
Today's applications are expected to handle an ever-increasing number of concurrent users who need to access and modify data simultaneously. That level of demand places immense pressure on database systems to ensure data integrity and consistency, while maintaining high performance and low latency. Traditional relational databases, while robust, often require complex tuning or vertical scaling to handle heavy concurrent workloads, which can limit scalability and increase operational complexity. This article delves into the critical concept of concurrency control, exploring how SingleStore, a modern distributed SQL database, deploys innovative techniques to handle significantly more concurrent users than traditional architectures.
The challenge of concurrency in database systems
Concurrency control is one of the most challenging aspects of database management. When multiple users attempt to access and modify data simultaneously, databases must ensure transactions maintain ACID properties (Atomicity, Consistency, Isolation, Durability) while maximizing throughput. Traditional approaches to concurrency control often create contention points that limit scalability as user numbers increase.
Common issues in traditional database systems include:
Lock contention. When multiple transactions compete for the same resources
Deadlocks. Where transactions get stuck waiting for each other's locks
Performance degradation. Where throughput decreases as concurrency increases
Serialization bottlenecks. Where transactions must be processed in a specific order
For modern applications — especially those serving global user bases or processing real-time data streams — concurrency limitations directly impact business outcomes. Poor concurrency handling leads to slow response times, failed transactions and lost customers or missed insights. Organizations often resort to complex database sprawl, deploying multiple specialized databases like MongoDB®, PostgreSQL, Redis and others, to handle different workload types. This approach increases complexity, costs and management overhead.
Multi-version concurrency control: The core innovation
A core feature enabling SingleStore to handle high volumes of concurrent reads and writes efficiently is its implementation of Multi-version concurrency control (MVCC), a proven technique also used in other modern databases, but implemented in a way that’s optimized for SingleStore’s distributed architecture. This approach fundamentally changes how the database manages concurrent operations compared to traditional locking mechanisms.
How MVCC works in SingleStore
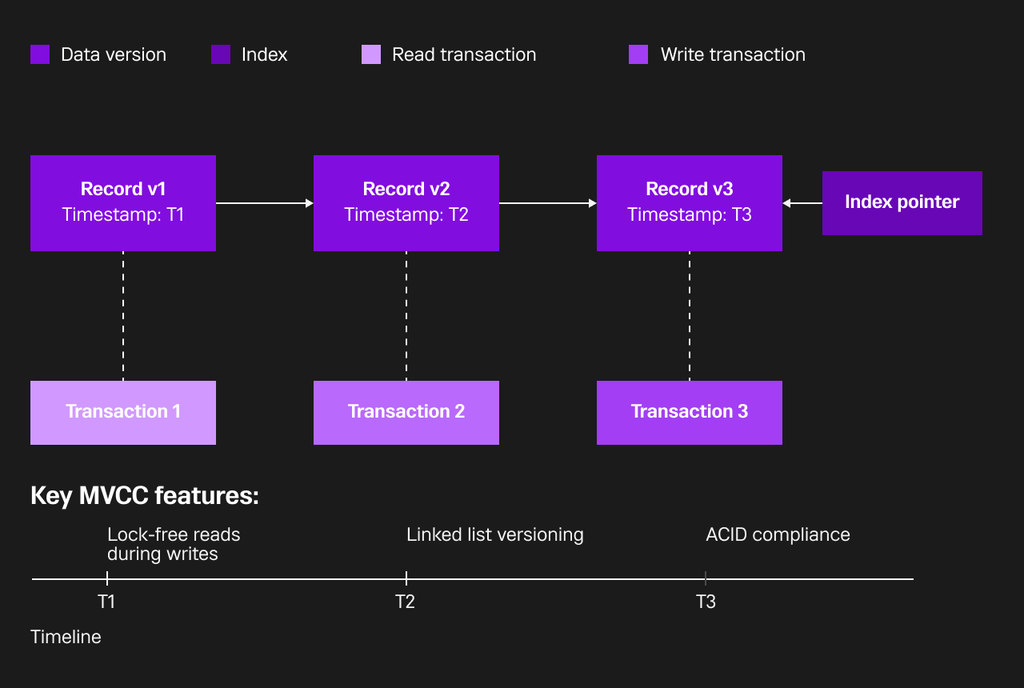
SingleStore tracks multiple versions of data using a memory-optimized indexing structure, allowing readers and writers to operate concurrently without blocking. This implementation enables writing data without locks and reading data concurrently during data ingest — two operations that typically conflict in traditional databases. The result is dramatically faster performance, even under heavy concurrent loads.
All database operations in SingleStore maintain ACID properties, ensuring data remains consistent despite high concurrency. Every SQL statement runs as its own transaction by default, while supporting multi-statement transactions for complex operations that need consistency across multiple steps.
Scale-out architecture with SQL support
SingleStore's architectural approach combines elements from both NoSQL and traditional relational databases to create a system optimized for concurrency:
Distributed processing for better concurrency
The platform employs a scale-out architecture that distributes processing across an arbitrary number of servers, easily scaling CPU capacity, RAM and disk storage horizontally. This approach allows SingleStore to handle much higher concurrency than vertically scaled, traditional databases — since the workload can be distributed across many nodes.
SingleStore is unique because it achieves this scale-out architecture while maintaining full SQL support. This "plug and play" compatibility with existing SQL ecosystems means organizations don't need to sacrifice the structured query capabilities they depend on to achieve better concurrency handling.
Workload management for unpredictable spikes
Many database concurrency issues arise not from sustained high loads but from sudden, unpredictable spikes in traffic or query complexity. SingleStore incorporates workload management features specifically designed to handle these scenarios gracefully.
Intelligent query handling during load spikes
When a node in the SingleStore cluster experiences high load, the workload management system intelligently adjusts how queries are admitted and executed. Fast, inexpensive queries continue to complete with no regression in latency, while expensive queries are temporarily throttled to compensate and allow the system to remain responsive.
Benchmark testing demonstrates the effectiveness of this approach. When spiking from eight to 32 concurrent users (a 4x increase), SingleStore with workload management enabled showed 56% better latency on cheaper queries compared to the same system without workload management. There was a tradeoff with expensive queries (44% worse performance), but this intelligent prioritization ensures the system remains responsive during concurrency spikes rather than degrading across all query types.
Autoscaling for dynamic workloads
Modern applications rarely exhibit static usage patterns. User activity fluctuates throughout the day, across time zones and during special events or promotions. SingleStore Helios® provides autoscaling capabilities that automatically adjust compute resources based on workload demand, ensuring high availability and optimal performance regardless of traffic fluctuations.
Real-time resource adjustment
SingleStore's compute workspaces can scale vCPU and RAM resources quickly to adjust to spikey workloads. When an application experiences a burst of traffic beyond what its current resources can handle, autoscaling increases resources automatically. When demand decreases, resources scale down to optimize costs.
This approach is particularly valuable for SaaS applications with variable user numbers or development environments that don't always need full resources. Companies like Leads2B have leveraged this capability to handle spiky, user-activity-based workloads across multiple time zones, scaling both writes and reads in real time.
Performance comparison with traditional databases
When compared to traditional relational databases like MySQL, Oracle or PostgreSQL, SingleStore demonstrates significantly higher concurrency capabilities:
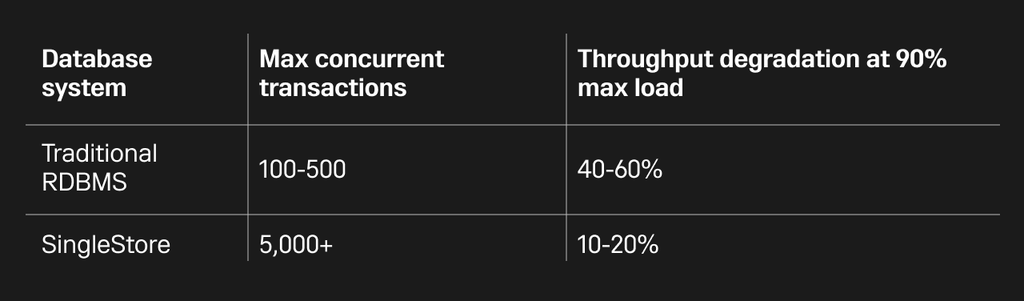
A key differentiator is how performance scales with increasing concurrency. Traditional databases often show a dramatic drop in throughput as concurrency increases, while SingleStore maintains relatively stable performance.
Real-world concurrency performance
The impact of SingleStore's concurrency approach becomes evident in real-world implementations, where organizations have consolidated multiple specialized databases into a single SingleStore deployment.
Fathom replaced a combination of MySQL, Redis and Amazon DynamoDB with SingleStore, achieving dramatic improvements in query performance, up to 1,000x in specific workloads, along with a 60% reduction in total cost of ownership. Similarly, Sony consolidated PostgreSQL, AWS ElastiCache and Amazon DynamoDB into SingleStore, resulting in 100x performance improvement and 75% cost reduction.
Hulu represents another striking example, having replaced Apache Storm and Druid with SingleStore. Their implementation processes two billion rows per hour with a 50% reduction in infrastructure requirements. These dramatic improvements reflect not only SingleStore's raw performance but its ability to maintain that performance under high concurrency conditions.
SingleStore's multi-version concurrency control
Here's a practical, hands-on example demonstrating SingleStore's multi-version concurrency control that you can easily try on a SingleStore SQL playground. This example shows how two concurrent "sessions" (which you can simulate by opening two separate query windows in the playground) interact with the same data without blocking each other.
Scenario. We'll simulate a simple scenario involving a table of products and their stock levels. One transaction will update the stock, while another reads the stock level.
Start free with SingleStore, and get going with our step-by-step guide.
Once you sign up, go to the Deployments tab.
Make sure you have the workspace and a database created (you can create both if you’re missing them)
Then, go to Data Studio in the left-side menu.
Next, create a new SQL file by clicking the + New button and selecting New SQL file from the dropdown.
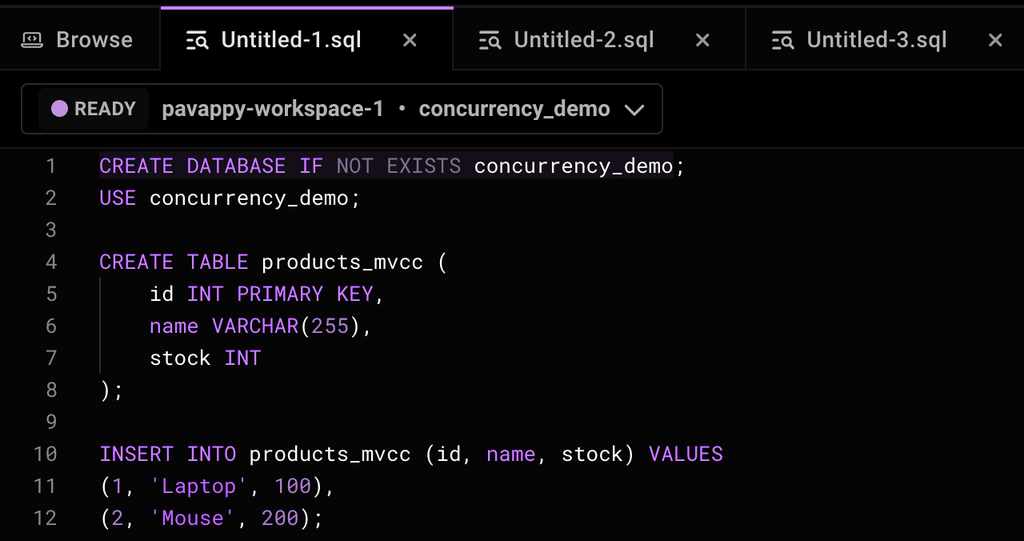
In the SQL terminal that appears, run the following set of queries.
1CREATE TABLE products_mvcc (2 id INT PRIMARY KEY,3 name VARCHAR(255),4 stock INT5);6 7INSERT INTO products_mvcc (id, name, stock) VALUES8(1, 'Laptop', 100),9(2, 'Mouse', 200);10
Here is what it will look like when the queries are pasted into SingleStore’s SQL editor.
Simulate concurrent transactions
Now, open a second query window in the SingleStore SQL dashboard. You'll use these two windows to simulate two concurrent transactions.
Transaction 1 (update)
In the first query window, start a transaction and perform an update on the products_mvcc table. Do not commit yet.
1BEGIN WORK;2UPDATE products_mvcc SET stock = stock - 10 WHERE id = 1;
The same is shown below,
At this point, the stock for 'Laptop' has been updated in Transaction 1's view, but has not yet been committed.
Transaction 2 (read)
Immediately after running the UPDATE statement in the first window (but before committing it), switch to the second query window and execute a SELECT statement to read the same row:
1SELECT * FROM products_mvcc WHERE id = 1;
The same is shown here:

Observation
You should observe the result in the second query window (transaction 2) will show the original stock level for the 'Laptop' (100), even though transaction 1 has already executed the UPDATE statement. This is because MVCC provides a consistent snapshot of the data as it existed when transaction 2 started its read operation. Transaction 2 doesn't see the uncommitted changes made by transaction 1.
Commit transaction 1
Now, go back to the first query window and commit the transaction:
1COMMIT;2
The same is shown here
Read again in transaction 2 (or a new query)
Go back to the second query window (or open a third new query window) and execute the same
1SELECT statement again:2 3SELECT * FROM products_mvcc WHERE id = 1;
The same is shown here
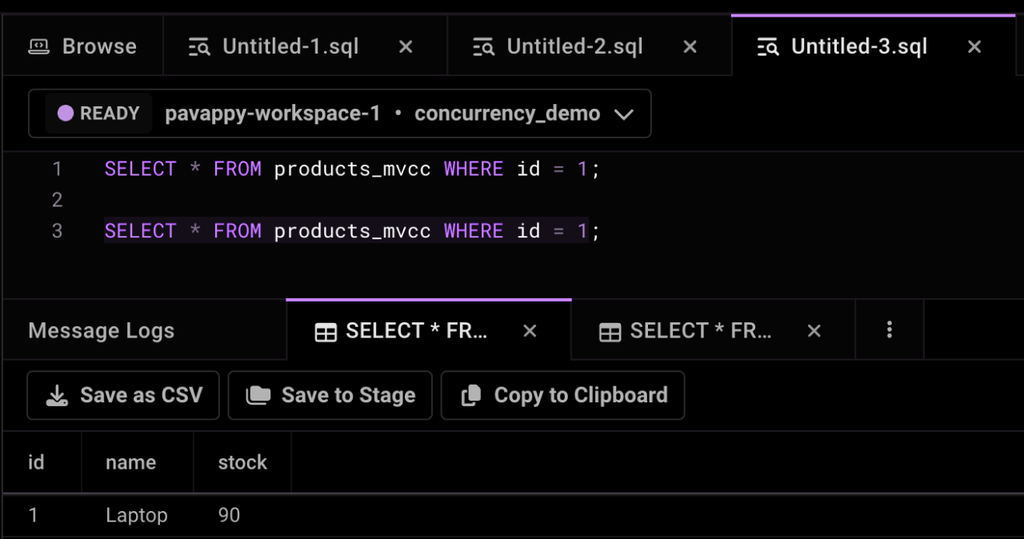
Observation. This time, you will see the updated stock level for the 'Laptop' (90). This demonstrates that once transaction 1 commits, the changes become visible to subsequent transactions.
Explanation of MVCC in action:
This simple example illustrates the core principle of MVCC:
Non-blocking reads. Transaction 2 could read the data without being blocked by the ongoing update in transaction 1.
Consistent snapshot. Transaction 2 saw a consistent snapshot of the data as it existed when its query started.
Isolation. The changes made by transaction 1 were isolated from transaction 2 until transaction 1 was committed.
The ability to have concurrent reads and writes without blocking is a key reason why SingleStore can handle more simultaneous users compared to traditional databases that rely heavily on locking, where transaction 2 might have been blocked until transaction 1 released its lock on the row.
You can further experiment by running more concurrent updates and reads on different rows in the table to get a better feel for how MVCC allows for high concurrency in SingleStore.
Conclusion
Concurrency control is a fundamental aspect of database management, especially in today's demanding application environments. While traditional databases often rely on pessimistic locking, SingleStore leverages an MVCC-based approach to concurrency, combined with a distributed shared-nothing architecture and in-memory processing, to achieve superior scalability and handle significantly more concurrent users.
This modern approach allows applications built on SingleStore to deliver high performance and responsiveness — even under intense transactional workloads, making it a compelling choice for applications requiring high concurrency and low latency. As the demand for real-time data processing continues to grow, the innovative concurrency control mechanisms employed by databases like SingleStore will be crucial for building scalable and performant applications.












