

Data is changing. You knew that. But the dialog over the past 10 years around big data and Hadoop is rapidly moving to data and real-time.
We have tackled how to capture big data at scale. We can thank the Hadoop Distributed File System for that, as well as cloud object stores like AWS S3.
But we have not yet tackled the instant results part of big data. For that we need more. But first, some history.
Turning Point for the Traditional Data Warehouse
Internet scale workloads that emerged in the past ten years threw the traditional data warehouse model for a loop. Specifically, the last generation of data warehouses relied on
- Scale up models; and
- Appliance approaches
Vast amounts of internet and mobile data have made these prior approaches uneconomical, and today customers suffer the high cost of conventional data warehouses.
Images created with Infinite Design from Infinite Studio.
Focus on BIG
Around the time of this new workload boom, Hadoop appeared and captured the attention of companies worldwide. The origins of Hadoop derive first from Google, then Yahoo and Facebook. In a matter of just a few years, Hadoop was synonymous with big data. But throughout most of Hadoop’s existence, the focus has been on the big, more than the fast. “Big Data” became a preferred term but as Gartner analyst Nick Heudecker noted on Twitter,
Increasingly, the term #BigData is used by industry laggards, not leaders.
— Nick Heudecker (@nheudecker) March 27, 2017

Recognizing Hadoop For What It Is, And Not
It became clear that Hadoop was really two things in one
- The MapReduce computation capabilities that could execute operations in batch mode
- The Hadoop Distributed File System which, even with 3x replication, provided far cheaper storage than traditional alternatives
Unfortunately neither proved to be very effective for fast data.
MapReduce has been passed over in many cases for faster processing engines like Spark. And many users find that the only way to make use of MapReduce is through pre-computing, a lengthy process that leaves data inherently out of date and restricted to a pre-defined set of dimensions.
HDFS provides cheap storage, but none of the mechanisms for fast ingest or fast access. This relegates HDFS to an archive, but not much more

Tackling Fast Data Requirements
Hadoop realities still leave data engineers short of handling fast data requirements. In particular they need
Fast Data Ingest
- The ability to natively ingest large volumes of data
- De-duplicating data on the fly with unique keys
Low Latency Queries
- Native SQL queries, built on a SQL engine, for sophisticated, real-time adhoc analytics
High Concurrency
- Lock-free handling of read AND write workloads
- Support for large numbers of simultaneous users and queries

Architecting a Data Lake with A Real-Time Data Warehouse
A simple architecture has emerged to help customers handle data volumes and real-time requirements.
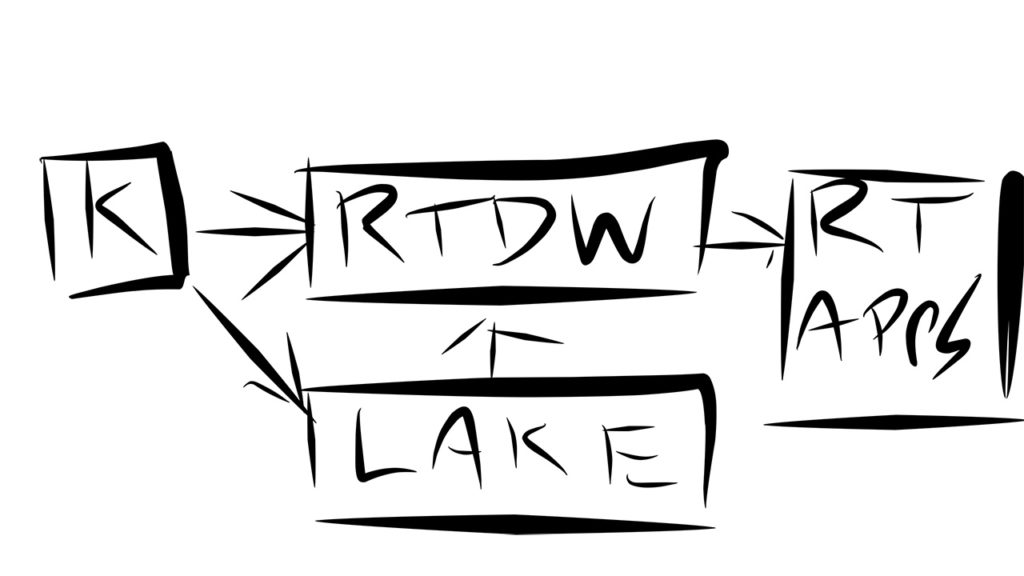
- Application or Message Queue (K)
- Data Archive (LAKE)
- Real-Time Data Warehouse (RTDW)
- Real-Time Analytics/Application (RT APPS)
K for Kafka, another message queue, or an application.
The architecture often begins with Apache Kafka, the popular message queue, but could start with other message queue or even directly with applications that write to the data warehouse and data lake.
LAKE Hadoop or cloud object store.
Often there is a desire to store everything in a data lake, so the rest of the company has a consolidated archive of data. This approach can be retained while still incorporating a real-time solution
RTDW Real-Time Data Warehouse.
A real-time data warehouse enables fast ingest of changing data while simultaneously delivering instant response to analytics from real-time applications or dashboards.
The real-time data warehouse can also bring data in from the data lake should there be a need.
RT APPS Real-Time Applications.
The goal is to have instant access to data, so that the business can run as fast as it should. Delivering a fast path for fresh analytics allows applications and dashboards to remain current. Being current becomes a currency in and of itself.
Real-Time for Instant Response, Lake for the Batch
The real-time data warehouse becomes the solution to enable the front lines of your business. When you count on response times and data freshness, look to your real-time data warehouse.
Everything else has an option to go to the lake. Batch processing, offline operations, and long term archive of historical data suit the data management characteristics of solutions like Hadoop.
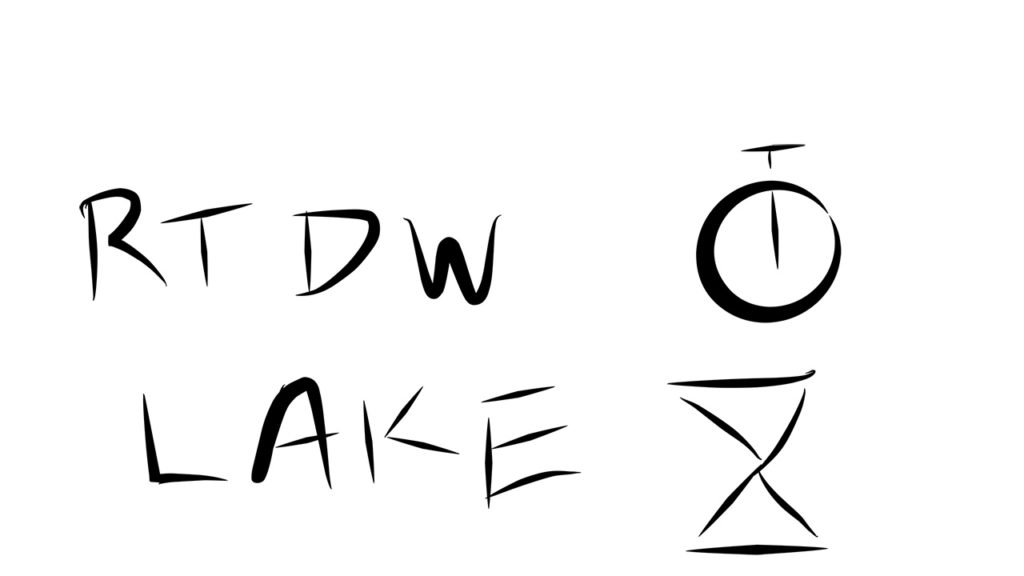
Make Every Moment Work for You
As more companies move to real time, they need a technical and business minded approach to new solutions. Four tenets can help get you there
Drive down conventional data warehouse costs
Traditional data warehouse solutions focused on appliance models, non-scalable architectures, and batch processing can be replaced by modern distributed, memory-optimized solutions that cost significantly less.
Lambda Architectures
Lambda architectures deliver ingest, archive, and real-time data serving. See this blog post for more. A real-time data warehouse, optionally with a data lake, gives you just that.
Real-Time Analytics
Businesses live or die based on the relevance, accuracy, and timeliness of their information and decisions. Take processes from days to hours, hours to minutes, and minutes to seconds or less with real-time analytics.
A Native SQL Engine
Today everyone recognizes the importance of retaining SQL. But adding SQL as an afterthought to a data lake can only service offline, batch process requirements. A SQL engine built natively into the real-time data warehouse provides the foundation for live analytics embedded in applications or dashboards.

Launch Your Real-Time Journey Today
To get ahead with a real-time data warehouse, please visit www.singlestore.com









