

Formally, a multi-threaded algorithm is considered to be lock-free if there is an upper bound on the total number of steps it must perform between successive completions of operations.

The statement is simple, but its implications are deep – at every stage, a lock-free algorithm guarantees forward progress in some finite number of operations. (That’s why lock-free algorithms are used in SingleStore skiplists and, more recently, in sync replication – Ed.)\ Deadlock is impossible.
The promise of a lock-free algorithm seems remarkable in theory. Concurrent threads can modify the same object, and even if some thread or set of threads stalls or stops completely in the middle of an operation, the remaining threads will carry on as if nothing were the matter. Any interleaving of operations still guarantees of forward progress. It seems like the holy grail of multi-threaded programming.
This stands in contrast to the traditional method of placing locks around “critical sections” of code. Locking prevents multiple threads from entering these critical sections of code at the same time. For highly concurrent applications, locking can constitute a serious bottleneck. Lock-free programming aims to solve concurrency problems without locks. Instead, lock-free algorithms rely on atomic primitives such as the classic “compare-and-swap” which atomically performs the following:
bool CompareAndSwap(Value* addr, Value oldVal, Value newVal){
if(*addr == oldVal){
*addr = newVal;
return true;
}else{
return false;
}
}The biggest drawbacks to using lock-free approaches are:
- Lock-free algorithms are not always practical.
- Writing lock-free code is difficult.
- Writing correct lock-free code is extremely difficult.
To illustrate the third point above, let’s break down a typical first attempt at writing a lock-free stack. The idea is to use a linked-list to store nodes, and use CompareAndSwap to modify the head of the list, in order to prevent multiple threads from interfering with each other.
To push an element, we first create a new node to hold our data. We point this node at the current head of the stack, then use CompareAndSwap to point the head of the stack to the new element. The CompareAndSwap operation ensures that we only change the head of the stack if our new node correctly points to the old head (since an interleaving thread could have changed it).
To pop an element, we snapshot the current head, then replace the head with the head’s next node. We again use CompareAndSwap to make sure we only change the head if its value is equal to our snapshot.
The code, in C++
template
class LockFreeStack{
struct Node{
Entry* entry;
Node* next;
};
Node* m_head;
void Push(Entry* e){
Node* n = new Node;
n->entry = e;
do{
n->next = m_head;
}while(!CompareAndSwap(&m_head, n->next, n));
}
Entry* Pop(){
Node* old_head;
Entry* result;
do{
old_head = m_head;
if(old_head == NULL){
return NULL;
}
}while(!CompareAndSwap(&m_head, old_head, old_head->next));
result = old_head->entry;
delete old_head;
return result;
}
}
Unfortunately, this stack is riddled with errors.
Segfault
The Push() method allocates memory to store linked-list information, and the Pop() method deallocates the memory. However, between the time a thread obtains a pointer to a node on line 22, and subsequently accesses the node on line 26, another thread could have removed and deleted the node, and the thread will crash. A safe way to reclaim the memory is needed.
Corruption
The CompareAndSwap method makes no guarantees about whether the value has changed, only that the new value is the same as the old value. If the value is snapshotted on line 22, then changes, then changes back to the original value, the CompareAndSwap will succeed. This is known as the ABA problem. Suppose the top two nodes on the stack are A and C. Consider the following sequence of operations:
- Thread 1 calls pop, and on line 22 reads m_head (A), on line 26 reads old_head->next (C), and then blocks just before calling CompareAndSwap.
- Thread 2 calls pop, and removes node A.
- Thread 2 calls push, and pushes a new node B.
- Thread 2 calls push again, and this time pushes a new node occupying the reclaimed memory from A.
- Thread 1 wakes up, and calls CompareAndSwap.
The CompareAndSwap on line 26 succeeds even though m_head has changed 3 times, because all it checks is that old_head is equal to m_head. This is bad because now m_head will point to C, even though B should be the new head.
Not lock-free
The C++ standard makes no guarantee that new and delete will be lock-free. What good is a lock-free data structure that makes calls to non-lock-free library calls? For our stack to be truly lock-free, we need a lock-free allocator.
Data races
When one thread writes a value to a location in memory, and another thread simultaneously reads from the same location, the result is undefined in C++ unless std::atomic is used. The reads and writes both need to be atomic, and C++ makes no such guarantee for primitive types. Prior to C++11, it was a common practice to use volatile for atomic variables, however this approach is fundamentally flawed.
In this case, threads reading the head pointer constitute data races, both in Push and Pop, because another thread could be simultaneously modifying it.
Memory reordering
It is convenient to think of computers as being sequentially consistent machines, where every load or store can be placed into a single total order that is consistent with every thread. At the very least, we would expect the “happens before” relationship to be transitive. Unfortunately this is not the case, and in both theory and practice the following sequence of events is possible, with x and y initialized to 0:
| thread 1 | thread 2 |
|---|---|
| print x x.store(1) print y | print y y.store(1) print x |
output:
| thread 1 | thread 2 |
|---|---|
| x -> 0 y -> 0 | y -> 0 x -> 0 |
This would seem to imply that the printing of x happened before the store of x, which happened before the printing of y, which happened before the store of y, which in turn happened before the printing of x. This is just one example of how different threads may see changes to memory occur in different orders. Furthermore, it is possible for loads and stores to be reordered within a single thread, both by the compiler and by the hardware. In the above lock-free stack a reordered store could result in another thread seeing a stale version of a node’s next pointer and subsequently dereferencing an invalid memory location.
How to write a correct lock-free stack
Most of the above problems have many different solutions. Here I’ll describe the approaches I use at work for our lock-free stack.
Segfault
Before dereferencing a node, we need to make sure it cannot be deleted. Each thread has a special globally visible pointer called a “hazard pointer”. Before accessing the head node, a thread will set its hazard pointer to point to that node. Then, after setting the hazard pointer it makes sure the node is still the head of the stack. If it is still the head, then it is now safe to access. Meanwhile, other threads that may have removed the node from the stack cannot free the associated memory until no hazard pointer points to this node. For efficiency, the deletion process is deferred to a garbage collection thread that amortizes the cost of checking hazard pointers.
Note that the ABA problem does not have any consequences here. It does not matter if the head changed between the two reads. As long as the hazard pointer has been continuously pointing to a node for some interval of time that includes a moment in which the node belonged to the stack, then it is safe to access the node.
Corruption
One way to avoid the ABA problem is to ensure that the head of the stack never has the same value twice. We use “tagged pointers” to ensure uniqueness of head values. A tagged pointer contains a pointer and a 64-bit counter. Every time the head changes, the counter is incremented. This requires a double-width CompareAndSwap operation, which is available on most processors.
Not lock-free
Instead of allocating a separate node to store each entry, the “next” pointer is embedded in the entry itself, thus no memory allocation is needed in order to push it onto the stack. Furthermore, we may reuse the same node multiple times, recycling rather than deleting. Requiring an extra 8 bytes per entry is an unattractive property if you want a stack for small data structures, but we only use the stack for large items where the 8 bytes is insignificant.
Data races
We currently use boost::atomic for this. Our compiler is gcc 4.6, which currently supports std::atomic, but its implementation is much less efficient than boost’s. In gcc 4.6, all operations on atomic variables apply expensive memory barriers, even when a memory barrier is not requested.
Memory reordering
C++11 provides a new memory model and memory ordering semantics for atomic operations that control reordering. For our lock-free stack to work correctly, CompareAndSwap needs to be performed with sequentially consistent memory semantics (the strongest kind). Sequential consistency means that all such operations can be put into a total order in which all threads observe the operations. There is a very easy to miss race condition (that went unnoticed in our code for months) involving the aforementioned hazard pointers. It turns out that hazard pointers also need to be assigned using sequentially consistent memory semantics.
Here’s the case that broke our stack:
- Thread 1, in preparation for a Pop operation, reads the head of the stack.
- Thread 1 writes the current head to its hazard pointer (using only release semantics, which are weaker than sequentially consistent semantics).
- Thread 1 reads the head of the stack again.
- Thread 2 removes head from the stack, and passes it to the garbage collector thread (using sequentially consistent memory semantics).
- The garbage collector scans the hazard pointers,\ and (because the assignment was not done with sequentially consistent memory semantics) is not guaranteed to see thread 1’s hazard pointer pointing to the node.
- The garbage collector deletes the node
- Thread 1 dereferences the node, and segfaults.
With sequentially consistent memory semantics applied to both the hazard pointer assignment and head modification, the race condition cannot happen. This is because for any two sequentially consistent operations, all threads must see them happen in the same order. So if thread 2 removing the pointer happens first, thread 1 will see a different value on its second read and not attempt to dereference it. If thread 1 writes to its hazard pointer first, the garbage collector is guaranteed to see that value and not delete the node.
Performance
Now that we’ve solved the issues with our stack, let’s take a look at a benchmark. This test was performed on an 8 core Intel(R) Xeon(R) machine. The workload consisted of random operations, with Push and Pop equally likely. The threads were not throttled in any way – all threads performed as many operations as the machine could handle.
Well, that’s not very impressive.
The stack has a single point of contention, and is limited by the rate at which we can modify the head of the stack. As contention increases, so does the number of failed CompareAndSwap operations. A simple yet highly effective way to reduce the number of failed operations is simply to sleep after each failed operation. This naturally throttles the stack to a rate it can effectively handle. Below is the result of adding “usleep(250)” after any failed operation.
That’s right, the addition of a sleep improved throughput by roughly 7x! Furthermore, the addition of usleep(250) reduced processor utilization. Take a look at the output from HTOP while running each benchmark for 16 threads.
Locked stack:
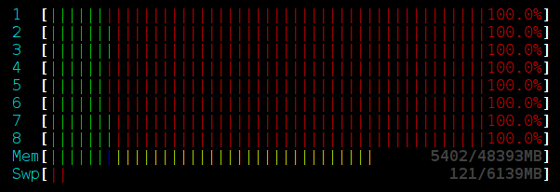
Lock-free stack, no sleep:
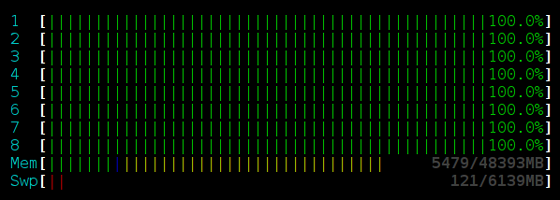
Lock-free stack with usleep(250):
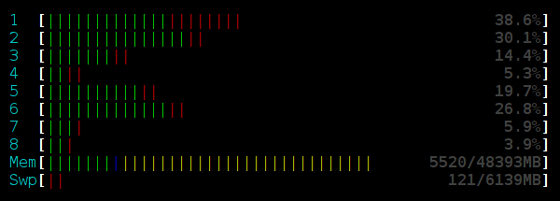
So lock-free is better, right? Well, the lock can be improved as well. Instead of using std::mutex, we can use a spinlock that performs the same usleep(250) each time it fails to acquire the lock. Here are the results:
Results
Under high contention, additional threads dramatically reduced overall throughput. The addition of a sleep reduced contention, and consequently both increased throughput while decreasing processor utilization. Beyond 3 threads all stacks showed a relatively level performance. None of the multi-threaded stacks performed better than a single-threaded stack.
Conclusion
Lock-free guarantees progress, but it does not guarantee efficiency. If you want to use lock-free in your applications, make sure that it’s going to be worth it – both in actual performance and in added complexity. The lock-free stack presented at the beginning of this article contained a multitude of errors, and even once the errors were fixed it performed no better than the much simpler locked version. Avoid trying to write your own lock-free algorithms, and look for existing implementations instead.
Code
Lock-based.
class LockFreeStack{
#include
#include
template
class LockedStack{
public:
void Push(T* entry){
std::lock_guard lock(m_mutex);
m_stack.push(entry);
}
// For compatability with the LockFreeStack interface,
// add an unused int parameter.
//
T* Pop(int){
std::lock_guard lock(m_mutex);
if(m_stack.empty()){
return nullptr;
}
T* ret = m_stack.top();
m_stack.pop();
return ret;
}
private:
std::stack<T*> m_stack;
std::mutex m_mutex;
};Lock-free. The garbage collection interface is omitted, but in real applications you would need to scan the hazard pointers before deleting a node. The cost of the scan can be amortized by waiting until you have many nodes to delete, and snapshotting the hazard pointers in some data structure with sublinear search times.
class LockFreeStack{
public:
// The elements we wish to store should inherit Node
//
struct Node{
boost::atomic<Node*> next;
};
// Unfortunately, there is no platform independent way to
// define this class. The following definition works in
// gcc on x86_64 architectures
//
class TaggedPointer{
public:
TaggedPointer(): m_node(nullptr), m_counter(0) {}
Node* GetNode(){
return m_node.load(boost::memory_order_acquire);
}
uint64_t GetCounter(){
return m_counter.load(boost::memory_order_acquire);
}
bool CompareAndSwap(Node* oldNode, uint64_t oldCounter, Node* newNode, uint64_t newCounter){
bool cas_result;
__asm__ __volatile__
(
"lock;" // This makes the following instruction atomic (it is non-blocking)
"cmpxchg16b %0;" // cmpxchg16b sets ZF on success
"setz %3;" // if ZF set, set cas_result to 1
: "+m" (*this), "+a" (oldNode), "+d" (oldCounter), "=q" (cas_result)
: "b" (newNode), "c" (newCounter)
: "cc", "memory"
);
return cas_result;
}
private:
boost::atomic<Node*> m_node;
boost::atomic m_counter;
}
// 16-byte alignment is required for double-width
// compare and swap
//
__attribute__((aligned(16)));
bool TryPushStack(Node* entry){
Node* oldHead;
uint64_t oldCounter;
oldHead = m_head.GetNode();
oldCounter = m_head.GetCounter();
entry->next.store(oldHead, boost::memory_order_relaxed);
return m_head.CompareAndSwap(oldHead, oldCounter, entry, oldCounter + 1);
}
bool TryPopStack(Node*& oldHead, int threadId){
oldHead = m_head.GetNode();
uint64_t oldCounter = m_head.GetCounter();
if(oldHead == nullptr){
return true;
}
m_hazard[threadId*8].store(oldHead, boost::memory_order_seq_cst);
if(m_head.GetNode() != oldHead){
return false;
}
return m_head.CompareAndSwap(oldHead, oldCounter, oldHead->next.load(boost::memory_order_acquire), oldCounter + 1);
}
void Push(Node* entry){
while(true){
if(TryPushStack(entry)){
return;
}
usleep(250);
}
}
Node* Pop(int threadId){
Node* res;
while(true){
if(TryPopStack(res, threadId)){
return res;
}
usleep(250);
}
}
private:
TaggedPointer m_head;
// Hazard pointers are separated into different cache lines to avoid contention
//
boost::atomic<Node*> m_hazard[MAX_THREADS*8];
};The code is also available on github (if you want to test it locally): https://github.com/memsql/lockfree-bench
.png?height=187&disable=upscale&auto=webp)








