One of the most valuable features a distributed system can have is predictability. When a system is predictable, you can reason about how it will respond to changes in workload. You can run small-scale experiments, and trust that the results will scale linearly. It’s much more pleasant and efficient to tailor the hardware to the task than the other way around. No one likes to waste money on more compute than you need because your RAM is full, or be unable to use the full power of your systems because of an I/O bottleneck. In this article we will walk through a few scenarios and rules of thumb for sizing a SingleStore database cluster.
“The biscuits and the syrup never come out even.” — Robert Heinlein
All reads and writes in SingleStore flow through “aggregator” servers to many “leaf” servers. Each CPU core on each leaf can be thought of as its own instance of SingleStore, talking only to aggregators. Under normal operation, each aggregator is also acting independently. As inserts are sent to a randomly chosen aggregator, their shard keys are hashed and the data is sent to the relevant leaves. Select queries for particular keys are sent only to the relevant leaves, and selects or joins across entire tables are executed in parallel across the cluster.
A shared-nothing architecture has many nice properties. The network behavior is easy to reason about because there is no cross-talk between leaves; a badly-written query can’t suddenly cause congestion on the network. You can use inexpensive in-server storage for durability instead of an expensive SAN. The bandwidth and parallelism of disks directly attached to your leaf servers scales linearly with the size of your cluster — no I/O bottlenecks from many servers fighting over the same shared drives.
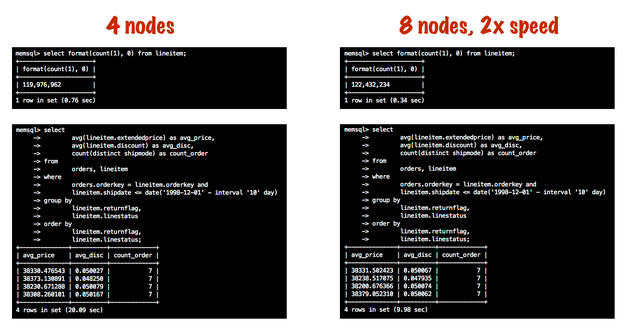
Latency is also easy to reason about. Let’s say you have a small database: 120 million records spread over 4 leaves. If it takes 700 milliseconds to do a full table scan, then adding 4 more leaves will almost certainly make your queries twice as fast.
Durability is handled with replication across leaves, disk journaling, and snapshots. All of that is separate from the business of answering your queries. It’s actually pretty difficult to push your SingleStore cluster into a state in which query times exhibit high variability due to I/O contention or locking; the CPU maxes out first.
An easy fix for a highly-parallel CPU-bound system, of course, is to add more CPU. The only question is where. As a rule of thumb, writes tend to be bottlenecked on the aggregators and reads on the leaves. The mix of reads to writes determines the optimal mix of aggregators to leaves. If you expect a fairly high input volume, e.g. over 50,000 inserts / 50MB per second per leaf, a ratio of 2-3 aggregators to 8 leaves is a good starting point. If you have a very high sustained rate of inserts, consider using most of your aggregators exclusively for write traffic and keep some apart to handle reads. This reduces contention at the aggregator layer and helps keep read and write latencies predictable.
And that is the key to capacity planning for your SingleStore cluster. There’s no need to be psychic. You can measure and find out. If you are not sure how many servers you need for a given workload, try a test on a few servers with 1/10 or 1/20 of the total dataset. Have to choose between server types with different amounts of CPU and RAM? Run a quick test on similar hardware in the cloud, and see what happens. Unlike most databases, especially systems with excessive coupling between nodes, scaling up your SingleStore performance testing is straightforward.
[1] The only exceptions are DDL and cluster management commands, which can only be run the master aggregator.
[2] One exception is a query that sends a lot of data to the aggregator. Running “select distinct user_id” on a very large table, for example. This is a problem no matter what database you use because it tries to send a cluster-worth of data down a single narrow pipe. In general you want to bring the computation to the data, not the data to the computation.
_feature.png?height=187&disable=upscale&auto=webp)




