

People who are just learning about SingleStore often don’t believe that transactions and analytics can be unified into a single database. SingleStore Chief Product Officer Jordan Tigani walks through the steps, encompassing decades of engineering-years, explaining how we did it.
“What’s the tradeoff?” is the question I almost always hear when I posit that SingleStore can execute transactions and analytics concurrently, in the same database. When I insist there is no tradeoff, the next response is usually disbelief, even after I dutifully present benchmark results and customer testimonials.
Is it true? Should it be true, even? Relational database pioneer and A.M. Turing Award recipient Michael Stonebraker famously said that combining analytics and transactions in a single database was “an idea whose time has come and gone.” Many people hold the widespread belief that a database needs to be tuned for either one or the other. However, architectural breakthroughs have dramatically changed the database performance landscape; let’s not forget that almost 15 years ago, Stonebraker also argued that databases were ready for a complete rewrite.
This blog tells the story of how database unification can be done—proof that it’s not magical thinking. We did it at SingleStore in a series of small steps, each of which is difficult but tractable. Together, these steps have built a unified database that can execute transactions, analytics and more, all in the same engine with the same tables.
Establishing requirements
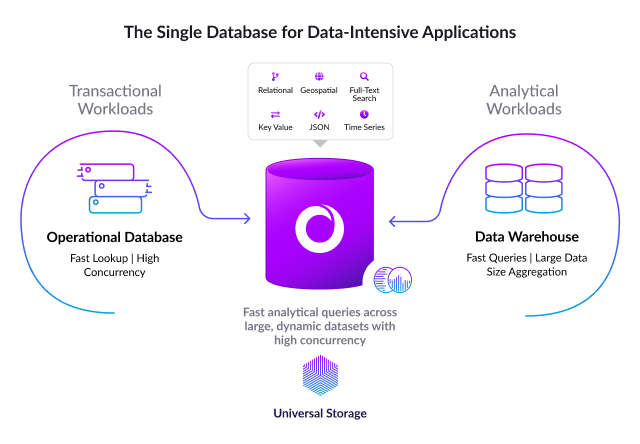
First, let’s understand the requirements for each function. A transactional database requires:
- Low latency inserts and updates (single-digit milliseconds)
- High concurrency, in the thousands or millions of transactions per second
- Low latency for point lookups (single-digit milliseconds)
- Distributed, scale out architecture
- Low latency joins
- High availability
- Durable, transactional updates (ACID)
In contrast, analytics require:
- High throughput scans (billions of rows per second)
- Fast aggregations, regardless of cardinality
- Fast fact/dimension joins for star-shaped schemas
- Scalable to petabytes of data
- Separation of storage and compute
Step by step: Building the system
Now let’s walk through the steps that SingleStore took. In theory, anyone could repeat the same process, although it might require a few engineering decades.
We started with a fast in-memory database. MemSQL (the company that preceded SingleStore) built a lightning fast in-memory database using lock-free skip lists rather than traditional b-trees. It’s pretty easy to see how an in-memory database can do low-latency inserts and lookups since you’re only touching memory. The skip lists also allow high concurrency because updates do not require any locking and they have row-level granularity for collisions. Dynamic code generation enables even better concurrency, reducing the amount of CPU work that needs to be done during the query.
Scaling out
Truly modern database architecture requires scale-out rather than scaling up. This can be accomplished by horizontally partitioning and adding master nodes to route the queries. Relational workloads require the ability to do joins without slowing performance. This can be done by adding co-partitioning, which allows joins within a single node without a shuffle, and reference tables, which replicate small tables to every node. You can also take a. more traditional approach like nested loop joins.
At this point, we have a lightning fast in-memory database but there is still a risk of data loss in the event of hardware failures or crashes. The system can be made highly available by replicating all writes synchronously to multiple nodes, with each partition residing on two or more physical hosts; these hosts can be split across availability zones or data centers, ensuring resilience to most outages.
SSD simplifies persistence
The key to making the database truly general purpose, rather than just an in-memory cache, is to add persistence and ACID transactions. Writing updates to a transaction log on solid-state drive (SSD) storage devices can achieve ACID transactions, with the log replayed if the system crashes or restarts. A redo log is often a significant performance bottleneck in a database, but modern storage hardware can come to the rescue, since writes to SSD can be done in parallel and with much lower latency than to magnetic disks.
The transaction log is only read at startup, so it is never in the critical path for reads. In addition, raw data must be written to disk as well as the transaction log, but this can be done lazily, since a rebuild is possible after a crash. Disaster recovery can be added by replicating the data synchronously or asynchronously to another location.
Now what? Steps toward analytics
By this point, you’ve got a kick-ass transactional database, likely more scalable and faster than most legacy systems on the market. You can achieve any level of durability desired, since there are multiple copies in memory on different physical hosts, and at least one copy in the transaction log on disk. How can analytics be added without slowing database performance for transactions?
Let’s start with the right on-disk data structure. Column stores typically give orders of magnitude better performance on analytical workloads because, in general, they need to read much less data than a row store; most queries only have to read a few columns, and data within columns is generally highly compressible. Together, these two factors can reduce I/O by orders of magnitude.
Applying some optimizations to the column store can help it be even faster. For example, SingleStore added vectorization to reduce CPU time, push down predicates to the storage layer to read even less data, and perform some operations over compressed data directly.
An analytical system needs more than scans. It also needs to do fast, parallel aggregations, but this is pretty straightforward. Distributed query engines like Dremel have long used additional workers for aggregations, with computations organized in a tree structure and aggregations flowing up the tree. SingleStore’s master nodes are ideal for performing these aggregations. The co-partitioning we added for transactional joins helps make fact-fact joins very fast, while broadcast and hash shuffle joins address other types of star schema joins.
Extracting more from the column store
Column stores are not commonly used in transactional systems because they can be more difficult to update, making a single-row lookup expensive. However, because SingleStore can do most operations in memory without having to read or write data from disk, it can use a column store as the physical storage format, delivering fast scans for analytics without impacting most transactional operations.
The column store can also be adapted for better performance on transactional workloads, when the data we need is not already in memory. Column stores generally do badly when being updated one row at a time, since much of their performance stems from the ability to compress large ranges of data together.
Instead, SingleStore treats the on-disk column store as a write-back cache. When a row is modified, SingleStore reads the block it is in from SSD into memory, does the update via the in-memory skip list, and then writes it back out in the background. If the update pattern has locality, the first step can be avoided, since the block will already be in memory. In this way, SingleStore can do high concurrency updates with minimal performance impact. Durability is not impacted because the transaction log is persisted on each transaction.
Keeping latency low
The next challenge is how to keep low latency for lookups, even when not all of the data is in memory. This is where most analytical databases fail, since they’re optimized for scans rather than seeks. SingleStore has made lookups fast, even in a column store, by building fast seekability into the data format. This may sacrifice a few percentage points of compression ratio but allows a jump right to the spot needed without scanning the whole file.
Moreover, SingleStore creates indexes for the column store, telling you exactly where to find a key. You can also persist key metadata in memory, allowing you to find the necessary block in the column store with only a single SSD read.
Scaling the final frontier
Having solved nearly all of our challenges—fast transactions, fast analytics, availability and durability—the only capability missing is scalability. Modern data warehouses need to be able to scale to petabytes, with storage and compute scaling independently.
Separation of storage and compute is the norm for today’s large-scale analytical databases, particularly in the cloud. Two-tier storage ensures that latency-sensitive operations are almost completely satisfied from the top tier. Following the same principles, SingleStore added a third tier that writes to object store (AWS S3, Google Cloud Storage, Cohesity, etc.), thus allowing storage to scale, essentially, infinitely. Object store blobs get paged in as needed and, with working set in local SSD, object store reads or writes are never on the critical path for any operation.
If the entire database fits on local SSD, operation will be virtually identical to that without the object store. With SingleStore there is never a cache miss on reads because all reads are out of SSD. As noted, it can do writes in the background, keeping them out of the critical path.
Importantly, SingleStore’s architecture is different from most other data warehouses using object stores because it uses a write-back cache rather than a write-through. This results in lower latency because the object store doesn’t need to be updated synchronously with every write. In addition, SingleStore’s approach makes performance much more consistent, since object storage operations have high tail latency and don’t suffer from fragmentation.
The sum of the parts
Granted, each of the individual pieces is hard to build, requiring significant engineering effort. Building an in-memory database is no easy feat; durability, separation of storage and compute, global versioning, two-phase commit, and indexable column store are all hard challenges to solve without impacting performance. But it can be done—a system can be built that delivers excellent performance in processing both transactional and analytical workloads. SingleStore is proof that it’s not just possible, it’s an idea whose time is right now, and downright magical.
Keep up with our latest tech updates on SingleStore’s new Twitter channel for developers @SingleStoreDevs.
Try SingleStore for free.







-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)


