
Our performance engineering team is committed to delivering high quality tools. Since we released dbbench 7 months ago, it has been widely adopted across our engineering and sales teams as the definitive tool for testing database workloads. Today we are announcing availability of a new version of dbbench, as well as a package of high level tools to enhance it.
In this latest release, we enhanced both the flexibility and ease of use of the tool. We augmented capabilities of dbbench and added a tutorial to help new sales engineers get started. In addition to these enhancements, we released a package of internal tools specifically designed to support high level workflows that use dbbench. These changes improve our technical proof-of-concept (POC) process for our customers and open up dbbench for new workloads and use cases. This version of dbbench not only increases the performance and power of this benchmark testing tool, but also makes it easily accessible to anyone interested in using it.
dbbench in Action
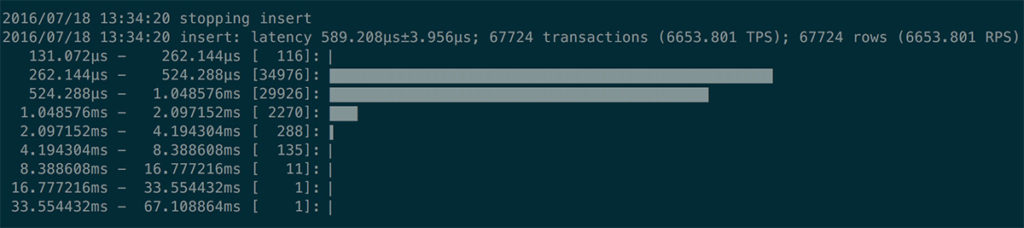
One of the new features of dbbench is the ability to display latency histograms during the final analysis to easily detect and understand outliers. In the example below, we can see that most of the queries executed between 0.2 and 0.5 ms, but there were outliers as high as 30ms:
To support more complicated and varying data, dbbench can read arguments from a .csv file and parameterize queries via the query-args-file parameter. The snippet below shows this parameter specified in a configuration.ini file for dbbench:
[insert]
query=insert into table colors (?)
query-args-file=/tmp/colors.csv
In addition, the query-results-file parameter allows dbbench to chain multiple jobs together, and makes it possible to have external tools in between each of these jobs.
dbbench-tools
dbbench-tools is a package of sales engineering tools, used by the SingleStore team to easily describe and efficiently run a customer workload during a technical POC. The most important question to answer during a POC is “how will SingleStore scale to more concurrent users?” dbbench-scaler is one of several tools provided by the dbbench-tools package to help answer this question. dbbench-scaler runs a dbbench-defined workload at different levels of concurrency to find the limits of the database installation.
For example, I was doing a POC where I wanted to determine how many concurrent inserts a small SingleStore cluster could handle. I set up a simple dbbench test:
[setup]
query=create table test(a varchar(20), b float, c float, d float, \
shard key a (a), key b (b), key c (c), key d (d))
[teardown]
query=drop table test
[batch sized 128 multi-inserts]
query=insert into test values (?, ?, ?, ?), (?, ?, ?, ?), …, (?, ?, ?, ?)
query-args-file=/tmp/data.csv
concurrency=1
I ran dbbench-scaler with this configuration to determine that this small test cluster could sustain 100,000 inserts per second in batches of 128, as depicted in the top half of the chart below. In the bottom half of the chart, we see that using more connections allows us to insert more records per second (RPS) until we reach 32 connections, after which there is no benefit to using more connections and we see a hugely adverse effect on query latency:
$ dbbench-scaler --database=db --concurrency=1,2,4,8,16,32,64,128,256,512 --output out.png /tmp/test.ini
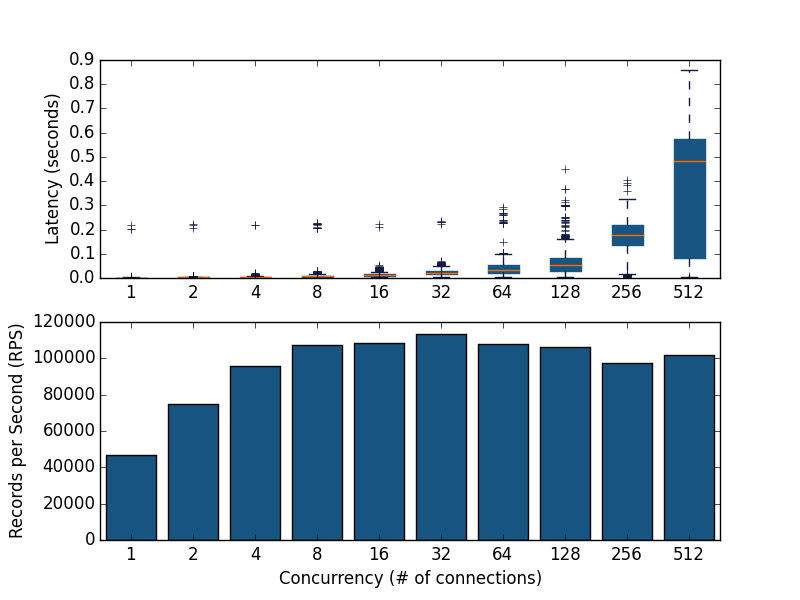
In this example, not only did dbbench-scaler answer the question “will SingleStore handle the scale of many users”, it also found the ideal number of users for this application.
Access the new version of dbbench here and get dbbench-tools here. Learn even more about the new features in our tutorial.




![Announcing SingleStore Start[c]up 2.0](https://images.contentstack.io/v3/assets/bltac01ee6daa3a1e14/blt2d1e7c1fad98bbfd/63ea47ed19d99f7808a29fcb/featured_announcing-memsql-startcup-2-0.png?height=187&disable=upscale&auto=webp)
