In this presentation, recorded shortly after SingleStore introduced SingleStore Pipelines, two SingleStore engineers describe SingleStore’s underlying architecture and how it matches up perfectly to Kafka, including in the areas of scalability and exactly-once updates. The discussion includes specific SQL commands used to interface SingleStore to Kafka, unleashing a great deal of processing power from both technologies. In the video, the SingleStore people go on to describe how to try this on your own laptop, with free-to-use SingleStoreDB Self-Managed.
Introduction to SingleStore: Carl Sverre
I want to start with a question. What is SingleStore? It’s really important to understand the underpinnings of what makes Pipeline so great, which is our SingleStore distributed SQL engine.
There are three main areas of SingleStore that I want to talk about really briefly. The first area of SingleStore is that we’re a scalable SQL database. So if you’re familiar with MySQL, Postgres, Oracle, SQL Server, a lot of our really awesome competitors, we are really similar. If you’re used to their syntax, you can get up and running with SingleStore really easily, especially if you use MySQL. We actually have followed their syntax very similarly, and so if you already used MySQL, you can pretty much drop in SingleStore in place, and it just works.
So, familiar syntax, scalable SQL database. What makes us scalable, really briefly? Well, we’re a distributed system. We scale out on commodity hardware, which means you can run us in your favorite cloud provider, you can run us on-premises and it generally just works. It’s super, super fast, as you can see – really, really fast and it’s just fun.
So without further ado, I want to get into a little bit of the technical details that are behind what makes us such a great database. In SingleStore, we have two primary roles in the cluster. So if you think about a collection of Linux machines, we have some aggregators and some leaves. Aggregators are essentially responsible for the metadata-level concepts in the cluster. So we’re talking about the data definition layer – DDL, for people who are familiar SQL. We’re responsible for CREATE TABLE statements, for CREATE PIPELINE statements, which we’re going to get right into.

In addition, master aggregators and child aggregators collectively handle things like failover, high availability, cluster management, and really importantly, query distribution. So when a SELECT query comes in, or an INSERT command comes in, you want to get some data, you want to insert some data. What we do is we take those queries and we shard those queries down onto leaf nodes. So leaf nodes are never connected to directly by your app. Instead you connect to the aggregators and we shard down those queries to the leaf nodes.
And what are the leaf nodes? Well, leaf nodes satisfy a couple of really, really powerful features inside the engine. One feature is storage. If you have leaf nodes, you can store data. If you have more leaf nodes, you can store more data. That’s the general concept here. In addition, it handles pre-execution. So the more leaf nodes you have, generally the faster your database goes. That’s a great property to have in a distributed system. You want to go faster, add more leaf nodes. It generally scales up and we see some really amazing workloads that are satisfiable by simply increasing the size of the cluster. And that’s exciting.
Finally you get a sort of natural parallelism. Because we shard these queries to all the leaf nodes, you can sort of take advantage of the fact that by scaling out, you are taking advantage of many, many cores like real, real solid Linux; everything you want performance-wise just works. And that’s a simple system to get behind, and I’m really excited to always talk about it because I’m a performance geek.
So that’s the general idea of SingleStore. This Meetup is going to be really focused on Pipelines, so I just wanted to give you some basic ideas at the SingleStore level.
Introduction to SingleStore Pipelines: John Bowler
Pipelines are SingleStore’s solution to real-time streaming. For those of you who are familiar with what an analytics pipeline looks like, you might have your production database going into a Kafka stream or writing to S3 or writing to a Hadoop data lake. You might have a computation framework like Spark or Storm, and then you might have an analytics database farther downstream, such as RedShift, for example. And you might have some business intelligence (BI) tools that are hitting those analytics databases.
So SingleStore Pipelines are our attempt at taking a step back and solving the core problem, which is: how do you easily and robustly and scalably create this sort of streaming analytics workload, end to end? And we are able to leverage some unique properties of our existing system.
For example, since SingleStore is already an ACID-compliant SQL database, we get things like exactly-once semantics out of the box. Every micro-batch that you’re streaming through your system happens within a transaction. So you’re not going to duplicate micro-batches and you’re not going to drop them.
You also have these pipelines, these streaming workloads are automatically distributed using exactly the same underlying machinery that we use to distribute our tables. In our database, they’re just automatically sharded across your entire cluster.
And finally, for those of you who have made these sort of analytics workloads, there’s always going to be some sort of computation step, whether it’s Spark or any similar frameworks. We offer the ability to perform this computation, this transformation, written in whatever language you want, using whatever framework or whatever libraries you want. (This happens within the Pipeline, very fast. Accomplishing the same thing as an ETL step, but within a real-time streaming context. – Ed.) And we’ll explain in more detail how that works.
So this is how you create a pipeline – or, this is one of the ways that you create a pipeline. You’ll notice that it is very similar to a CREATE TABLE statement and you can also alter a pipeline and drop a pipeline. The fact is that pipelines exist as first-class entities within our database engine.

And underneath this CREATE PIPELINE line is a LOAD DATA statement that is familiar to anyone who’s used a SQL database, except instead of loading data from a file, you’re loading data from Kafka, specifically from this, a host name and the tweets topic. And then the destination of this stream is the tweets table. So in this three lines of SQL, you can declaratively describe the source of your stream and the sync of your stream and everything related to managing it is automatically handled by the SingleStore engine.
This is sort of a diagram of how it works. Kafka, for those of you who are unfamiliar, is a distributed message queue. When you’re building analytics pipelines, you very commonly have lots of bits of production code that are emitting events or emitting clicks or emitting sensor data and they all have to get aggregated into some sort of buffer somewhere for whatever part of your analytics system is consuming them. Kafka is one of those very commonly used types, and it’s one that we support.
So you have all different parts of your production system emitting events. They arrive in Kafka, maybe a few days worth of buffer. And when you create your pipeline in SingleStore, it automatically streams data in. Now, Kafka is a distributed system. You have data sharded across your entire cluster. SingleStore is also a distributed system. You have data sharded across your entire set of leaf nodes. So when you create this Kafka consumer, it happens in parallel, automatically.
Now, this is sufficient if you have data in Kafka and you just want to load it straight into a table. If you additionally want to run some sort of transform, or MapReduce, or RDD-like operation on it, then you can have a transform. And the transform is just a binary or just a program.
You can write it in whatever language you want. All it does is it reads records from stdin and it writes records to stdout, which means that you could write it as a Python script. You could write it as a Bash script. You could write it as a C program if you want. Amazing performance. You can do any sort of machine learning or data science work. You can even hit an external server if you want to.
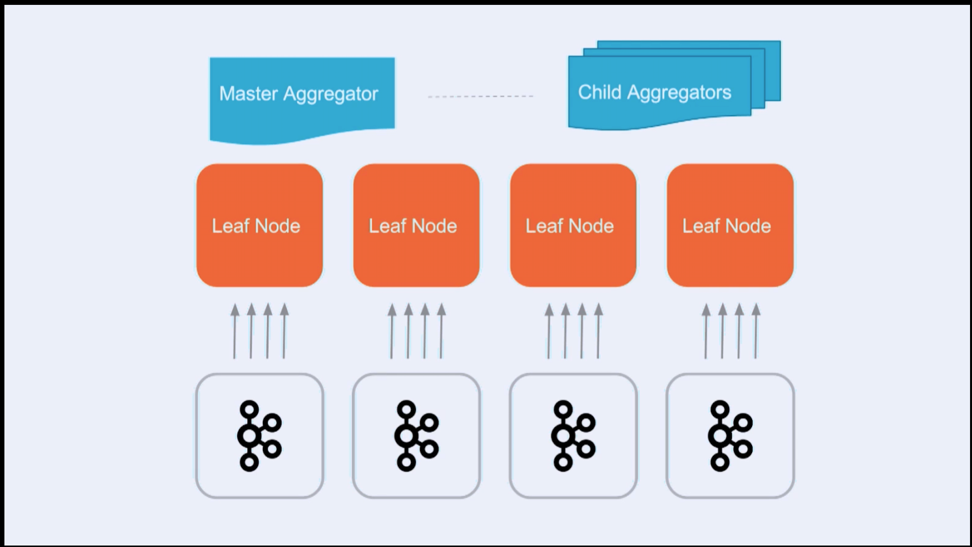
So every record that gets received from Kafka passes through this transform and is loaded into the leaf, and all of this happens automatically in parallel. You create the code of this transform and SingleStore takes care of automatically deploying it for you across this entire cluster.
Conclusion
The video shows all of the above, plus a demonstration you can try yourself, using SingleStore to process tweet streams. You can download and run SingleStore for free or contact SingleStore.