
This blog post was originally published in January 2014, and it has long been the first blog post on the SingleStore blog – and one of the best. In this blog post, SingleStore co-founding engineer Adam Prout explains one of the key technical features that distinguishes SingleStore: its use of skiplist indexes over Btrees and similar structures. Adam has now revised and updated this blog post to include the recently released SingleStoreDB Self-Managed 7.0 and SingleStore Universal Storage™.
The most popular data structure used for indexing in relational databases is the Btree (or its variant, the B+tree). Btrees rose to popularity because they do fewer disk I/O operations to run a lookup compared to other balanced trees. To the best of my knowledge, SingleStore is the first commercial relational database in production today to use a skiplist, not a Btree, as its primary index backing data structure for in-memory data.
SingleStore, founded in 2011, began as an in-memory, rowstore database. SingleStore’s storage design evolved, in the years following, to support on-disk data in columnstore format. We then added more intelligence around when rows are stored in memory vs. on disk, and in rowstore or columnstore format, with the Universal Storage project. Through all this, the skiplist has remained the index of choice for in-memory rowstore data.
A lot of research and prototyping went into the decision to use a skiplist. I hope to provide some of the rationale for this choice, and to demonstrate the power and relative simplicity of SingleStore’s skiplist implementation. I’ll show some very simple single-threaded table scans that run more than eight times faster on SingleStore, compared to MySQL, as a very basic demonstration. (SingleStore performs even better than this on more aggressive and complex workloads). This article will stick to high-level design choices and leaves most of the nitty-gritty implementation details for other posts.
What is a Skiplist?
Btrees made a lot of sense for databases when the data lived most of its life on disk and was only pulled into memory and cached as needed to run queries. On the other hand, Btrees do extra work to reduce disk I/O that is needless overhead if your data fits into memory. As memory sizes have increased, it is feasible today to support indexes that only function well for in-memory data, and are freed from the constraints of having to index data on disk. A skiplist is well suited for this type of indexing.
Skiplists are a relatively recent invention. The seminal skiplist paper was published in 1990 by William Pugh: Skiplists: a probabilistic alternative to balanced trees. This makes the skiplist about 20 years younger than the Btree, which was first proposed in the 1970s.
A skiplist is an ordered data structure providing expected O(Log(n)) lookup, insertion, and deletion complexity. It provides this level of efficiency without the need for complex tree balancing or page splitting like that required by Btrees, redblack trees, or AVL trees. As a result, it’s a much simpler and more concise data structure to implement.
Lock-free skiplist implementations have recently been developed; see this paper, Lock-Free Linked Lists and Skiplists, published in 2004 by Mikhail Fomitchev and Eric Ruppert. These implementations provide thread safety with better parallelism under a concurrent read/write workload than thread-safe balanced trees that require locking. I won’t dig into the details of how to implement a lock-free skiplist here, but to get an idea of how it might be done, see this blog post about common pitfalls in writing lock-free algorithms.

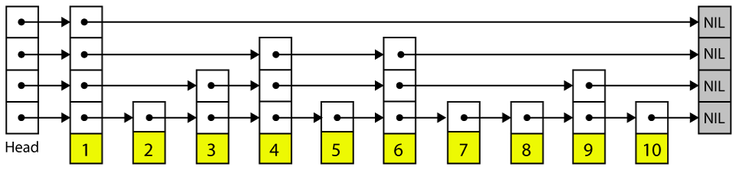
A skiplist is made up of elements attached to towers. Each tower in a skiplist is linked at each level of the tower to the next tower at the same height, forming a group of linked lists, one for each level of the skiplist. When an element is inserted into the skiplist, its tower height is determined randomly via successive coin flips (a tower with height n occurs once in 2^n times).
The element is linked into the linked lists at each level of the skiplist, once its height has been determined. The towers support binary searching by starting at the highest tower and working towards the bottom, using the tower links to check when one should move forward in the list or down the tower to a lower level.
Why a Skiplist Index for SingleStore
There are many reasons why skiplists are best for SingleStore, primarily: they’re memory-optimized, simple (including the need for many fewer lines of code to implement them), much easier to implement in a lock-free fashion, fast, and flexible.
1) Memory-Optimized
SingleStore supports both in-memory rowstore and on-disk columnstore table storage. The rowstore is designed for fast, high-throughput access to data stored in memory. The columnstore is designed for scanning and aggregating large amounts of data quickly. The columnstore is disk-backed but keeps recently written data in-memory in rowstore layout before flushing it to disk in columnstore layout.
The columnstore also stores all metadata about files in memory, in internal rowstore metadata tables – i.e, metadata such as maximum and minimum values of each column, a bitmap of deleted rows, etc. This data is needed in memory for fast and easy access by query execution for eliminating entire files from a filter. See our documentation for more information about our columnstore.
These two storage types are being converged by the SingleStore Universal Storage project to create a storage design with most of the benefits of both table types, while eliminating the need to think about the details of storage layouts when designing and managing an application. Thus, both of SingleStore’s table types have a need for a memory-optimized rowstore index, as does our future ideal design of a Universal Storage table type. (You can see a deep dive on Universal Storage from Eric Hanson, and some useful information about our current and future implementation of Universal Storage in Rick Negrin’s webinar.)
Being memory-optimized means indexes are free to use pointers to rows directly, without the need for indirection. In a traditional database, rows need to be addressable by some other means than a pointer to memory, as their primary storage location is on disk. This indirection usually takes the form of a cache of memory-resident pages (often called a buffer pool) that is consulted in order to find a particular row’s in-memory address, or to read it into memory from disk if needed.
This indirection is expensive and usually done at the page level (e.g., 8K at a time in SQL Server). SingleStore doesn’t have to worry about this overhead. This makes data structures that refer to rows arbitrarily by pointer, like a skiplist does, feasible. Dereferencing a pointer is much less expensive than looking up a page in the buffer pool.
2) Simple
SingleStore’s skiplist implementation is about 1500 lines of code, including comments. Having recently spent some time in both SQL Server’s and Innodb’s Btree implementations, I can tell you they are both close to 50 times larger in terms of lines of code, and both have many more moving parts. For example, a Btree has to deal with page splitting and page compaction, while a skiplist has no equivalent operations. The first generally available build of SingleStore took a little over a year to build and stabilize. This feat wouldn’t have been possible with a more complex indexing data structure.
3) Lock-Free
A lock-free or non-blocking algorithm is one in which some thread is always able to make progress, no matter how all the threads’ executions are interleaved by the OS. SingleStore is designed to support highly concurrent workloads running on hardware with many cores. These goals makes lock-free algorithms desirable for SingleStore. (See our description of sync replication, by Nate Horan.)
The algorithms for writing a thread-safe, lock-free skiplist are now a solved problem in academia. A number of papers have been published on the subject in the past decade. It’s much harder to make a lock-free skiplist perform well when there is low contention (ie., a single thread iterating over the entire skiplist, with no other concurrent operations executing). Optimizing this case is a more active area of research. Our approach to solving this particular problem is a topic for another time.
Btrees, on the other hand, have historically needed to use a complex locking scheme to achieve thread safety. Some newer lock-free, Btree-like data structures such as the BWtree have recently been proposed that avoid this problem. Again, the complexity of the BWTree data structure far outpaces that of a skiplist or even a traditional Btree. (The BWTree requires more complex compaction algorithms then a Btree, and depends on a log-structured storage system to persist its pages). The simplicity of the skiplist is what makes it well suited for a lock-free implementation.
4) Fast
The speed of a skiplist comes mostly from its simplicity. SingleStore is executing fewer instructions to insert, delete, search, or iterate compared to other databases.
5) Flexible
Skiplists also support some extra operations that are useful for query processing and that aren’t readily implementable in a balanced tree.
For example, a skiplist is able to estimate the number of elements between two elements in the list in logarithmic time. The general idea is to use the towers to estimate how many rows are between two elements linked together at the same height in the tree. If we know the tower height at which the nodes are linked, we can estimate how many elements are expected to be between these elements, because we know the expected distribution of towers at that height.
Knowing how many elements are expected to be in an arbitrary range of the list is very useful for query optimization, when calculating how selective different filters in a select statement are. Traditional databases need to build separate histograms to support this type of estimation in the query optimizer.
Addressing Some Common Concerns About Skiplists
SingleStore has addressed several common concerns about skiplists: memory overhead, CPU cache efficiency, and reverse iteration.
Memory Overhead
The best-known disadvantage of a skiplist is its memory overhead. The skiplist towers require storing a pointer at each level of each tower. On average, each element will have a tower height of 2 (we flip a coin in succession to determine the tower height, such that a tower of height n occurs 1 in 2^n times). This means, on average, each element will have 16 bytes of overhead for the skiplist towers.
The significance of this overhead depends on the size of the elements being stored in the list. In SingleStore, the elements stored are rows of some user’s table. The average row size in a relational database tends to be hundreds of bytes in size, dwarfing the skiplist’s memory overhead.
BTrees have their own memory overhead issues that make them hard to compare directly to skiplists. After a BTree does a page split, both split pages are usually only 50% full. (Some databases have other heuristics, but the result of a split is pages with empty space on them).
Depending on a workload’s write patterns, BTrees can end up with fragmented pages all over the BTree, due to this splitting. Compaction algorithms to reclaim this wasted space are required, but they often need to be triggered manually by the user. A fully compacted BTree, however, will be more memory-efficient than a skiplist.
Another way SingleStore is able to improve memory use compared to a traditional database is in how it implements secondary indexes. Secondary indexes need only contain pointers to the primary key row. There is no need to duplicate the data in key columns like secondary Btree indexes do.
CPU Cache efficiency
Skiplists do not provide very good memory locality because traversing pointers during a search results in execution jumping somewhat randomly around memory. The impact of this effect is very workload-specific and hard to accurately measure.
For most queries, the cost of executing the rest of a query (sorting, executing expressions, protocol overhead to return the queries result) tends to dominate the cost of traversing the tower pointers during a search. The memory locality problem can also be mostly overcome by using prefetch instructions (mm_prefetch on Intel processors). The skiplist towers can be used to read ahead of a table scan operation and load rows into CPU caches, so they can be quickly accessed by the scan when it arrives.
Reverse Iteration
Most skiplist implementations use backwards pointers (double linking of list elements) to support iterating backwards in the list. The backwards pointers add extra memory overhead and extra implementation complexity; lock-free, doubly-linked lists are difficult to implement.
SingleStore’s skiplist employs a novel reverse iterator that uses the towers to iterate backwards without the need for reverse links. The idea is to track the last tower link that is visited at each level of the skiplist while seeking to the end, or to a particular node, of the skiplist. These links can be used to find the element behind each successive element, because each time the reverse iterator moves backwards, it updates the links at each level that are used.
This iterator saves the memory required for backwards pointers, but does result in higher reverse-iteration execution cost. Reverse iteration is important for a SQL database because it allows ORDER BY queries to run without sorting, even if the ORDER BY wants the opposite sort order (ie, ascending instead of descending) of the order the index provides.
Quick Performance Comparison
Performance benchmarking of databases and data structures is very difficult. I’m not going to provide a comprehensive benchmark here. Instead, I’ll show a very simple demonstration of our skiplist’s single-threaded scan performance compared to innodb’s Btree.
I’m going to run SELECT SUM(score) FROM users over a 50 million-row users table. The test is set up to, if anything, favor MySQL. There is no concurrent write workload in this demonstration (which is where SingleStore really shines), and SingleStore is running with query parallelism disabled; both MySQL and SingleStore are scanning using only a single thread. Innodb is running with a big enough buffer pool to fit the entire table in memory, so there is no disk I/O going on.
CREATE TABLE `users` (
`user_id` bigint(20) NOT NULL AUTO_INCREMENT,
`first_name` varchar(100) CHARACTER SET utf8,
`last_name` varchar(100) CHARACTER SET utf8,
`install_date` datetime,
`comment` varchar(500),
`score` bigint(20),
PRIMARY KEY (`user_id`)
)

SingleStore’s single-threaded scan performance is 5 times faster in the first case and 8 times faster in the second case. There is no black magic involved here. SingleStore needs to run far fewer CPU instructions to read a row, for the reasons discussed above. SingleStore’s advantages really come to the fore when there are concurrent writes and many concurrent users.
Conclusion
SingleStore takes advantage of the simplicity and performance of lock-free skiplists for in-memory rowstore indexing. These indexes are used to back rowstore tables, to buffer rows in memory for columnstore tables, and to store metadata about columnstore blob files on disk. The result is a more modern indexing design, based on recent developments in data structure and lock-free/non-blocking algorithms research. The simplicity of the skiplist is the source of a lot of SingleStore’s speed and scalability.

.png?width=24&disable=upscale&auto=webp)








