

This blog post describes how Hadoop has moved through the famous Gartner Hype Cycle, and how it is now often combined with SQL-native solutions to deliver results. The author, Yassine Faihe, is Head of International Solution Consulting at SingleStore. This piece originally appeared, in slightly different form, on LinkedIn last December.
Hadoop, which was once poised to rule the large-scale data analytics space and toll the bell for traditional data warehouses, is currently experiencing a hard fall.
This apparent decline began nearly ten years ago, when articles and blog posts discussing the failure of Hadoop and questioning its future started to proliferate: ‘The Hadoop Hangover’, ‘Why Hadoop is Dying’, ‘Hadoop is Failing Us,’ and so on.
The decline of Hadoop was further illustrated by the merger of Cloudera and Hortonworks, and the sudden acquisition by HPE of the remains of MapR. Hadoop’s adoption is currently stagnating, and even declining, despite persistent enthusiasm from practitioners. Today, many wonder what is the future of Hadoop and, more importantly, how do Hadoop adopters still make the most of their investments?
In this post, I will argue that Hadoop is simply going through the evolution cycle of any emerging technology, and I will attempt to analyze this evolution from the perspective of the Gartner Hype Cycle.
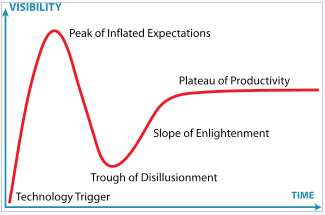
This image appears courtesy of Wikipedia.
Technology Trigger
Nearly fifteen years ago, the Hadoop breakthrough occurred and was heavily reinforced by early adopters and media coverage. The technology trigger was the moment when Hadoop became an Apache project with HDFS and MapReduce, and Yahoo deployed their first clusters in production, followed by other large websites, and then emerging data companies.
Hadoop was cool and open source, and it disrupted the storage industry – while bringing a distributed compute capability needed for modern data sizes, thus triggering an unprecedented rush.
Peak of Inflated Expectations
The peak is an interesting and funny milestone for technologies in general, in the sense that, at this point, technologies are often considered to be a sort of panacea for any problem in a given domain or industry. For Hadoop, this peak happened when the terms “Hadoop” and “Big Data” became synonymous. A virtuous circle was created by reported success stories from notable data companies, and later reinforced by enterprises starting to operationalize their big data strategy by implementing Hadoop-based data lakes. However, those claimed successes were not always fully supported by facts, and failures were overlooked.
Almost every enterprise embarking on a digital transformation had to demonstrate some kind of tech-savviness, and was either investigating or experimenting with Hadoop as part of becoming more data-driven. The strong coverage by mainstream tech media and the perception that Hadoop was “free” further accelerated and amplified the phenomenon. At the same time, huge amounts of funding from venture capitalists were flowing into the startups behind major Hadoop distributions. Hadoop ,as an Apache effort and distribution, grew to encompass more than 30 projects – from storage to compute frameworks to security and much more.
Companies wanting to get a competitive edge by analyzing a large amount of diverse data jumped on Hadoop, looking at it as a silver bullet. Many adopted it without doing their due diligence. They were instead driven by the curiosity of engineers, who were eager to experiment with this emerging set of technologies. Hadoop was so hyped that it became the de facto answer to almost any data-related issue. That was reinforced by Hadoop’s ability to store big structured and unstructured data at a fraction of the cost of a storage area network (SAN). It was easy to get data in, so companies went all-in! Only later would they learn that their data lakes would become, in effect, “write-only.”
Trough of Disillusionment
It is at this stage of the hype cycle that failures become noticeable and the technology is called into question. This typically happens when more and more projects are promoted, from experimentation and pilots to production at scale, and more mainstream companies adopt the technology, thus increasing the likelihood of failure. For Hadoop, this started in about 2015, when some customers began to report on production issues related to operability, the lack of enterprise-grade security, and performance.
Very often, failures such as these are not caused by the technology per se, but by the way it is used. The hype prevented those adopters from differentiating between what they needed, what was promised, and what the technology could actually deliver. They eventually failed to get the expected value out of their investment, thus experiencing disillusionment. Hangover is the result of over-inflated expectations.
The main reason that explains this failure is Hadoop’s inability to analyze data to produce insights at the required scale, with the needed degree of concurrency, and at speed. Storing data on Hadoop was easy, but getting back insights at speed and scale has been a common problem expressed by many practitioners. Thus, Hadoop has been given the nickname “data jail”.
While there is a plethora of querying engines that are often faster than Hive, the default, and which claim to be faster than one another, performance is still far from people’s expectations. In addition, Hadoop projects often had no particular analytics strategy aligned with business needs and driven by tangible outcomes. The approach was to land all data in a data lake and hope that people would then come and derive insights the way they wanted.
This approach was not only applied to greenfield projects, but also to replace underperforming data warehouses. For the latter, data was typically extracted from multiple relational databases, denormalized, massaged in Hadoop, and eventually put back into data marts, to be served to analysts and data-consuming applications.
Another equally important reason for problems to have arisen is related to the complexity inherent to operating a Hadoop cluster, as well as developing applications. Skilled engineers are pretty scarce and expensive, so companies lacking an engineering/hacking culture had a high failure rate in comparison to technology startups.
Before moving to the next section, I would like to put a disclaimer here. There are undeniably companies that have succeeded with Hadoop. They have appropriately set expectations from the very beginning or quickly adjusted as they went through first failures, and they were able to align appropriate engineers and create a kind of Hadoop culture.
Slope of Enlightenment
I believe that this is the current status of Hadoop. As the trough of disillusionment is being exited, Hadoop enters a maturity phase, where it will be used for what it does best. However, the adoption rate will decline by an order of magnitude, compared to what was initially anticipated.
With failure comes a better understanding of the technology and the emergence of best practices. Early adopters have already gone through this process and have successfully tamed their Hadoop deployment. They have acknowledged that Hadoop is not the panacea for big data analytics and that a re-architecture effort has to be undertaken, in light of adjusted expectations, to either supplement Hadoop with other technologies – whether commercial or open source – or- in some extreme cases- replace Hadoop and write off their investment.
It is now generally accepted that Hadoop’s sweet spot is as a low-cost, high-volume storage platform with reliable batch processing. It is definitely not suitable for interactive analytics; but, with the advent of optimized data formats (ORC, Parquet) and query engines (Impala, Presto, Dremel…) performance has drastically improved, making it possible to analyze historical data with acceptable performance.
Plateau of Productivity
Here, companies are reaching a critical milestone in their journey, and they have to assess the realization of their investment in Hadoop in order to decide whether they should pull the plug or capitalize on their learnings to make it work and harness benefits.
Since this stage hasn’t yet been entered by mainstream users, I’ll just share emerging best practices that I learned from early adopters, and the trends I’m currently observing amongst the community of practitioners. As mentioned above, Hadoop evolved from distributed data storage and processing, namely HDFS and MapReduce, to a framework comprising multiple capabilities to address specific requirements dictated by the nature of the data and analytics needs. At the same time, data architects started to apply two key design principles: separation of concerns and data tiering (i.e. a mixture between data freshness and its associated value) to ensure distinct alignment between capabilities, requirements, and economics. Here are the outcomes:
- The first one came in the form of an “aha!” moment as users noticed that SQL and the relational model are actually a pretty powerful way to manipulate data, despite the buzz surrounding NoSQL technologies. It is indeed better to design a thoughtful data model and expose it to users via SQL, rather than a schema-less approach where analytics users will have to try to figure out the structure later. So relational databases – in which users have heavily invested, in terms of effort, infrastructure, and skills – are not going anywhere. The new generation of relational databases, called NewSQL, addresses the speed and scale issues that the previous generation suffered from. Unlike NoSQL, all of the key functionality – such as ACID compliance, relational structures, and comprehensive SQL support – are preserved, making for much better performance.
- Cloud is gaining traction as it offers a viable alternative to those being challenged by operational issues. All Hadoop capabilities exist on major clouds in the form of fully managed pay-as-you-go services. Being freed from the operational burden, users will now focus on architecting their data platform and experimenting with the vast amount of analytics capabilities to choose the most appropriate ones, as per the aforementioned design principles. Also available as a service on the cloud are full-stack analytics platforms with reintegrated storage and analytics components that only require customization. That being said, heavily-regulated industries won’t make a full jump to the cloud, so it seems that the future is about managing data in a hybrid fashion, both on-premises and on multiple clouds.
- HDFS is seeing its lunch being eaten by object storage, not only in the cloud, but also on-premises, with technologies such as MinIO, Pure Storage, and Scality. More specifically, AWS S3 is now considered as the de-facto standard for object storage, and vendors are seeking compatibility with that protocol. An S3 emulation layer on top of HDFS could allow Hadoop users to continue to take advantage of their investment.
- An initial architecture for historical data analytics is becoming a common pattern amongst the early adopters. It consists in dumping all data exhaust on HDFS and batch processing it using Hive or SPARK to structure it, perform a first level of aggregation, and eventually produce ORC or Parquet files. Based on the performance requirements, data volume, and economics, those files are either analyzed in place with query engines, or moved to a first-tier NewSQL database (this is often referred to as ‘Hadoop augmentation’). Although this approach provides interactive analytics capabilities, it is not suitable for use cases with real-time requirements, because data is batch-processed in Hadoop.
- For real-time analytics, the architecture that was just described should be supplemented with a stream processing flow to transform data as it arrives – from a Kafka queue, for instance. The two processing systems are working in parallel and asynchronously to populate two tables that are eventually merged at query time. This architecture is known as Lambda Architecture. Recently, it has been simplified into the form of a single processing flow that is fast enough to handle both batch and real-time, known as Kappa Architecture.
- With the rise of HOAP platforms (Hybrid Operational Analytic Processing), this architecture will be further simplified by keeping the operational store in-synch (via CDC) with operational systems in transactional mode, as well as in an append-only mode with a Kafka bus, while performing transformations on the fly and serving complex analytics queries – SQL, on a relational model – to multiple users. As data is aging, it is automatically cooled down in a historical analytics store, and eventually moved to a data lake. In addition to having a policy-based data management capability to move data from one tier to another, these systems also allow for ‘data continuity’; i.e., data in a table can be spread across several tiers, but users only query that single table.
Again, those are my own observations and recommendations. Hadoop has evolved from a technology platform to a ‘way of doing things,’ leveraging building blocks in the data storage and manipulation space. Its adoption will continue, but at a slower rate, and with more realistic expectations as to capabilities, cost, and business outcome.
If you have another view on how Hadoop will reach the plateau of productivity, or you would like to add other design patterns for data architectures to the discussion, please feel free to share in the comments.










