



Note: This is a preview feature that you can request access through Get Early Access
ML Functions allows you to train, deploy, and serve custom machine learning models using not just SQL. While AI Functions leverage the power of external foundational models for tasks like text completion and sentiment analysis, ML Functions enable you to build models tailored specifically to your unique data and business requirements.
The core philosophy remains unchanged: Bring the models to the data, not the data to the models. But now, instead of just accessing pre-trained models, you can create your own predictive engines that understand the nuances of your specific domain, all while maintaining the blazing-fast performance and real-time capabilities that SingleStore is known for.
From External Intelligence to Custom Intelligence
While AI Functions excel at leveraging the general-purpose intelligence of large language models for tasks like translation, summarization, and text generation, many business-critical use cases require models that learn from your specific data patterns. This is where ML Functions shine:
- Fraud detection systems that understand your transaction patterns and customer behavior
- Demand forecasting models trained on your historical sales data and market dynamics
- Anomaly detection engines that know what "normal" looks like in your specific environment
- Classification models that categorize your unique business entities with industry leading domain-specific accuracy
Guided Training with SQL Simplicity
The "No-ETL, No-Notebook" Workflow
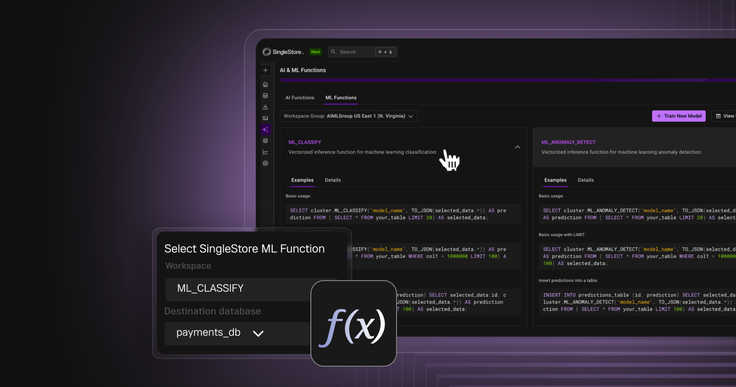
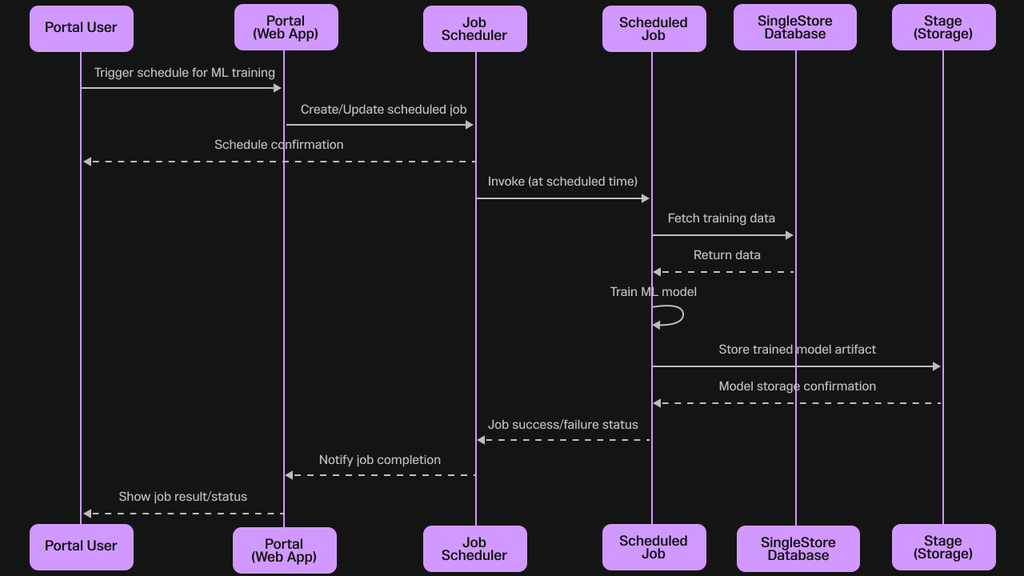
The journey to a production-ready model begins with a guided user interface (UI) experience within the SingleStore portal. This UI walks the user through selecting the source table, identifying the feature columns (the inputs), and specifying the target column (the value to be predicted). This guided process abstracts away the complexities of data preparation and model selection.Crucially, this UI-driven workflow culminates in the generation of a single, declarative SQL command. This design provides the best of both worlds: a simple, guided path for those who prefer a visual interface, and a scriptable, SQL-native command for developers and DBAs who need to automate training as part of a larger workflow or CI/CD pipeline. When executed, this SQL command creates a Scheduled Job for immediate execution that handles the model training asynchronously in the background
Once a model is trained and enabled, it is ready to be deployed into an optimized Python User-Defined Function (UDF) container running within the SingleStore Aura service. The trained model is loaded and cached in memory, making it immediately available to serve low-latency predictions.
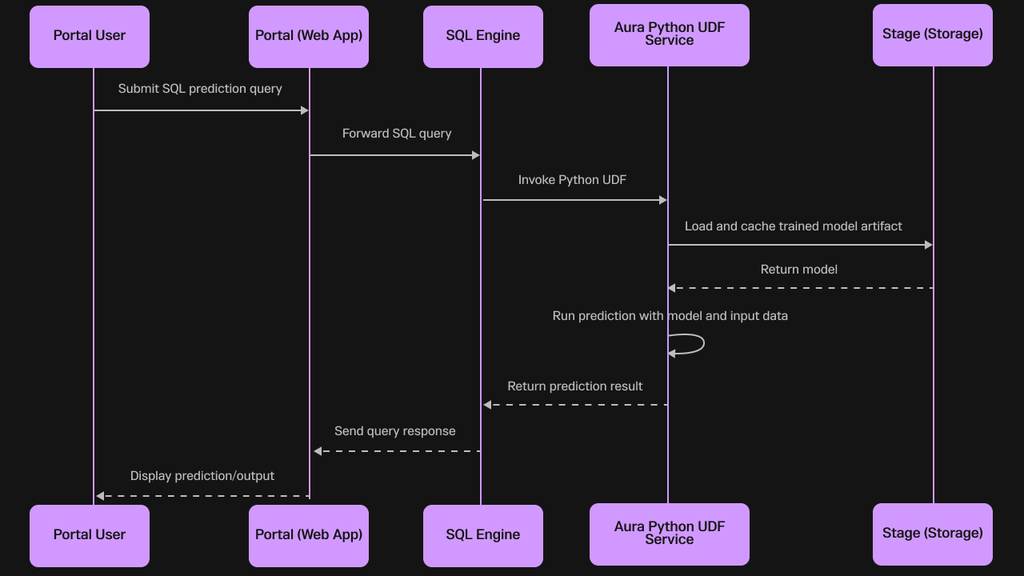
This co-location of the model and the data is what enables true real-time predictive performance, a cornerstone of SingleStore's architectural advantage.
Initial suite of ML functions
Note: Refer to our documentation to determine the latest syntax for using ML functions as this will be tweaked based on customer feedback and ease of use
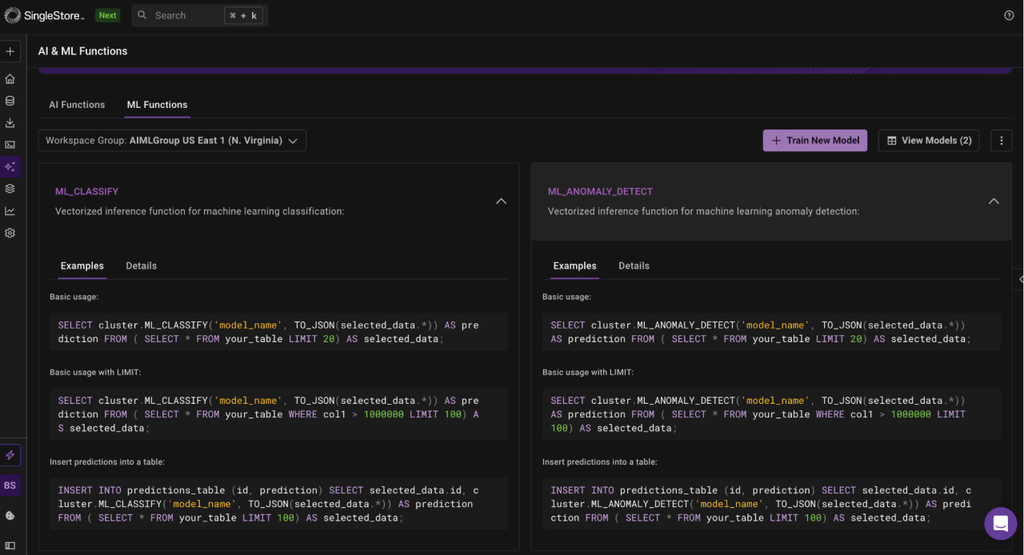
The initial suite of ML Functions includes three powerful prediction capabilities:
ML_CLASSIFY: Predicts a categorical label. Ideal for use cases like lead scoring or fraud detection.
1SELECT2 customer_id,3 aura.ML_CLASSIFY(4 'lead_conversion_model',5 lead_source,6 website_visits7 ) AS conversion_prediction8FROM new_leads;
ML_ANOMALY_DETECT: Identifies outliers in data. Perfect for monitoring IoT sensor streams or detecting unusual financial transactions.
1SELECT2 device_id,3 timestamp,4 aura.ML_ANOMALY_DETECT(5 'motor_anomaly_model',6 time,7 vibration8 ) AS is_anomaly9FROM sensor_stream;
ML_FORECAST: Predicts future values in a time series. Essential for inventory management and demand planning.
1-- Predict the next 14 days of sales for a specific SKU2SELECT3 sku_id,4 ML_FORECAST('sku_sales_forecaster_v1', time, target) AS next_14_day_forecast5FROM product_catalog6WHERE sku_id = 'A123';
The Architecture of Trust: Built-in Monitoring for Production-Grade ML
Deploying a machine learning model is not the end of the journey; it is the beginning. A common failure point in enterprise ML initiatives is the "Day 2 problem": models need to be retrained to reflect the current data patterns. They are trained on a historical snapshot of the world, and as business conditions, customer behaviors, and data patterns change, a model's performance inevitably degrades over time. Without monitoring, this degradation happens silently, leading to inaccurate predictions, poor business decisions, financial losses, and an erosion of trust in the entire ML system.
Recognizing this critical challenge, SingleStore ML Functions were designed with a comprehensive, integrated MLOps framework from day one. Monitoring is not an optional add-on but a core component of the feature, providing continuous visibility into model health across four key pillars: Data Integrity, Data Stability, Predictive Performance, and Model Trustworthiness.
A Deep Dive into the Pillars of Model Health
AutoCraft ML : Advanced Automatic ML modeling capabilities for automatic feature engineering and hyperparameter optimization. Each monitoring metric provides a specific lens through which to view model performance, enabling proactive management rather than reactive failure analysis.
Data Integrity: Missing / Malformed Fields %
- What It Is: This metric tracks the percentage of incoming prediction requests that contain data quality issues, such as unexpected null values, incorrect data types, or schema violations.
- Why You Should Care: The "garbage in, garbage out" principle is fundamental to machine learning. If an upstream data pipeline breaks or an application starts sending malformed data, the model's inputs become nonsensical, rendering its predictions completely unreliable. This metric is the first line of defense for the entire ML system.
- Playbook: A sustained error rate above 0% is a critical alert. The immediate action is to investigate upstream data sources, ETL jobs, or application code that generates the prediction requests. This often points to a recent schema change or a bug in a data-producing service.
Data Stability: Input Drift Score (Population Stability Index - PSI)
- What It Is: Population Stability Index (PSI) is a statistical metric that quantifies how much the distribution of live, incoming data has shifted away from the distribution of the data the model was originally trained on. It essentially measures if the model is seeing a new kind of data in production.
- Why You Should Care: A model's predictions are only reliable if the input data it sees in production resembles the data it learned from during training. If, for example, a new marketing campaign attracts a completely different customer demographic, the patterns the model learned about previous customers may no longer be valid. High data drift is a powerful leading indicator of future performance degradation.
- Playbook: PSI values are typically interpreted using established thresholds. A PSI value below 0.1 indicates no significant change. A value between 0.1 and 0.2 suggests a moderate shift that requires monitoring. A PSI value exceeding 0.2 indicates a significant population shift and serves as a strong signal to trigger a model retrain using the newer, more representative data.
Predictive Performance: Rolling F1 Score / RMSE
- What it is: These are near-real-time measures of a model's predictive accuracy, calculated on a rolling window of recent predictions for which the actual outcomes (ground truth) are known.
- F1 score. Used for classification models, it calculates the harmonic mean of precision and recall. This provides a more balanced measure than simple accuracy, especially when dealing with imbalanced datasets (e.g., fraud detection, where fraudulent transactions are rare).
- Root Mean Square Error (RMSE). Used for regression and forecasting models, it measures the average magnitude of the prediction errors in the same units as the target variable (e.g., dollars, units sold, degrees Celsius). It penalizes larger errors more heavily.
- Why you should care: This is the ultimate measure of business value. Is the model making correct predictions on live data? A sudden drop in the F1 score or a spike in RMSE indicates that the model's performance is actively degrading and impacting business outcomes.
- Playbook: A significant drop in performance (e.g., a 10% decrease versus a 7-day median) is a high-severity alert. This could be caused by concept drift, a fundamental change in the relationship between the input features and the outcome. The immediate action may be to roll back to a previously deployed, more stable model version while investigating the root cause.
Model Trustworthiness: Expected Calibration Error (ECE) - coming soon
- What It Is: ECE measures how well a model's stated confidence aligns with its actual accuracy. In other words, if a model predicts a set of outcomes with "90% confidence," are those predictions actually correct 90% of the time? A perfectly calibrated model has an ECE of 0.
- Why You Should Care: Model calibration is critical for risk-based decision-making. For example, a fraud detection system might be configured to automatically block transactions only when the model's confidence is above 95%. If the model is poorly calibrated and overly confident, it will generate a high number of false positives, blocking legitimate transactions and frustrating customers. Trustworthy confidence scores are essential for building reliable automated systems.
- Playbook: A high ECE indicates that the model's probability outputs cannot be trusted at face value. This may necessitate a recalibration step (such as temperature scaling) or retraining the model with a different algorithm or objective function that optimizes for calibration.
Operational Economics: Cost per 1 million Predictions
- What It Is: A straightforward operational metric that tracks the cloud infrastructure and compute costs associated with serving predictions from the model.
- Why You Should Care: This serves as a crucial guardrail to ensure that the economic value generated by the model's predictions outweighs its operational cost. A sudden spike in cost could indicate an inefficient query pattern, a misconfiguration, or an unexpected surge in prediction requests.
- Playbook: If costs exceed a defined budget, the playbook involves optimizing the SQL queries that call the prediction function, exploring batching of low-priority requests, or adjusting the underlying compute resources allocated to the UDF container. By preparing this comprehensive suite of monitoring metrics you can have a production-ready solution.
Real-World Use Cases
Use Case 1: Predicting Customer Survival in Insurance
Goal: Build a custom classification model to predict policy renewal likelihood based on customer demographics and interaction history.
Solution: Using ML_CLASSIFY, train a model on historical customer data to identify patterns that predict renewal behavior.
1# Train the model with historical customer data2%s2ml train Classification3 --model 'customer_retention_model_v1' \4 --db 'insurance_db' \5 --input_table 'policy_info' \ 6 --target_column 'renewed_policy' \7 --description 'Classify if a customer will renew their policy' \8 --runtime 'cpu-small' \9 --selected_features '{"mode":"*", "features":"null"}'
Now use this model directly in your SQL queries as
1-- Once trained, use the model for predictions2SELECT 3 customer_id,4 ML_CLASSIFY('customer_retention_model_v1', age, income, claim_history, contact_frequency) as renewal_prediction5FROM new_customers;
Use Case 2: Real-Time Fraud Detection
Goal: Detect fraudulent transactions immediately as they occur, using patterns learned from historical transaction data.
Solution: Combine ML_CLASSIFY for risk scoring with ML_ANOMALY_DETECT for unusual pattern identification.
1# Train fraud detection model2%s2ml train Classification \3 --model 'fraud_classifier' \4 --db 'payments_db' \5 --input_table 'transactions' \6 --target_column 'is_fraud' \7 --description 'Classify transaction fraud risk' \8 --runtime 'cpu-medium' \9 --selected_features '{"mode":"*", "features":"null"}'10 11# Train anomaly detection for unusual patterns12 13%s2ml train AnomalyDetection \14 --model 'transaction_anomaly_detector' \15 --db 'payments_db' \16 --input_table 'payments' \17 --target_column 'transaction_amount' \18 --description 'Detect unusual transaction patterns' \19 --runtime 'cpu-small' \20 --selected_features '{"mode":"*","features":null}' \21 --target_time_column 'transaction_date'
After training use the model as
1-- Real-time fraud assessment2SELECT 3 transaction_id,4 ML_CLASSIFY('fraud_classifier', amount, merchant_category, time_of_day, user_location) as fraud_score,5 ML_ANOMALY_DETECT('transaction_anomaly_detector', amount, frequency) as anomaly_flag6FROM live_transactions7WHERE fraud_score > 0.8 OR anomaly_flag = 1;
Use Case 3: Inventory Demand Forecasting
Goal: Predict future inventory needs based on seasonal patterns, promotions, and market trends.
Solution: Use ML_FORECAST to create time-series predictions that account for multiple influencing factors
1# Train forecasting model on historical sales data2%s2ml train Forecast \3 --model_name 'inventory_forecaster' \4 --db 'retail_db' \5 --input_table 'sales' \6 --target_column 'daily_sales' \7 --timestamp_column 'sale_date' \8 --description 'Forecast daily sales for inventory planning' \9 --runtime 'cpu-medium' \10 --selected_features '{"mode":"except","features":["id"]}'\ 11 --target_time_column ts
Once trained you can use the model as
1-- Generate forecasts for next 30 days2SELECT 3 product_id,4 forecast_date,5 ML_FORECAST('inventory_forecaster', forecast_date, product_category, seasonal_factor) as predicted_demand6FROM product_calendar 7WHERE forecast_date BETWEEN CURDATE() AND DATE_ADD(CURDATE(), INTERVAL 30 DAY);
Getting Started with ML Functions
As we improve this feature the syntax and capabilities are expected to change, head over to our dedicated documentation for ML functions to use the latest valid ML function syntax.
Ready to build your first custom ML model? Here's how to get started:
1. Access the ML Functions UI
Navigate to the ML Functions section in your SingleStore Cloud Portal AI&MLFunctions page and make sure these functions are enabled for your Org.
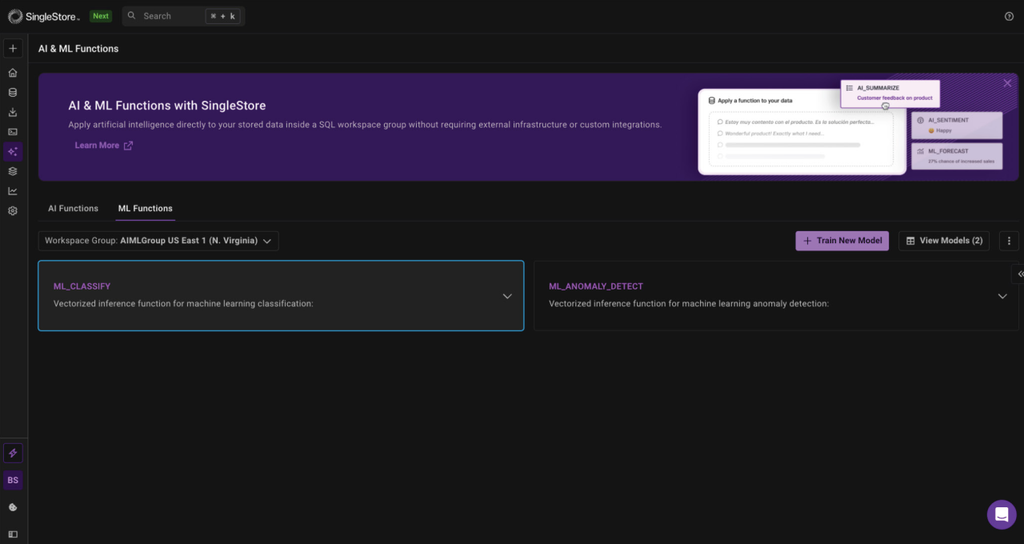
- See example usage by clicking on ML training type card
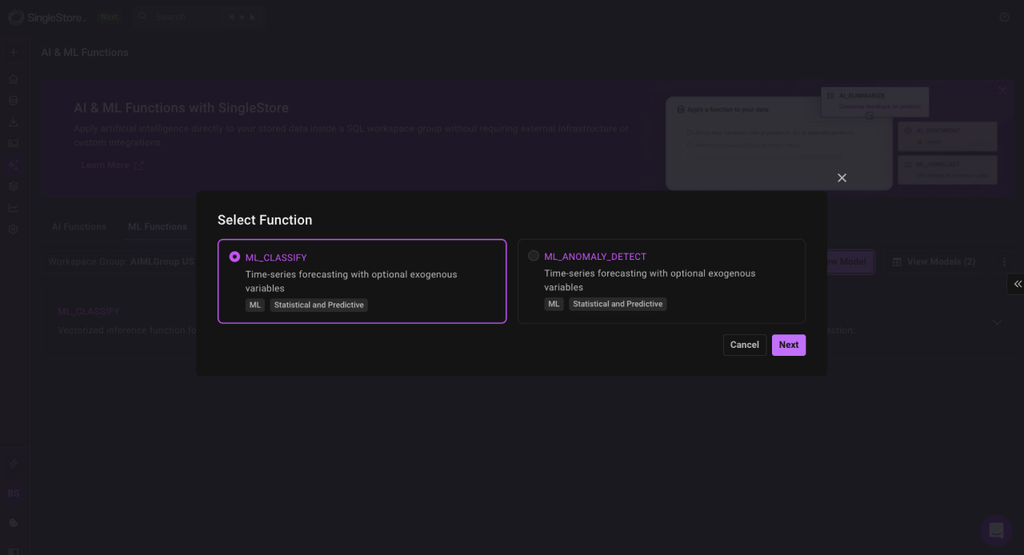
2. Configure Your Training Job
- Pick your model type: Classification, anomaly detection, or forecasting ( More ML operation types will be added in the future )
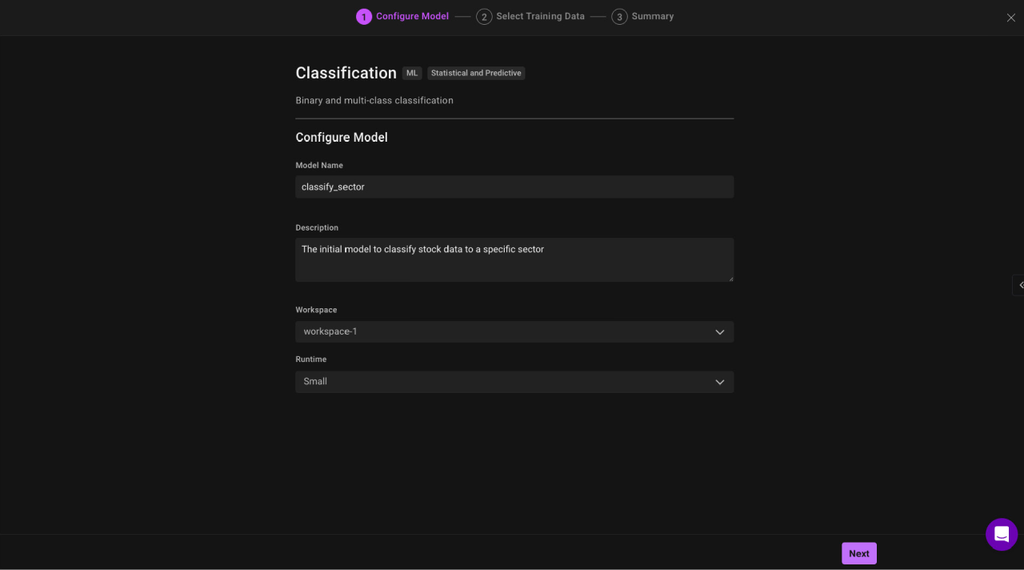
- Name and describe your model
- Select the workspace in this which this model would connect to fetch the source data
- Select the compute size to train this model with
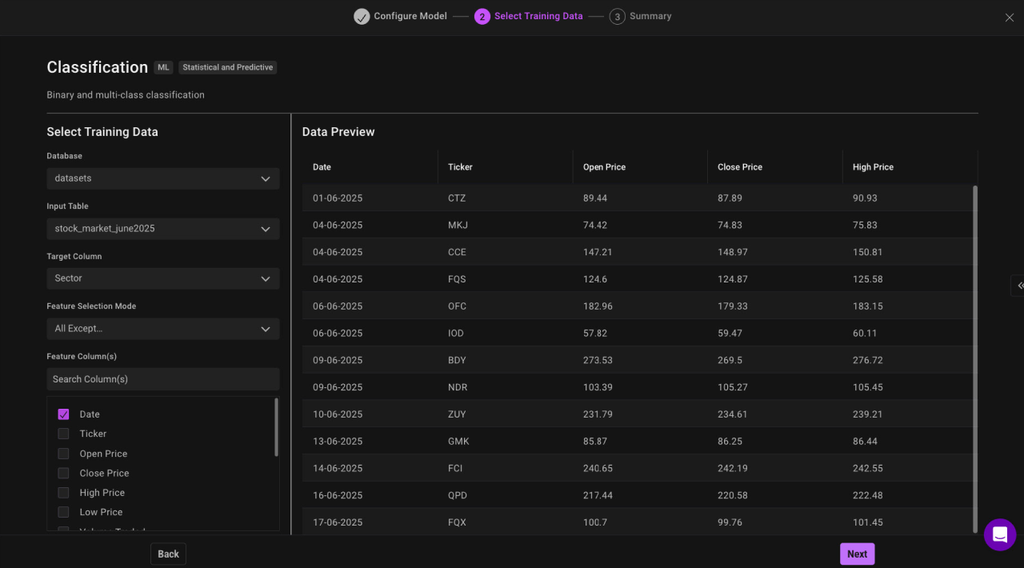
- Choose your data source: Select the table containing your training data
- Define your target: Specify what column you want to predict or classify
- Select features: Choose which columns to use as input features
Finally view the specific magic command that will be called to trigger the ML model training after clicking on Start Training button
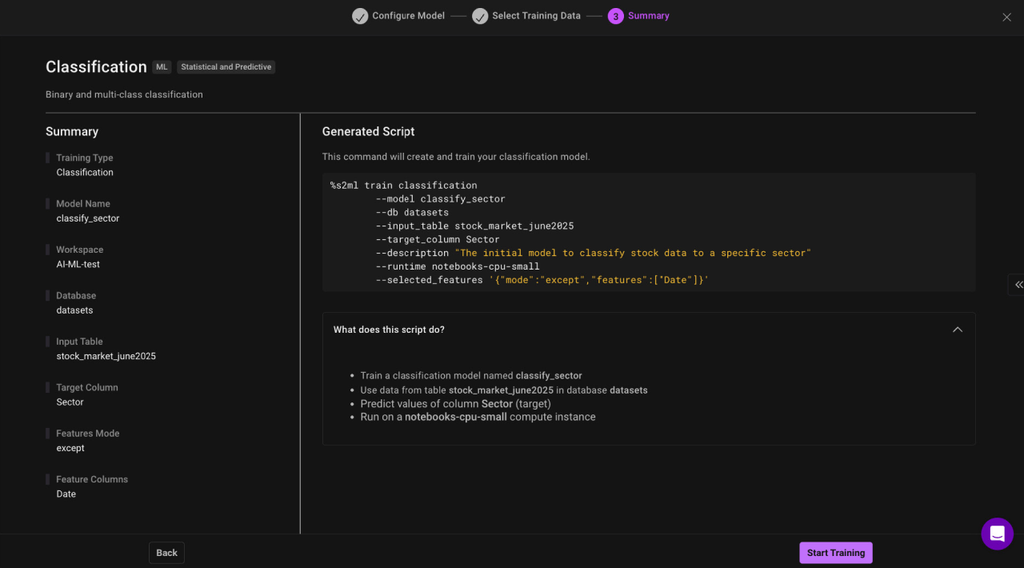
3. Monitor Training Progress
Watch as SingleStore automatically handles data preprocessing, feature engineering, model training, and validation—all through scheduled jobs that leverage our distributed computing infrastructure powered by Aura.
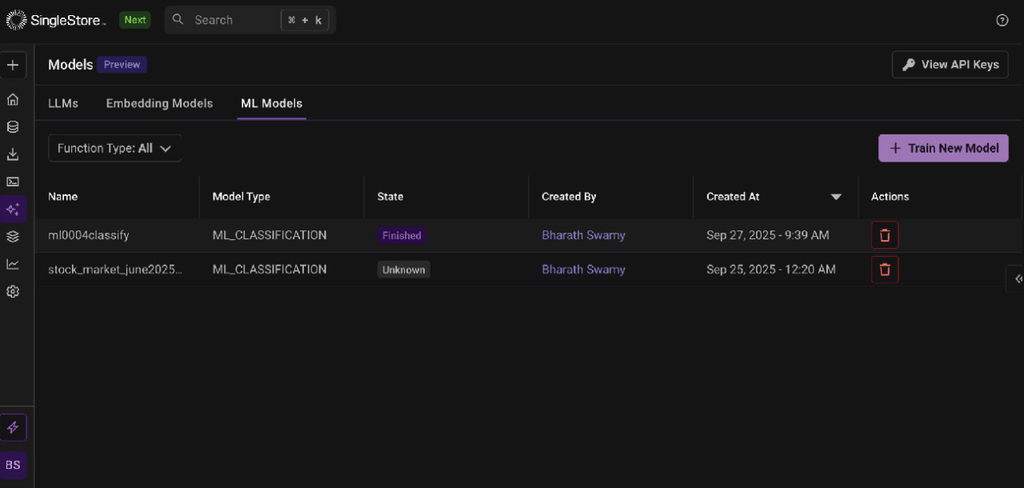
Additionally, you can also check the status of your training with the following command from a python notebook
1%s2ml status --model 'classification_model_1' --type 'json'
4. Deploy and Predict
Once training completes, your model is immediately available for inference through simple SQL queries, delivering predictions with the same low-latency performance as our AI Functions.
Some of the useful python magic commands that can help with identifying and managing models include
1# Show model metadata2%s2ml show --name fitness_classification_cell_magic_v1 --type df3 4# List models 5%s2ml list --type df
Why ML Functions Matter Now
In an era where data moves faster than ever and business requirements change overnight, the ability to quickly build, deploy, and iterate on custom machine learning models has become a competitive necessity. ML Functions eliminate the traditional barriers between data teams and machine learning teams, enabling:
- Faster time-to-insight with models that understand your specific business context
- Reduced operational complexity by keeping models co-located with data
- Real-time decision-making powered by millisecond-latency custom predictions
- Seamless integration with existing SQL-based workflows and applications
The future belongs to organizations that can turn their unique data into unique intelligence. With ML Functions, that future is now accessible through the universal language of SQL.
The Future of In-Database Machine Learning
ML Functions represent just the beginning of SingleStore's vision for democratizing machine learning. Looking ahead, our roadmap includes:
- Hybrid ML approach : use ML to make AI do better.
- Model versioning and A/B testing directly within the database
- Integration with popular ML frameworks for bringing existing models into SingleStore
- Advanced ensemble methods that combine multiple custom models
- Real-time model retraining based on performance monitoring alerts
- Tools for AI agent workflows : allows agents to call ML functions for their workflows
Ready to transform your data into custom intelligence? Reach out to our support team to get early access to ML Functions and start building models that understand your business as well as you do.
Frequently Asked Questions












.jpg?width=24&disable=upscale&auto=webp)