

Databases without data are pretty pointless. For SingleStoreDB, we’re trying to make the process of loading data into your databases as easy and seamless as possible.
To achieve that, we have been building a dedicated UI where users can load data into their database — from files stored in an S3 bucket — with a handful of clicks.
If you use our help menu, you should select “Load your data” > “Cloud Storage” > “AWS S3” and then the JSON or CSV option. The Load Data page can be found after that, on the first step of the data ingestion (see image 1):
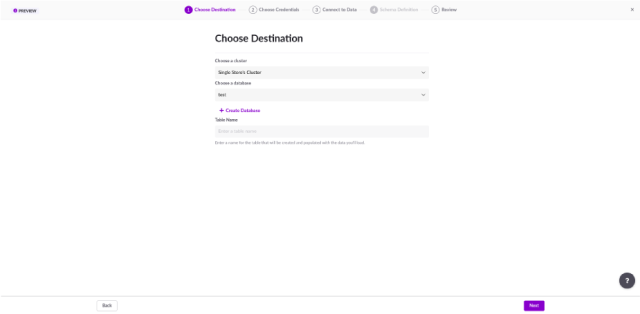
Image 1. First step: Choose which database and table to load data into
So, what do you need to ingest data into SingleStoreDB? Well, the first (and most obvious) is the location of your data. Your data must be in an AWS S3 bucket in the form of JSON or CSV files. In addition, you need to have a SingleStoreDB workspace up and running, and your AWS credentials in the form of an AWS access key/secret config (see image 2).
Your CSV files can have the structure you want — CSV or TSV files, with a custom data format, which you are able to define in the “Connect to Data” step (see image 3).
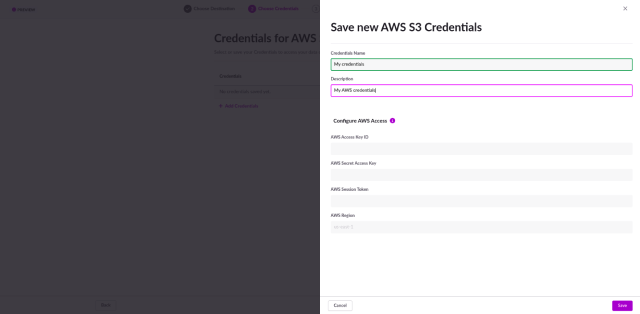
Image 2. Second step: Setup your AWS credentials
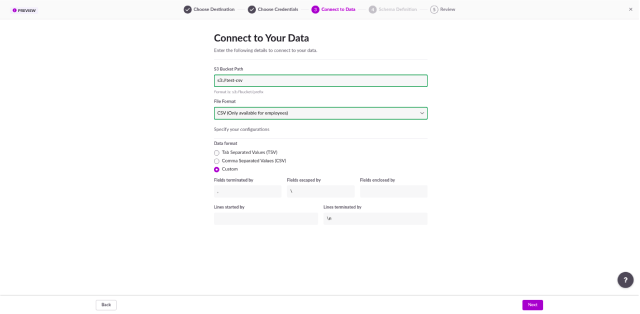
Image 3. Third step: Define the data you want to load, and its structure
After successfully loading the data file, your soon-to-be table will be displayed in the fourth step. On this page, you’re able to rename (or remove) as many columns as you want (see image 4).
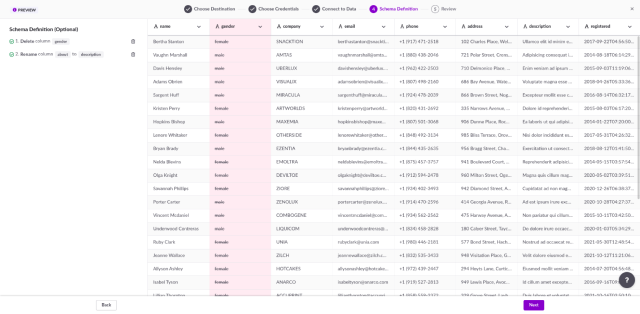
Image 4. Fourth step: Example of random data with two different operations
While we plan to support more kinds of operations in the future, these are the two currently available. On the left-hand side of your screen, you can see the changes you’re planning to make to your data when loading it to your table. This section is updated as you add or remove new operations.
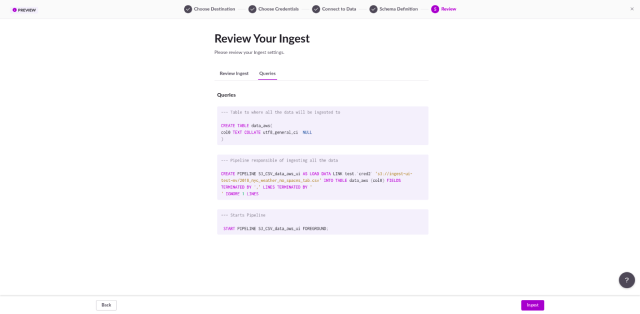
Image 5. Last step: SQL queries to ingest your data
When clicking “Next”, the last step is displayed (see image 5). Here, you can review the data information and take a sneak peek at the SQL queries that are going to be run against your database. If you want to, you can copy and use them as base queries for future changes.
After ingesting the data, two queries will be pasted in your SQL Editor. The first will select all the data from the new table, so you can ensure it was properly inserted. The second will retrieve the status of your data pipeline. Pipelines are a SingleStoreDB feature, used to load data from external sources to your database.
This UI is still in preview. As mentioned before, we plan to support other kinds of operations, other than renaming and removal, and support other sources and file types too. Stay tuned for that!
Eager to test it for yourself? Try SingleStoreDB free.

.png?width=24&disable=upscale&auto=webp)







