

SingleStore Streamliner is now generally available! Streamliner is an integrated SingleStore and Apache Spark solution for streaming data from real-time data sources, such as sensors, IoT devices, transactions, application data and logs.
The SingleStore database pairs perfectly with Apache Spark out-of-the-box. Apache Spark is a distributed, in-memory data processing framework that provides programmatic libraries for users to work with data across a broad set of use cases, including streaming, machine learning, and graph data processing. SingleStore and Spark share many design principles: they are in-memory, distributed, and data-centric. Spark provides an amazing interface to the unique functionality in SingleStore: fast and durable transactions, a real-time hybrid row/column-oriented analytics engine, and a highly concurrent environment for serving complex SQL queries.
The SingleStore Spark Connector, released earlier this year, allows Spark and SingleStore integration, facilitating bi-directional data movement between Spark and SingleStore. The connector generated a lot of interest from users who saw the benefits of using Spark for data transformation and SingleStore for data persistence. A consistent theme in the use cases we saw was the desire to use Spark to stream data into SingleStore with Spark Streaming. SingleStore Streamliner is the result of our work to productize this workflow into an easy, UI-driven tool that makes this process dead simple.
Let’s review the thinking behind some of the decisions we made as we were developing Streamliner.
Early work with Pinterest
Pinterest showcased a Kafka+Spark+SingleStore solution in Strata+Hadoop World last February, which was a collaborative effort with SingleStore. See the Pinterest blog post and the Pinterest demo to learn more. The Pinterest solution leveraged Spark Streaming to quickly ingest and enrich data from Kafka, and then store it in SingleStore for analysis.

The Kafka, Spark, and SingleStore solution, spurred by the Pinterest showcase, identified the market’s need for a simple solution to capture data streams from Kafka and other real-time inputs into a persistent, data serving endpoint. In other words, there was a need for a streamlined (pun intended) experience that captured the power of Spark Streaming behind an intuitive UI. The Streamliner concept was born.
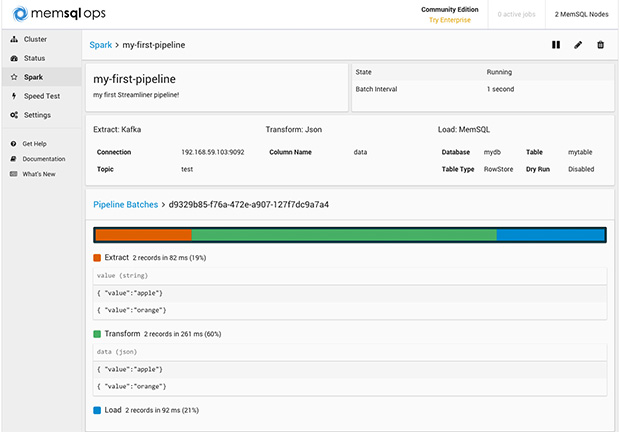
Streamliner Engineering
Streamliner was built to make this process of building a real-time data pipeline seamless and intuitive. The underlying technologies – SingleStore and Spark – already existed, but combining them to build real-time data pipelines was still a nontrivial exercise. Users just wanted to “paste” a Kafka URL into the browser and get started with querying their data, but could not easily do so prior to Streamliner. Earlier experiences required writing code to build a data pipeline from Kafka, into Spark for processing, and out of Spark for persistence.
Key features of Streamliner
A Simple, Pipeline-oriented UI
In the SingleStore Ops dashboard, the Streamliner page allows users to easily add new streaming pipelines to the system, do it online, and for the most part, do it without writing any code!
Resource Sharing
Based on our experience working with Pinterest, static resource allocation per stream (the standard paradigm in Spark) was not practical at scale. A robust and cost-effective solution requires multiple pipelines to overlap on and share the same set of resources, which is now handled out of the box in Streamliner.
Very Simple Points of Extensibility
We noticed clear patterns with how our users were loading data and developed two abstractions in Streamliner – Extractors and Transformers – which allow users to extend the system. Extractors define new sources (discretized streams) of data, and Transformers transform raw data (bytes) into structured or semi-structured data (data frames). Extractors and Transformers are configurable and composable, making it easy for users to create and reuse common elements across pipelines without writing additional code.

Tracing
Visibility into each of the pipeline phases is necessary for debugging. Streamliner allows users to see results inline for a few batches of data. Streamliner also collects and formats pipeline exceptions and exposes them in the UI, so users don’t have to dig through logs to find where things went wrong.
Advanced Columnstore Functionality Optimized for Data Streaming
SingleStoreDB Self-Managed 4.1 allows streaming data directly into the columnstore (no need for batched writes) and columnar compression on JSON data (backed by Parquet). These are new features in SingleStoreDB Self-Managed 4.1, whose release coincides with Streamliner.
Spark Installation
Another hurdle to productivity with Spark has been installation. Spark is complex to install, as it is a sophisticated data processing framework and requires knowledge of Java and Scala. Streamliner was designed with easy installation as a top priority, and can be used right away without writing any code or installing a development environment. SingleStore Ops already has the ability to install the SingleStore database with a click of a button. With Streamliner, Spark deployment is also just one click away.
Streamliner and a library of example Extractors and Transformers are open source and available immediately. You can get started right away by downloading the latest version of SingleStore Ops and following this tutorial. We are looking forward to seeing what pipelines people build and to participating in the open, vibrant community around Apache Spark.









