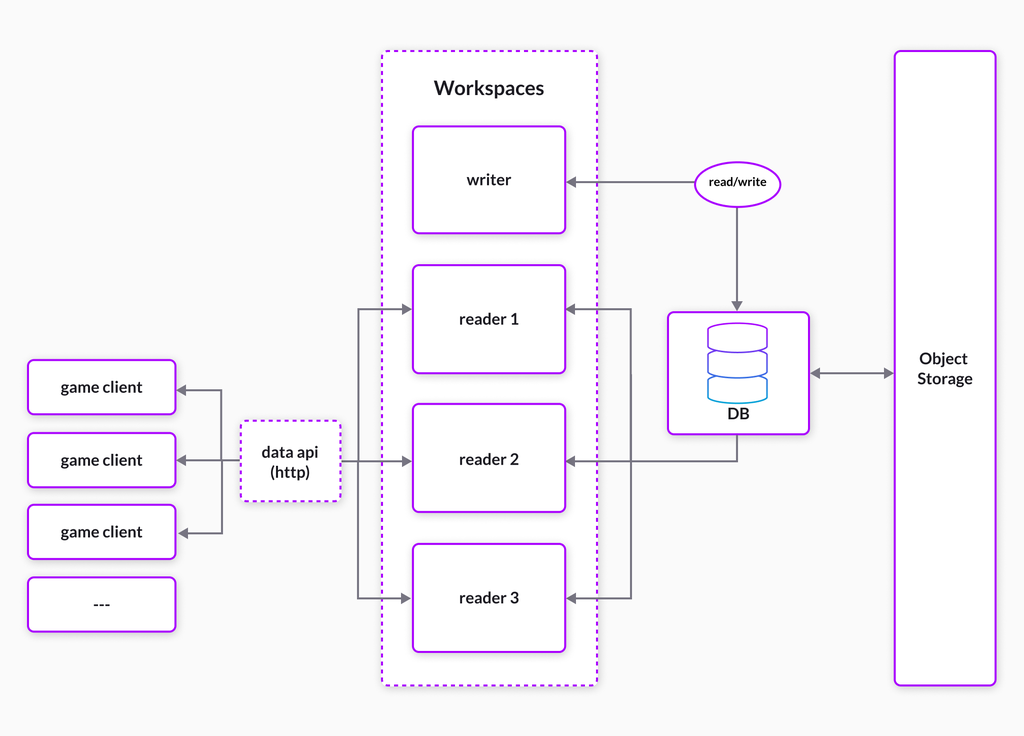
SingleStoreDB is the only real-time HTAP database designed on a modern distributed SQL architecture. This means that compute can be scaled out using the native clustered architecture, rather than simply scaling up using larger machines. Workspaces further enhance this distributed architecture by freeing databases from the confines of a single cluster, delivering the true value of separate compute and storage.
Some enterprise data warehouses offer a similar separation of compute and storage, but because they are only designed for analytic workloads, they sacrifice latency to enable this flexibility. This is because writes are forced to go to object storage, which introduces latency and causes queries to return stale data if changes haven’t been propagated completely across the storage stack.
SingleStoreDB is designed to power modern applications, where real-time access to data and low latency query responses are just as important as scalability and concurrency. To meet this need, SingleStoreDB workspaces are designed to provide low latency data access to databases across every workspace deployed within a group (a logical tool for organization of workspaces). Each separate application running on an independent workspace can be scaled up or down, while still ensuring fast access to fresh data.
Use Cases
Impact.com has been running SingleStoreDB to power their customer-facing applications for some time, but now with the introduction of Workspaces they have also moved their reporting and internal analytics workloads to SingleStoreDB, unifying their entire data architecture:
“Workspaces are very exciting for us… we can now simply add and scale workloads across the organization’s most important data!” - Mauricio Aristizabal, Data Architect, Impact.com
Impact found that the customer data being stored in SingleStoreDB was critical for reporting and other operational analytics within the company, but the process of moving this data out of SingleStoreDB and into pure analytics solutions like Cloudera or Snowflake was costly and time consuming. It also introduced latency, which meant that by the time analysts got to the data it was already stale. They wanted a way to run the workloads previously running on Hadoop directly on SingleStoreDB, which is where workspaces came in.
“..when Cloudera’s Impala and Kudu could not keep up with the speed of Impact’s business, SingleStoreDB delivered. SingleStoreDB checks all the boxes with sub-second reporting, low-latency analytics, high concurrency, separation of storage and compute with workspaces, and more — which is why SingleStoreDB is now Impact’s Database for 100% of its data and reporting. In short: All Data. One Platform.™”
In addition to scaling out to multiple workloads, workspaces also provides a simple way to manage isolation between ingest and application workloads. Many customers are now using isolated workspaces for ingesting from streaming data sources like Confluent Kafka or Redpanda, and blog posts like Nabil Nawaz’s “loading 100 billion rows ultrafast” show the incredible power of parallel ingest into SingleStoreDB. Now with workspaces, users can isolate ingest workloads and dynamically scale them up or down based on scheduling and performance needs, all while maintaining the consistent query response and strict SLAs needed for customer-facing applications.
More companies than ever are using machine learning to customize content for their customers, or to provide real-time services such as fraud detection. A Tier 1 U.S. Bank is using SingleStoreDB to deliver “On The Swipe Fraud Detection” by operationalizing fraud detection models against customer transactional data. Now with workspaces, these workloads can be run directly on data generated by customer facing applications, without affecting the ability to deliver application uptime or impacting user generated workloads. Workspaces provides complete isolation and independent scalability without requiring complex integration of multiple data sources.

Manage application & operational ML workloads with Workspaces
Design & Architecture
SingleStoreDB’s workspaces are built using the native data replication engine built into our database. If you have read about features such as leaf fanout failover you may already be familiar with the storage engine — but if not, check out Adam Prout’s description of what makes the SingleStoreDB storage engine unique.
Workspaces further this design by creating isolated pools of compute resources, which are clustered on top of cloud hardware. These compute pools have dedicated memory and persistent disk cache to deliver immediate query responsiveness, while operating on top of bulk scale-out object storage.
When combined with SingleStoreDB’s query code generation and tiered Universal Storage architecture, this allows workspaces to deliver extremely low latency query response, highly concurrent access and fast parallel streaming ingest while automating the movement of data across workloads.
Try Workspaces
SingleStoreDB offers a completely free trial of the cloud database-as-a-service to get started. The trial allows you to load data, connect your application, and experience the performance and scalability of a real-time Distributed SQL database.
You can also take a look at Eric Hanson’s demonstration of SingleStoreDB “running a trillion rows per second,” and try it for yourself to see how SingleStoreDB delivers the fastest performance and lowest query latency, deployed on your public cloud of choice.






.png?width=24&disable=upscale&auto=webp)









