

SingleStore VP of Product Rick Negrin describes the upcoming SingleStoreDB Self-Managed 7. 0 in depth. He describes crucial features such as fast synchronous replication, for transaction resilience, and Universal Storage™, which leads to lower total cost of ownership (TCO) and more operational flexibility, at both the architectural and operational levels. Negrin also describes new tools for deploying and managing SingleStore and new features in SingleStore Studio for monitoring, investigating active processes, and editing SQL.
This blog post focuses on SingleStoreDB Self-Managed 7.0 and the new features in SingleStore Studio. It’s based on the third part of our recent webinar, Singlestore Helios and SingleStoreDB Self-Managed 7.0 Overview. (Part 1 is here; Part 2 is here.) This blog post includes our most detailed description yet of the upcoming SingleStoreDB Self-Managed 7.0, and new features in SingleStore Studio.
Let’s dig in and see what’s new in SingleStoreDB Self-Managed 7.0 and SingleStore Studio. So before we do that, I just want to set a little context for how we think about database workloads that are out there, and what’s driving the features that are built into them. If you look at the history of databases, there have been two common workloads that people use a database for. One is around analytics, also known as either Online Analytical Processing (OLAP), or data warehousing. That typically is comprised of requirements around needing queries to be very fast, particularly large and complex queries that are doing aggregations, or group-bys, or a large set of filters.
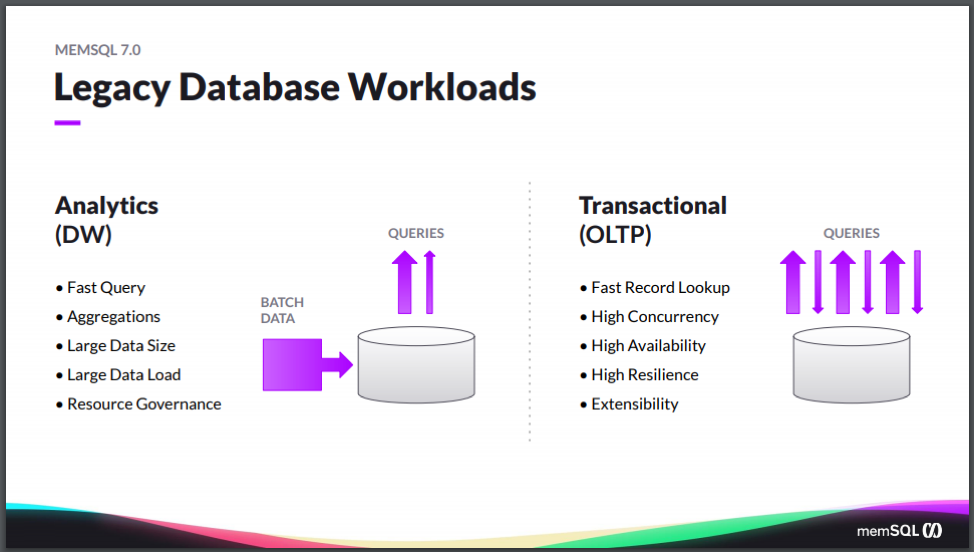
Now you often have a large data size these days measured in terabytes, or hundreds of terabytes, sometimes even petabytes. Usually a company has large, infrequent batch loads of data, with large data loads coming in periodically. And then a need to resource-govern the different workloads that are making use of the system, because you often have different users running different types of queries.
Now the other side is the transactional applications – the Online Transaction Processing (OLTP) workload. That has a difference in its requirements. So in that case, the reads are coming in from the application, and the writes are coming in from the application, as opposed to being different. The reason why is that it’s coming from different sources and the types of queries tend to be less complex queries, and more focused on things like fast record lookup or small, narrow-range queries. But there are much stronger requirements around the service level agreements (SLAs), around concurrency and the availability and resiliency of the system. The more mission-critical, the more there’s less tolerance for downtime.
Whereas on the data warehouse side, the OLAP or Online Analytics Processing side, you’re often running things at night. It’s often offline at night. If an analyst is forced offline for an hour, they go and get coffee and maybe are unhappy but, you know, it’s not the end of the world. Whereas with the transactional side, often it’s an application, and sometimes it’s customer-facing, or internal-facing to many users within your organization. If it’s down, it can be very bad to catastrophic for the business. And so the SLAs around durability, resilience, extensibility are pretty critical.
And what we’re seeing with the new, modern workloads is that often they have a combination of needs around the transactionality and the analytics, that they need the fast query and aggregations and the large data size, but there’s a change in one of the key requirements here. It’s not just large data load but they need fast data load. They need the data to come in within a certain SLA, but there’s an SLA not just on how fast the query is, but also on the ingest, how quickly the data gets into the system in order to meet that near-real-time requirement that people need.
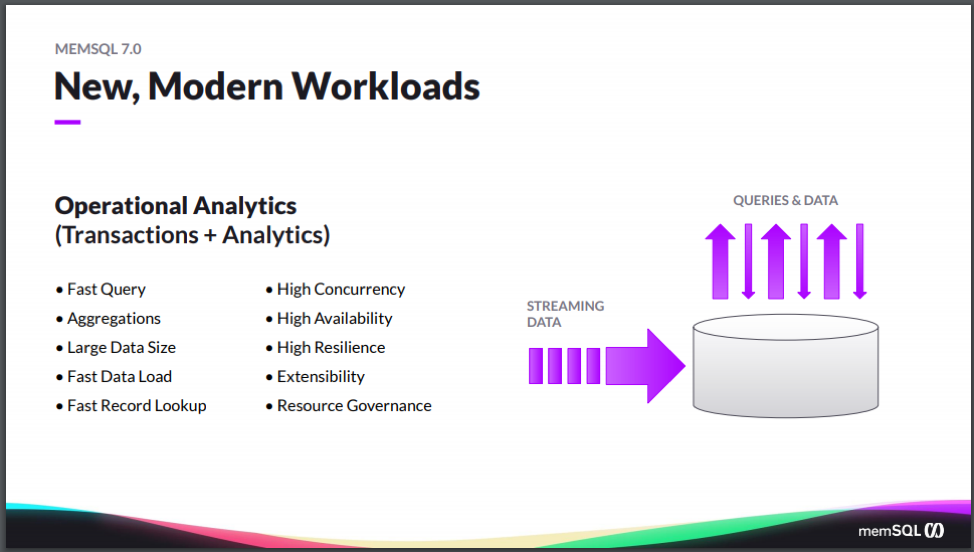
And then combine that with some use cases where, in addition to needing the aggregations, they also need the fast record lookups and all the availability and durability and resiliency that we expect from an operational system. And so it’s the combination of the same requirements that you have for the data warehouse as well, plus the operational ones, all combined in one system. There really aren’t many systems that can do that.
SingleStore has made solid progress pretty much across all of these requirements. At this point, we can do a vast majority of the workloads out there. But that’s not enough for us. We’re not going to be happy or settled until we can do all the workloads, which means being able to be as available and as resilient as the most mission-critical, complicated, highest-tier enterprise applications that are out there. And to do that, we need to get even more investments in things like resiliency. That’s why we focused on the two key features of 7.0, which are around fast synchronous replication and incremental backup.
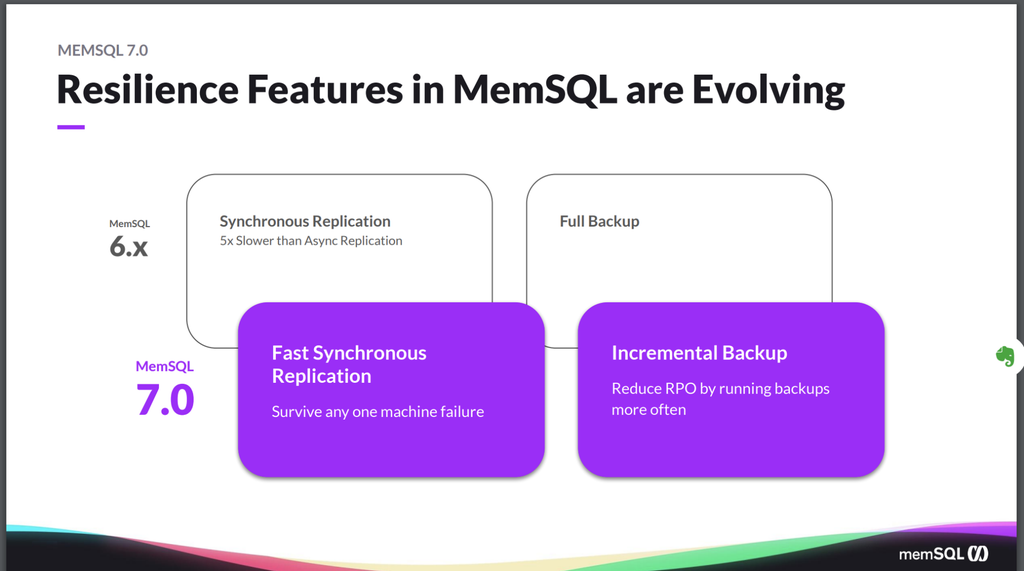
So up until this current version, we’ve had synchronous and asynchronous replication. The difference being is when we mentioned we have high availability (HA), in which we keep two copies of the data. With async replication, you return back success to the user as soon as at least one copy of the data’s written. Asynchronous replication, you wait until both copies are written before you return back success of the user. This guarantees the user that if there’s a problem or a failover, you’re guaranteed that no data will get lost because you have the data in both copies.
Now, we’ve always offered both mechanisms and the customers will choose, which one worked best for them, making a trade-off between performance and durability. And in some cases, customers made one choice versus the other but it was always unfortunate that they had to make that trade-off. Trade-offs are hard and nobody wants to have to choose between those two things they wanted. And so with 7.0, we revamped how we do synchronous replication, so it’s so close to the speed of async that there’s really just a negligible difference between them.
We’ve enabled synchronous replication as the default so that everybody gets the durability guarantees without having to trade out performance. And this enables you to basically survive any one machine failure without having to worry about any loss of data. And additionally, we move from having full backups only, to also offering incremental backups.
Full backups are great. They allow you to make sure that you have a copy of your data off the cluster in the event of a total cluster or major disaster. But having to do full backups only … Even though our backups are online operations that don’t stop you from running your existing workload, they do take up resources within the cluster. Moving to a model with incremental backup allows you to run the backups more often, reducing your recovery point objective (RPO) – the age of the files that you have to recover, before you can return to normal operations – and reducing the amount of load that you have in the cluster, so you don’t need as much capacity in order to maintain the SLA that you need without being impacted by running back-ups and restores. So really driving down the overall total cost of ownership (TCO) of the system and making it more resilient and driving down the RPO.
Now, there’s a lot more stuff in 7.0, but synchronous replication and incremental backups are the two marquee features that we’ve delivered that will make a huge difference to customers at that upper tier of enterprise workloads.
SingleStore Universal Storage in (Some) Depth
Now, the other big investment we made was around the storage mechanisms that we have in the SingleStore. So again, if you look at SingleStoreDB Self-Managed 6.8, which is still the current version, we have what we call Dual Store. We allow you to have a row-oriented table or a column-oriented table within your database and you can choose for every table that you create. So you create which one you want. Most of our customers end up choosing a mix of the two, because they get a certain set of trade-offs and advantages from a rowstore versus a columnstore table.
Row-oriented tables to tend to be good for more OLTP-type applications where you need fine-grain aggregation or seeks, for updates or deletes on a set of rows. But the downside is that you get a higher TCO because rowstore is all stored in RAM, and memory can get expensive when you get to large data sizes.
The column-oriented tables are much better for big data aggregation scanning billions of rows. You get much better compression on the column-oriented table, but you don’t get very good seek time if you need to seek just one or two rows, or a small number of rows. You don’t get secondary indexes. And so this put customers in an unfortunate position where they’ve had to choose between row-oriented and column-oriented tables. And if you need, for example, the big data aggregation because you’re doing table scans sometimes, but then doing seeks other times, you’re kind of stuck. You have to give up one or the other when you choose the solution for your application.
Coming up, with SingleStoreDB Self-Managed 7.0, we’ve made investments to make those trade-offs less harsh, investing in compression within the rowstore to drive down the TCO and implementing fast seeks and secondary hash indexes so that users who need those can just use columnstore data.
Here’s the comparison, for rowstore tables (transactional):
- Benefits: Fine-grain aggregation: seek, update, and delete up to millions of rows, fast; secondary indexes (regular & spatial)
- Former detriment (pre-SingleStoreDB Self-Managed 7.0): High TCO
- Now (with SingleStoreDB Self-Managed 7.0 and Universal Storage): Average 50% storage compression, with new null compression feature
And here’s a similar comparison, for columnstore tables (analytical):
- Benefits: Big data aggregation; scan billions of rows, very fast; full-text indexes; 5x-10x compression
- Former detriments (pre-SingleStoreDB Self-Managed 7.0): Slow seeks; no secondary indexes
- Now (with SingleStoreDB Self-Managed 7.0 and Universal Storage): Fast seeks; secondary hash indexes

We’re not going to stop there. Long term, what we want is to have a single table that has all those capabilities. Under the covers, we autonomously and automatically will use the right rowstore or columnstore format and make use of memory and disk so that you don’t have to make the choice at design time. We make the choice for you, in operational time, based on how your workload is working. Progress in that direction is what you’re going to see over the next several versions of SingleStore.
Here are the benefits for Universal Storage tables (transactional + analytical), with their original source – either rowstore or columnstore: Fine-grain aggregation (from rowstore) and big data aggregation (from columnstore); seek, update, delete up to millions of rows, fast (rowstore) and scan billions of rows (columnstore); secondary indexes, regular + spatial + full-text (rowstore) and 5x-10x compression (columnstore).

And last, but not least, of course, is this: in order to manage and make use of a distributed database, you need to have the right tools for both deploying and managing it. And so we have a number of new capabilities within our tool chain to make it easier to set up your cluster, if you’re using the self-managed software (rather than Singlestore Helios, where SingleStore does those things for you). Tools that also allow you to do things like online upgrade and do monitoring of your data over time, so you can do capacity management and troubleshoot problems that are intermittent.

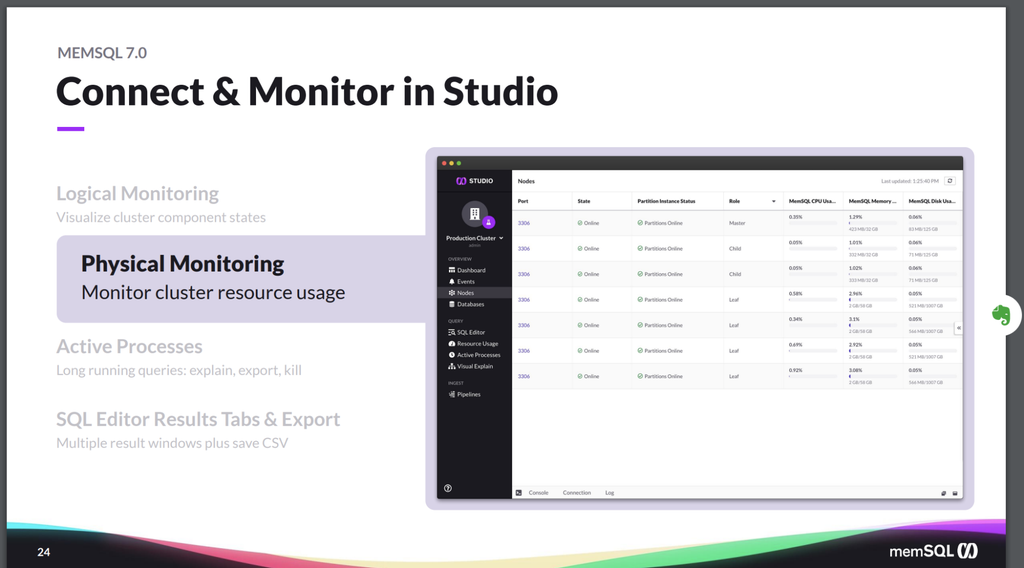
And then, on the visual side, the SingleStore Studio tool, which I briefly showed you during the demo, allows you to do things like logical monitoring to visualize the component states of the nodes within a cluster, to make sure there’s no hotspots or data skew or other problems that need attention.
Physical monitoring of the actual hosts, so you can see if any one of them is using more resources whether it’s CPU or memory or disk or I/O than it should be using, and take action if needed. (Of course, the physical monitoring is only something that you can do when you’re self-managed; when using Singlestore Helios, the physical monitoring is taken care of by SingleStore.)
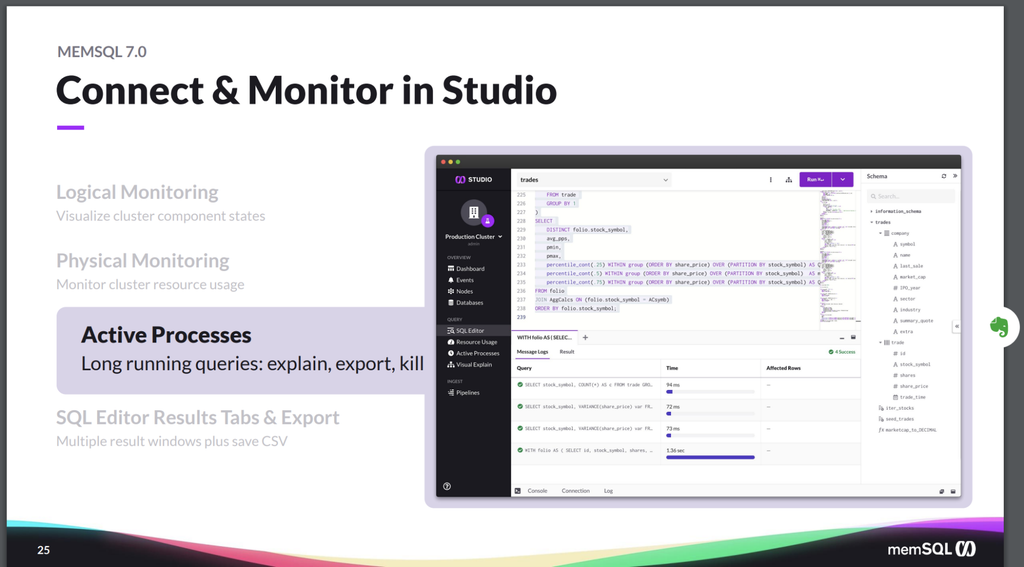
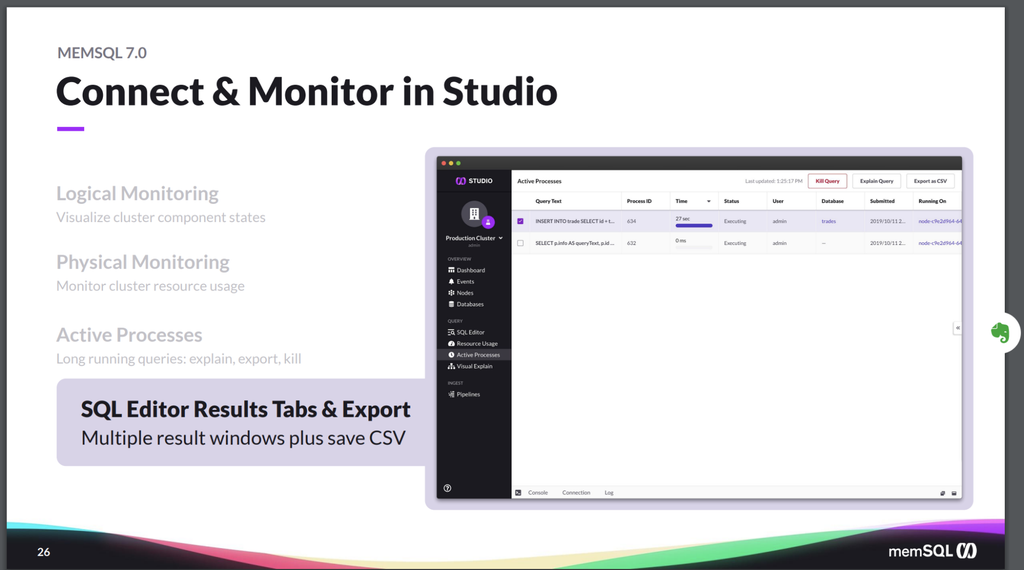
We also let you have tools to let you look for long-running queries, so you can troubleshoot if a query has problems. Perhaps there’s been a plan change, and you now have less optimal plan, using too much capacity or too much resources. So you can find the query, figure out what the problem is, and kill it if needed.
And of course, the SQL Editor, which you saw in the demo, that allows you to write queries and experiment with the system as well as manage it.
And that concludes our whirlwind tour of Singlestore Helios and the upcoming SingleStoreDB Self-Managed 7.0. Of course, you don’t have to believe anything I say. You can try it for you today yourself. You can access Singlestore Helios. We made our trial available to you, which is available at singlestore.comhttps://portal.singlestore.com/intention/cloud/. If you’re not a customer of SingleStore, you can still access the beta for free, or download our free tier to use SingleStore. Thank you very much.
SingleStore Q&A
Q. Is the software the same for Singlestore Helios, your elastic managed service in the cloud, as in the self-managed software? (Which you can deploy yourself, in the cloud or on-premises. Ed.) Are there any differences in capability?
A. Self-managed SingleStore the exact same engine used in the Singlestore Helios. It’s what we ship on-prem. As we upgrade software, those versions show up in the cloud, in Singlestore Helios. In fact, they’re likely to show up on the managed cloud first, before they show up in the self-managed software that we ship.
There are some slight differences. They’re mostly temporary. There are features that are disabled, that will be in the future. So for example, the transforms feature, where you can put in arbitrary code that will enable transformation of the data as it’s going to the pipeline. We don’t enable that on Singlestore Helios because we’re not yet ready to support that. We only take arbitrary code and run it inside of our manage service. However, in time, we’ll figure out how to do that safely, and we’ll enable that feature.
There are a few features like that aren’t supported yet but we’ll be supporting in the future. All this is documented in our documentation.
There are also some features that are more around managing the physical aspects of the cluster – for example, the ability to just take a node and add it to the cluster or move it towards a cluster. All these are managed for you by the system, with Singlestore Helios.
Q. Does SingleStore support high availability (HA), and how does it work?
A. HA is built into the system. With the self-managed software, you can choose whether or not you want HA at all, or if you want one or two copies. With Singlestore Helios, HA is always turned on. You can’t turn it off and it’s turned on automatically, so you won’t have to do anything. It just happens, transparently.
Q. Is there a plan to allow for real-time web based replication for MySQL to SingleStore? If not, do we have current workarounds that can get this done for us, such as MySQL to Kafka to SingleStore, or another solution that is already proven?
A. Yes. You can use existing replication tools, such as Attunity and other replication tools that support MySQL. (You can use these tools because SingleStore supports the MySQL wire protocol – Ed.) You can also stage data to Kafka or S3, and use SingleStore Pipelines to move it into SingleStore. In addition, SingleStore will have a solution that will move data from MySQL, Oracle, SQL Server, and other relational databases to SingleStore later this year.
Q. I was told common table expression (CTE) materialization is coming in SingleStoreDB Self-Managed 7.0. Is this true?
A. Recursive CTE virtualization is not coming in SingleStoreDB Self-Managed 7.0, but it’s on the roadmap for the future.
Q. When is SingleStoreDB Self-Managed 7.0 reaching general availability (GA)?
A. We’re in Beta 2 right now, we’ll have a release candidate (RC) in the next month or two, and then the GA should be up soon after that.
Q. Can you explain how you do fast synchronous replication in SingleStoreDB Self-Managed 7.0, without any penalties?
A. This blog post talks about our sync replication design: https://www.singlestore.com/blog/replication-system-of-record-memsql-7-0/.
Q. For Singlestore Helios, do you provide an SLA, and if so, what is it? When will SingleStoreDB Self-Managed 7.0 be available on Singlestore Helios? Will EU regions be available soon? And also, when will Singlestore Helios be on Azure?
A. Singlestore Helios provides an SLA of 99.9% availability. SingleStoreDB Self-Managed 7.0 will be available on Singlestore Helios when SingleStoreDB Self-Managed 7.0 goes GA – in fact, SingleStoreDB Self-Managed 7.0 is likely to be available on Singlestore Helios first. EU regions will be available in 2019. And Singlestore Helios will be available on Azure in the first half of 2020.
Q. Does SingleStore provide data masking on personally identifiable information (PII) columns?
A. SingleStore does not have masking as a built-in feature, but you can use views on top of tables to accomplish the same effect.
Q. Are RabbitMQ pipelines in the works?
A. These are on the roadmap, but not in the near-term.
Q. Is there a cost calculator for Singlestore Helios?
A. Cost is # of units * hours used * price per unit. For more information on pricing, please contact SingleStore Sales.
If you have any questions, send an email to team@singlestore.com. We invite you to learn more about SingleStore at singlestore.com and give us a try for free at singlestore.comhttps://portal.singlestore.com/intention/cloud/. Again, thank you for participating, and have a great remainder of the day.



.png?width=24&disable=upscale&auto=webp)






-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)

