
Support teams often waste valuable time hunting through endless documentation. What if you could give them instant, accurate answers instead?

By building an automated Retrieval-Augmented Generation (RAG) system with LangChain, OpenAI and SingleStore, you can have a smart, searchable knowledge base up and running in just an hour. The result? Your agents receive the right information instantly, reducing their workload and allowing them to focus on solving real problems.
What is Retrieval-Augmented Generation (RAG)?
RAG combines two powerful steps to give smarter, more accurate answers:
- Vectorize. Turn your documents into numerical vectors (embeddings) so that similar content lives close together in “vector space.”
- Retrieve. When a support question comes in, RAG quickly searches the vector store for the most relevant chunks of information.
- Generate. Finally, it feeds those retrieved snippets into a generative model (like OpenAI’s API) to craft a precise, natural-sounding answer.
Why RAG beats basic FAQ bots
- Dynamic responses. Instead of matching fixed questions and answers, RAG builds each reply on the fly, using the freshest data.
- Broader coverage. It can draw on your entire knowledge base, not just a limited list of pre-written FAQs.
- More accurate. By grounding generation in real documents, RAG reduces hallucinations and keeps answers factual.
Why LangChain, OpenAI + SingleStore?
- LangChain provides easy-to-use building blocks for chaining together vector search, prompt templates and API calls, so you don’t have to wire everything from scratch.
- OpenAI delivers high-quality, flexible language generation that can be tuned with few-shot examples or system prompts for your support style.
- SingleStore stands out as a super-fast vector database; it stores millions of embeddings and returns search results in milliseconds — even under heavy load.
Key solution parts
- SingleStore vector store. A highly performant database to store and query your document embeddings.
- Converting docs into embeddings. A simple Python script reads your PDF guides and help articles, then calls an embedding API to vectorize each text chunk.
- Python module to generate answers. A reusable module that ties everything together: it takes a user query, retrieves top matches from SingleStore then asks OpenAI to generate a final, customer-ready response.
With these pieces in place, your support team gains instant access to the right information; no more manual digging — just fast, reliable answers.
Business + support team benefits
Implementing a RAG system brings clear benefits for both your business and support teams. Agents can cut their ticket handling time by half. Rather than digging through multiple documents, they pull exactly the snippets they need and spend twice as long resolving customer issues. Because every newly published help article or ticket log is immediately indexed, the answers generated are always accurate and up-to-date, never relying on stale information.
And whether you’re processing ten queries or ten thousand at once, the pipeline scales seamlessly, keeping response times fast and ensuring neither agents nor customers experience any slowdown.
Real-world case studies
- LinkedIn customer service (RAG + knowledge graph). In “Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering”, LinkedIn reports a 28.6% reduction in median issue resolution time after six months of deploying their RAG system.
- Minerva CQ (real-time RAG with FAQ fallback). The paper “Beyond-RAG: Question Identification and Answer Generation in Real-Time Conversations” describes deployment at Minerva CQ, where agents began receiving model-assisted answers within two seconds, significantly cutting Average Handling Time (AHT) and boosting customer satisfaction.
Launch AI-driven features. Without hitting limits.
- Free to start.
- Start building in minutes.
- Run transactions, analytics & AI.
Technical deep dive + architecture
Our RAG pipeline is designed to handle every stage of support data processing, from raw documents to polished answers, with efficiency and reliability:
Data ingestion
First, we gather every piece of support knowledge PDF manuals, Markdown how-tos and exported ticket histories. A lightweight Python script processes each file, splitting long documents into manageable, 512-token chunks and normalizing the text.
Embedding + storage
Once the text is clean, we call OpenAI’s embedding API to convert each chunk into a 1,536-dimensional vector. These embeddings capture the semantic meaning of the text, so related concepts like “reset password” and “forgot password” sit close together in vector space. We then insert the vectors plus metadata (source file, document section, original text snippet) into a SingleStore table with a dedicated VECTOR column, and secondary indexes on metadata fields for fast filtering.
Query workflow
When an agent or end-user submits a support query through a chat widget or ticket form, our Python module springs into action. It first issues a k-nearest-neighbors search against SingleStore, combining semantic similarity with optional metadata filters (for example, only pulling content from the last six months of tickets). In under 100 ms, it returns the top five chunks most relevant to the query.
Answer generation
Next, LangChain stitches those chunks into a templated prompt that instructs OpenAI’s completion API: include the user’s question, the retrieved chunks and a few-shot example to set the tone and style. OpenAI then generates a concise, context-aware response that references the source chunks — ensuring factual accuracy and consistency with our support guidelines.
Tips for picking your vector store + embedding model
Vector store
- Low-latency ANN search. Look for support of efficient algorithms such as HNSW to keep query times under 100 ms.
- Hybrid and filtered search. Ensure the store can combine semantic (vector) and keyword queries and apply rich metadata filters (e.g. by date, ticket type or document source) to narrow results precisely.
Embedding model
- Balance quality vs. cost. Larger models give better semantic understanding but cost more per call
- Align embedding dimensions to your store’s index settings (e.g., 512, 1024, 1536)
- Consider fine-tuning your support data if you need extra accuracy
With this setup, you’re ready to empower your team with lightning-fast, highly accurate support answers built in Python, powered by LangChain, OpenAI and SingleStore.
Before we dive into building our RAG application from scratch, we’d like to let you know that a ready-to-use version is available in this GitHub repository. You can explore the code on your own and follow the instructions provided there to run the app.
In the following sections, we’ll walk through a simplified step-by-step implementation of the app, occasionally referencing the same repository for clarity.
Step 1. Set up your environment
In this first step, you’ll prepare your environment by setting up a SingleStore database, creating a local project directory and installing all necessary Python dependencies. You’ll then configure a virtual environment and define connection variables for SingleStore and OpenAI. With these basics in place, you’ll be ready to start building your RAG pipeline.
1. Log in to your SingleStore Portal account
2. Follow this guide to create your database
3. Then, on your local machine, create a project directory:
1mkdir rag-knowledge-base2cd rag-knowledge-base
4. Install Python (if you haven’t already)
5. Now, in a terminal pointing to the root directory of your project, create and activate a Python virtual environment by running the following commands:
1python3 -m venv ./.venv2source ./.venv/bin/activate
6. Install the required dependencies by running the following command in your terminal:
1pip install singlestoredb langchain langchain-community langchain-openai openai pypdf ijson "fastapi[standard]" python-dotenv
7. In the root of the project, create a .env and define the following variables:
1DB_HOST="<HOST>"2DB_USER="<USER>"3DB_PASSWORD="<PASSWORD>"4DB_PORT="<PORT>"5DB_NAME="<DATABASE_NAME>"6OPENAI_API_KEY="<OPENAI_API_KEY>"
If you don’t know how to get your connection parameters, see the “Retrieve database credentials” section in this guide.
8. Finally, create an app.py entry point file in the root directory of the project:
1touch app.py
Step 2. Establish database connection
In this step, you’ll create a simple database connector using environment variables to load your SingleStore credentials. By defining a db.py module, you establish a reusable connection object for all subsequent data operations. This setup ensures your application can interact with the vector store seamlessly.
To do that, create a db.py file at ./lib/db.py with the following content:
1# ./lib/db.py2 3import os4 5import singlestoredb as s26from dotenv import load_dotenv7 8load_dotenv()9 10db = s2.connect(11 host=os.getenv("DB_HOST"),12 user=os.getenv("DB_USER"),13 password=os.getenv("DB_PASSWORD"),14 port=int(os.getenv("DB_PORT", 3306)),15 database=os.getenv("DB_NAME"),16 results_type="dicts",17)
Step 3. Create tables
In this step, you’ll define the schema for storing your document chunks and their embeddings by creating a knowledge_embeddings table in SingleStore. Running the create_tables.py script sets up the necessary columns and indexes so you can efficiently insert and query embedding data.
1. Create a create_tables.py file in the root directory with the following content:
1# ./create_tables.py2 3from lib.db import db4 5def main():6 with db.cursor() as cursor:7 cursor.execute(8 """9 CREATE TABLE IF NOT EXISTS knowledge_base (10 id INT AUTO_INCREMENT PRIMARY KEY,11 source VARCHAR(255),12 text TEXT,13 embedding VECTOR(1536)14 )15 """16 )17 18if __name__ == "__main__":19 main()
2. Execute the script to create the tables by running the following command in your terminal:
1python create_tables.py
Step 4. Create embeddings
- Create a source directory at the root of your project. This is where you’ll store your source files (PDF, Markdown or TXT) that will be chunked, converted into embeddings and later used to retrieve relevant information in response to customer questions.
- Next, place a PDF, Markdown or TXT file that you want to use as your knowledge base into the directory you just created.
- Create a file at ./lib/embed.py and copy the code from this file.
- Create a create_embeddings.py file in the root directory and copy the contents from this file.
- Execute the script to create embeddings by running the following command:
1python create_embeddings.py
Step 5. Load embeddings
- Create a load_embeddings.py file in the root directory and copy the contents from this file.
- Execute the script to create embeddings by running the following command:
1python load_embeddings.py
This will load the generated embeddings into SingleStore for use in vector search.
Step 6. Implement API search endpoint
- Copy the contents of this file into your ./app.py file.
- Run the app by executing the following command in your terminal:
1python ./app.py
Then, open http://localhost:8000/docs in your browser and test the /ask API endpoint.
Usage example
We’ve integrated SingleStore’s documentation into the knowledge base, which allows us to ask questions like “what is SingleStore?” and get accurate answers.
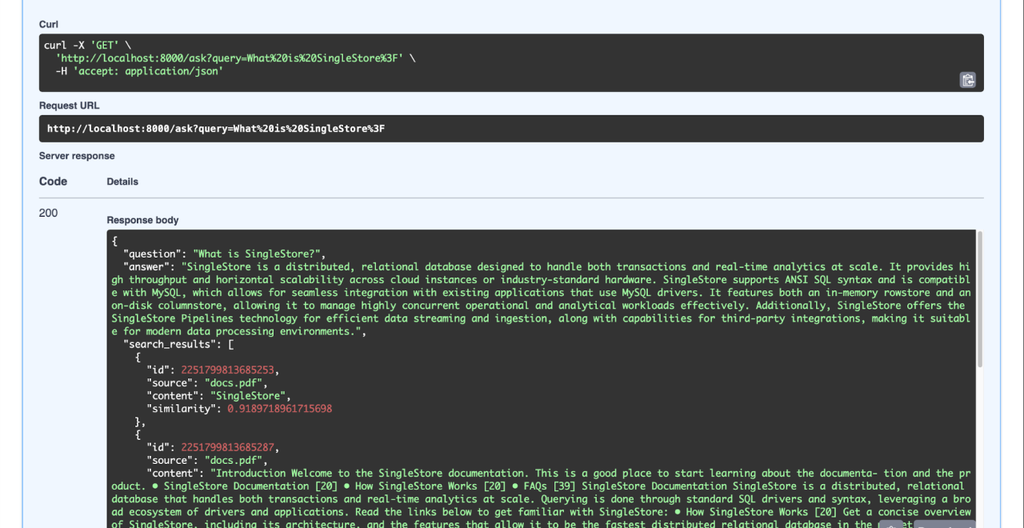
As demonstrated, the system provides fast and accurate responses to our query.
Next steps
This implementation serves as a basic example of how you can build your RAG-based knowledge bot, and integrate it into your server.
Based on this project, we recommend the following next steps:
- Add a cron task to periodically update your knowledge base with fresh content.
- Implement API endpoints to support chat functionality with conversation history and streaming.
- Integrate automatic support ticket creation, where each ticket includes a pre-generated answer based on the user's question.
Keep in mind SingleStore allows you to store not only vectors but also analytical, transactional and real-time data all within a single, unified platform. This enables you to significantly reduce infrastructure costs by eliminating the need for multiple separate services.
Conclusion
Building a RAG -powered knowledge base with Python, LangChain, OpenAI and SingleStore lets support teams deliver accurate, context-aware answers at scale. By chunking documents, converting them into embeddings and storing them in a high-performance vector database, you enable fast, semantic retrieval combined with generative AI.
Useful links
Frequently Asked Questions






-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)



