
Retrieval-Augmented Generation (RAG) and AI agents have become a go-to architecture for enabling Large Language Models (LLMs) to solve proprietary data queries. Accuracy and security, however, pose challenges, and in the enterprise, accuracy and security aren't just “nice to have” — they’re non-negotiable. Financial records, healthcare data and legal documents are mission critical. Traditional RAG systems based on purpose-built, vector-only databases fall short in ensuring both accuracy and security, and add to complexity and cost by forcing companies to integrate yet another database into their overall data infrastructure.
Protecto solves for these limitations and helps its customers de-risk gen AI with its GPTGuard product, which provides data guardrails for enterprise AI agents to prevent data leaks, privacy violations and compliance risks in AI automation. The company is establishing itself as the only guardrail in the market that provides a crucial advantage: securing sensitive data without reducing LLM accuracy.

Challenges/goals
The key challenges in this area are the shortcomings of traditional RAG architectures — and that enterprises often choose to try to address them with purpose-built, pure-play vector databases.
Traditional RAG architectures and their limitations
Most standard RAG systems follow a straightforward pipeline: they segment documents into smaller sections and embed each section using a model like OpenAI’s Ada, or Cohere. These embeddings are then stored in a vector database. At query time, a user prompt is embedded, and a similarity search is performed to fetch Top-K (top_k) matching document chunks and pass them to the LLM to generate a final answer. “While effective for low-risk public datasets or narrow use cases,” explained Baskaran Alagarsamy, Co-Founder and Chief Technology Officer, Protecto, “this traditional approach fails when applied to enterprise data,” for a number of reasons:
Vector-only search misses key context. In turn, thisaffects the quality of LLM responses. It treats every chunk equally, missing important signals from document metadata like department, access restrictions or legal classifications.
Access controls are hard to enforce. Vector databases typically aren't built to understand access control lists (ACLs) or role-based document restrictions (i.e., Role-Based Access Control, or RBAC), leading to potential data exposure risks.
Semantic + structured keyword search is challenging. Combining semantic similarity with structured filters (e.g., “Find invoices from 2024 mentioning vendor X”) is nearly impossible without extensive post-processing outside the database.
Inflexible search method. Pure vector search relies heavily on Approximate Nearest Neighbor (ANN) indexing, making it difficult to prioritize retrieval completeness (recall) over speed when completeness matters for a use case.
These limitations become critical blockers in enterprise settings where compliance, traceability and security are top priorities.

Why generic vector databases fall short for secure RAG
Pure-play vector databases prioritize speed and scale, but leave significant gaps in areas critical to enterprise AI:
| Problem | Impact |
| Lack of hybrid search support | Can't combine semantic search with metadata or ACL enforcement |
| No native structured query support | Difficult to filter based on document tags, ownership or classifications |
| External joins often required | Introduces performance bottlenecks and sync failures |
| Fixed indexing strategies | Can't toggle between approximate search and brute-force recall based on use case |
| Poor auditability | Hard to explain why a certain chunk was retrieved, which is critical for compliance-heavy industries |
In practice, enterprises either have to build heavy custom middleware layers to stitch retrieval and access control together — or accept significant compromises in security and retrieval precision. Neither is sustainable.
Technology requirements
Protecto needed a data platform that could overcome the limitations of pure-play vector databases by quickly and easily performing complex relational queries; and beyond that, one that could combine vector search with full-text search to accurately and securely execute complex hybrid search and document retrieval.
Why SingleStore
“SingleStore brings a unique dimension to hybrid search. Unlike pure-play vector databases, which struggle with complex relational queries, SingleStore integrates vector search within a robust SQL database,” added Alagarsamy:
Powerful hybrid queries. SingleStore seamlessly joins vector similarity search results with traditional text match scores, document metadata and document access control lists. By contrast, pure-play vector databases — which are designed primarily for nearest neighbor searches — lack the ability to perform these complex joins efficiently. This fundamental limitation makes them unsuitable for GPTGuard's requirements.
Unified data management. SingleStore's ability to store and query both vector embeddings and structured metadata within the same database eliminates the need for complex data synchronization and external joins. This integrated approach is essential for GPTGuard, where real-time access to accurate and contextually rich data is crucial.
Granular control and customization. SingleStore provides granular control over vector search indexing. For example, cosine similarity calculations can be customized during ETL to significantly optimize performance. These capabilities are not typically available in the abstracted environments of pure-play vector databases.
Accuracy vs. performance. SingleStore provides granular control over vector search indexing, allowing GPTGuard to prioritize accuracy over performance when necessary. Critically, SingleStore allows GPTGuard to opt out of vector indexing entirely as needed, performing brute-force searches when maximum accuracy is paramount. This flexibility is essential for sensitive document retrieval where recall is more important than speed. By contrast, pure-play vector databases often mandate indexing methods, forcing a trade-off in accuracy.
SingleStore brings a unique dimension to hybrid search. Unlike pure-play vector databases, which struggle with complex relational queries, SingleStore integrates vector search within a robust SQL database.
Baskaran Alagarsamy, Co-Founder and Chief Technology Officer, Protecto
Solution
Protecto’s approach to RAG starts much earlier in the pipeline: at document ingestion, in GPTGuard, running on SingleStore Helios. When a document is uploaded into GPTGuard, the product automatically:
Identifies and masks sensitive data like PII, PHI and financial identifiers — before storage or retrieval.
Performs deep entity extraction, generating a rich attribute repository per document that tags extracted entities like account numbers, contract dates, patient IDs, legal clauses and more.
Creates structured metadata, using the extracted entity information to link each document chunk with its embedding as well as with searchable, filterable attributes like account numbers, names and emails.
This metadata-driven approach ensures retrieval can simultaneously be semantic (embedding-based) and structured (SQL-based).
“We chose SingleStore to support this innovative architecture because of its native hybrid query capability,” said Alagarsamy. “SingleStore stores both the vector embeddings and the structured metadata in a unified database, enabling efficient real-time queries without needing external joins.” As a result, GPTGuard can issue complex retrievals like:
“Fetch all documents tagged as ‘Contracts’, created after Jan 2024, mentioning VendorX, and semantically similar to the query ‘termination clauses’ — but only if the user belongs to the Legal department.”
Traditional vector-only systems simply cannot perform this type of hybrid retrieval without expensive and fragile architecture workarounds.
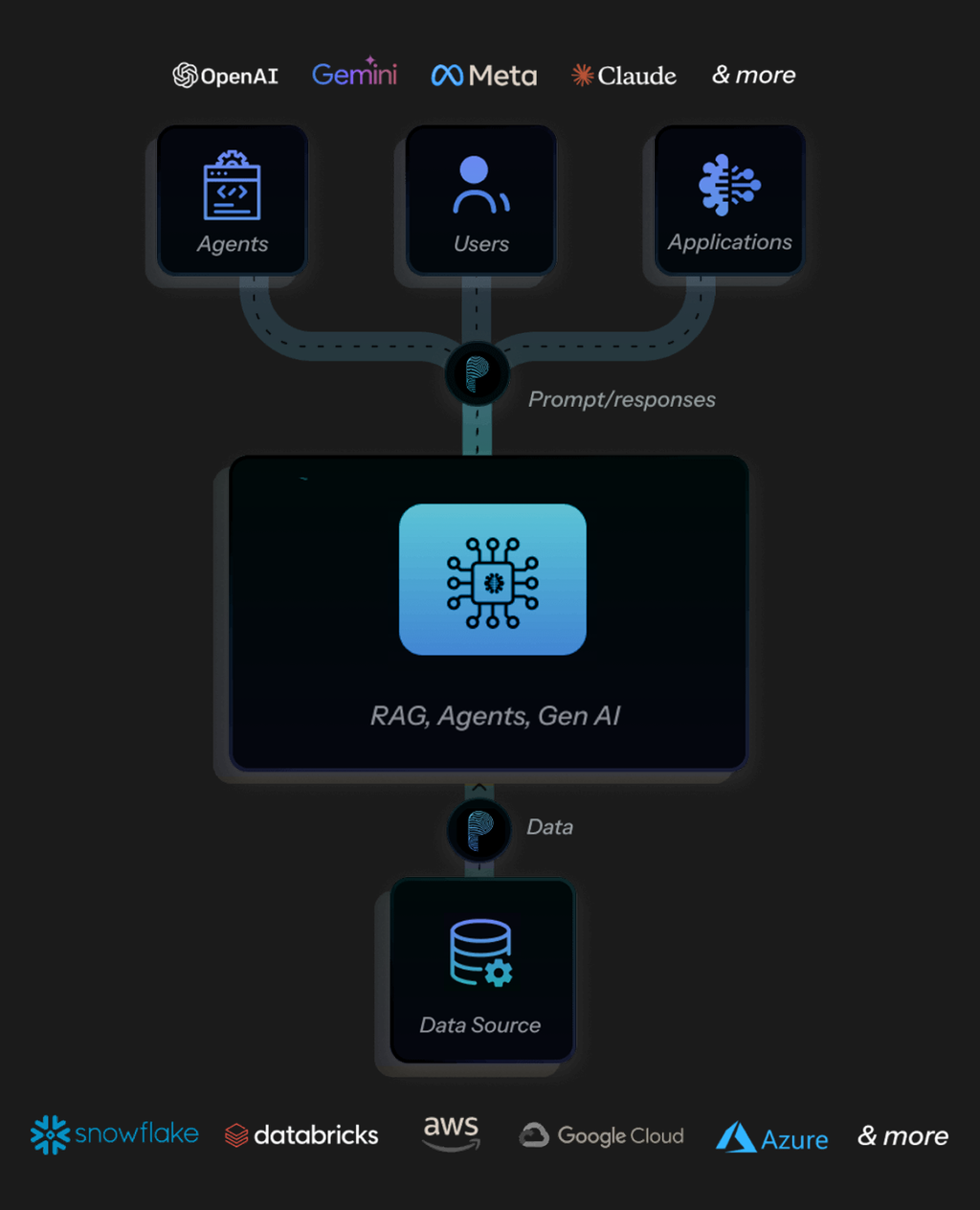
Outcomes
By deeply integrating entity-aware document intelligence (Protecto) with hybrid vector and structured retrieval (SingleStore), GPTGuard delivers a fundamentally different kind of RAG system — one built for enterprises, not just prototypes. Protecto's automated attribute generation empowers SingleStore's hybrid search capabilities. SingleStore's robust database functionalities allow GPTGuard to leverage Protecto's rich document metadata effectively. This combination enables GPTGuard to deliver:
Highly accurate and relevant search results
Enhanced security through automated PII/PHI masking
Efficient and scalable document retrieval
Advanced hybrid search, addressing the limitations of pure-play solutions
Automated workflow
By harnessing the distinct strengths of Protecto and SingleStore — and by overcoming the critical limitations of pure-play vector databases — GPTGuard sets a new standard for precision and power in AI-driven document retrieval.
“This isn’t just an improvement over traditional vector-only systems,” concluded Alagarsamy. “It's a complete rethinking of what enterprise-grade RAG needs to be.”
Learn More About GPTGuardStart a free trialExplore SingleStoreLearn more about Protecto
SingleStore is helping companies compete and win across every vertical. Learn more →
Explore how GPTGuard, powered by Protecto and SingleStore, enables safe, accurate and scalable gen AI inside the enterprise:
Frequently Asked Questions













