

Solutions Engineer Mihir Bhojani presents a 20-minute technical overview of Singlestore Helios. In this webinar recap, we present the key points of the interview, and give you a chance to review them at your leisure. You can also view the Singlestore Helios Technical Overview.
In this webinar, we’ll cover what exactly Singlestore Helios is and how it compares with self-managed SingleStore, which you download yourself, provision, and run in the cloud or on-premises. With Singlestore Helios, SingleStore provisions the hardware in the cloud and runs SingleStore itself; you just set up tables and manage your data. After describing Singlestore Helios, I’ll have a hands-on demo that will show you the whole end-to-end process of getting started with Singlestore Helios.

Singlestore Helios is basically the SingleStore product that you’ve known and you have used before, except that it’s a fully managed service. We offer it on an on-demand model so you can spin up clusters on the fly temporarily for a few hours, or keep them long-running.
Singlestore Helios is also an elastic database, because you’ll be able to grow your cluster or shrink on the fly, and also on demand. All of this is done online, so there’s no downtime when you scale out or scale down. With Singlestore Helios, we here at SingleStore take care of your cluster provisioning and software deployment. We’ll do biweekly maintenance upgrades on your cluster. And ongoing management and operations of your cluster will be handled by SingleStore experts. That leaves you, as the user, to be only responsible for logical management of your data, helping you to keep your focus on application development.

With Singlestore Helios, you get effortless deployment and elastic scale, so you can have a cluster up and running in five minutes. We’re going to demonstrate that today. You have superior TCO when you compare to legacy databases, so you can do a lot more with Singlestore Helios with a lot less hardware allocated. You have multi-cloud and hybrid flexibility, so you have your pick when it comes to which cloud provider and which region you want to deploy in.
Currently Singlestore Helios is available on AWS and GCP; we have multiple global regions in both of those platforms, and we have Azure support coming in the next five to six months.
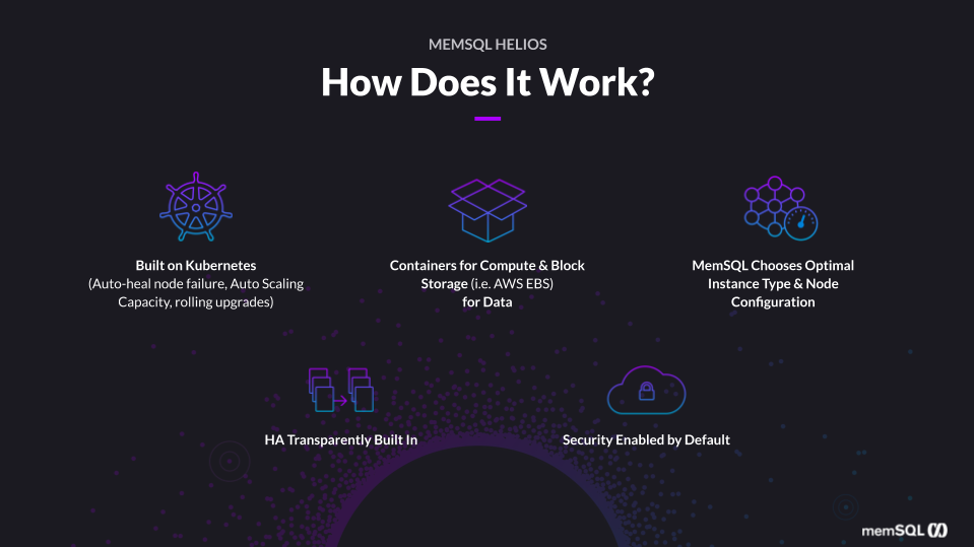
Let’s talk about how Singlestore Helios works under the hood, then we can jump into the demo. Singlestore Helios is facilitated by, and built on, Kubernetes. (Using the beta SingleStore Kubernetes Operator – Ed.) This helps us enable unique features like auto-healing, handling node failures, and also lets us enable features like auto-scaling and to do rolling online upgrades.
Because SingleStore is inherently a distributed system, it’s really important that there’s high availability at all times. For storage, SingleStore makes use of basically the block storage of your cloud provider. We choose optimal instance type and node configuration when you start creating the cluster.
High availability (HA) is transparently built in. So you will have HA as soon as you spin up the cluster. The way HA works in SingleStore is that leaf nodes are basically paired up. Leaf nodes are basically data nodes, and you have data being duplicated from one leaf node to another and vice versa. So if one leaf node goes down, the other one can keep the cluster up and live. Security is also enabled by default. The way we do that is we have in-flight encryption, so we encrypt your connections using TLS in-flight. Then we also have at-rest encryption. We use your cloud provider’s encryption services to do encryption.
Let’s see Singlestore Helios in action. I want to outline what exactly we’ll be seeing today.

The use case for today that we’re going to handle, and this is a real-life use case that we have companies using SingleStore for, is ad tech. So this data set is a digital advertising data example, which basically drills down and gets data from a traditional funnel. So we’re going to see multiple different advertisers and campaigns and we’re going to see what kind of engagements and events they are generating.
We’re going to facilitate that by creating a cluster from scratch. We’ll create the database and tables from scratch as well. And then we’ll create a pipeline to start ingesting data from an existing Kafka topic. Then finally, we’ll access all of this data from Singlestore Helios via a business intelligence (BI) dashboard.
Let’s get started. So if you go to
singlestore.com/cloud-trial/, you’ll be able to spin up with \$600 of free credits. That’s the amount of time that you get to spin up a cluster as a trial. So if you go to portal.singlestore.com and you go to the Clusters tab, you’ll see a create button and when you click on that, you’ll be brought to this screen. I’m just going to name this Singlestore Helios-webinar. You’ll have your pick when it comes to which cloud provider and region you want to be in. And we’re always adding new regions as well.
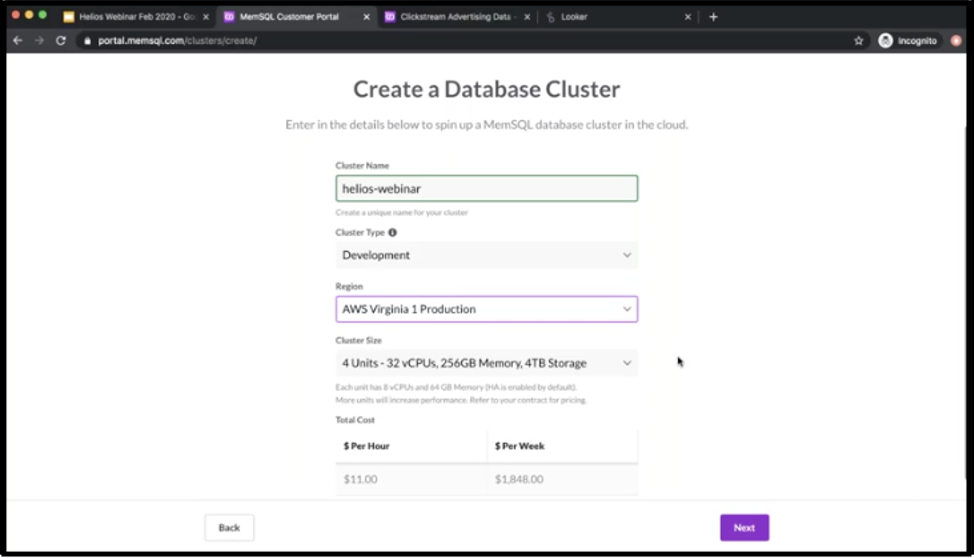
So right now I’ll leave it at AWS Virginia. Cluster size – so, because SingleStore is a distributed system in this case, when we refer to units, we’re really talking about leaf nodes. (Leaf nodes hold data. They are accompanied by one or more aggregator nodes, which hold schema and which dispatch queries to the leaves – Ed.) One unit in Singlestore Helios is actually eight VCPUs, 64GB of RAM and one terabyte storage. You can only purchase units in pairs, so in increments of two essentially. For now we’re going to leave this at four, so it’s a modest-sized cluster. We’ll generate a password and make sure to copy it.
Then you can also configure cluster access restrictions. So if you want to white-list specific IP ranges, we absolutely recommend that you do that. For now, I’ll just hide my own IP address. Then, as an advanced setting, you can also configure if you want to automatically expire this cluster after a certain number of hours.
Once we click on Create cluster, we’ll see that the cluster will start reconciling resources. What it means, it’s really trying to go to AWS and using Kubernetes, it’s going to spin up a cluster on the fly. This process is expected to take about five minutes. In the interest of saving time, I already have a cluster spun up before the webinar, so I’m just going to use that going forward for this webinar. It’s essentially the same size cluster as I created before, and once it’s up and running, you’ll see something like this on your screen, where on the right side you’ll have all the connection information.
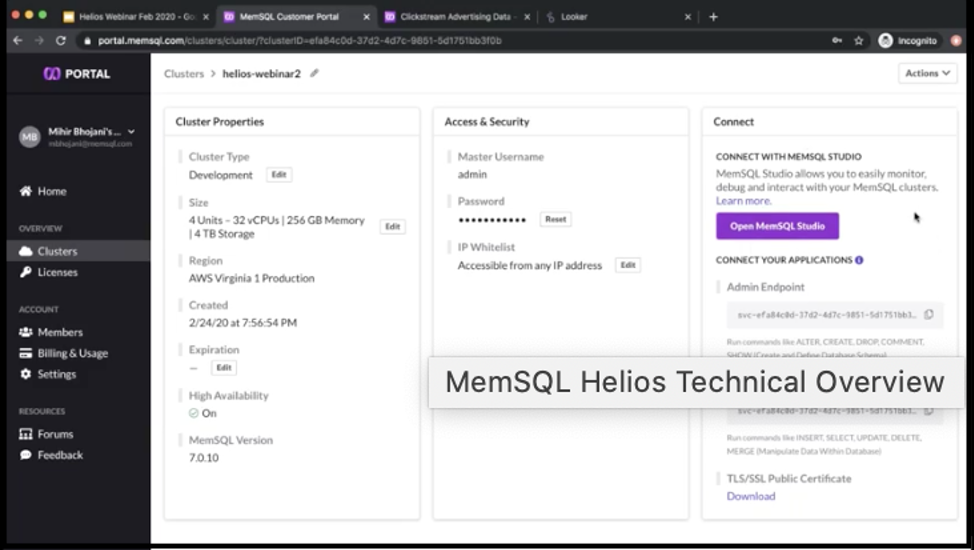
The SingleStore Studio that we’re going to tour just in a second here is basically the GUI interface for interacting with Singlestore Helios. But we also get these endpoints where if you want to connect from your own applications, your own BI tools using JDBC/ODBC, you can basically use these endpoints to connect to the SingleStore cluster. For now, let’s just go into SingleStore Studio.

Here, we’ll enter the password that we generated earlier. As soon as you log in you’ll see a screen, something like this, which is basically a dashboard that shows you what current health and usage looks like on your cluster. As we can see, there’s currently no pipelines, no data, nothing. The reason why it says seven nodes is because when we chose four units, when spinning up the cluster, so we got four leaf nodes as expected; the rest of the three nodes are basically aggregator notes. So you get one master agg and two child agg, plus the leaf nodes. All of those are obviously load balanced.
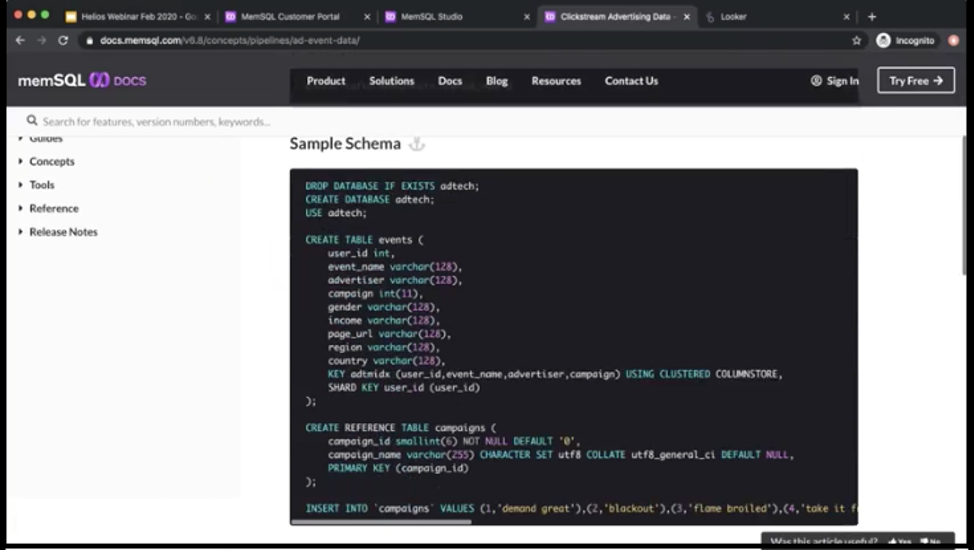
Let’s start creating some schemas. So here we have this sample use case basically. Here is a sample schema that we’re going to use.
I’m just going to explain what’s happening here. So here we’re going to create a database and then two tables. The first table is the events table and this is basically the fact table, right? So this is where all the raw events from the Kafka topic are going to stream into.
This is a columnstore table. So when you create tables in SingleStore, you have two options. You have rowstore and columnstore. The default table type in SingleStore is rowstore. So if you don’t specify, then by default you’ll get a rowstore table, which means all your data will go in memory. But if you do specify a key using cluster columnstore, then basically you get a columnstore table, where your data is actually on disk. We use memory to optimize performance, and we store indexes of metadata in memory. Columnstore is definitely recommended for OLAP (online analytical processing) workloads and rowstore is recommended for OLTP (online transaction processing) workloads.
Then the second table here is campaigns, which is basically just a lookup table. This table is that we’re going to join when we need to look up specific campaigns. That’s why we’re creating it as a reference table. Reference tables actually store the entire copy of the table on every single leaf node, so it really helps in situations where you need to join this table often. You just need to be careful that this table is a good (small) size to be able to fit into every single node. Then we’re going to also populate the campaigns table with some static values. We have about 14 campaigns that we’re going to populate to begin with.
Let’s run everything. This should take about eight to nine seconds.
Now that we have everything running, we have the ad tech database now, and then we have two tables inside this database. The next step is, we have this Kafka topic here, it’s a Kafka cluster that we’re hosting in-house. How do we get that data into the Singlestore Helios cluster? That’s where the pipelines feature comes in.
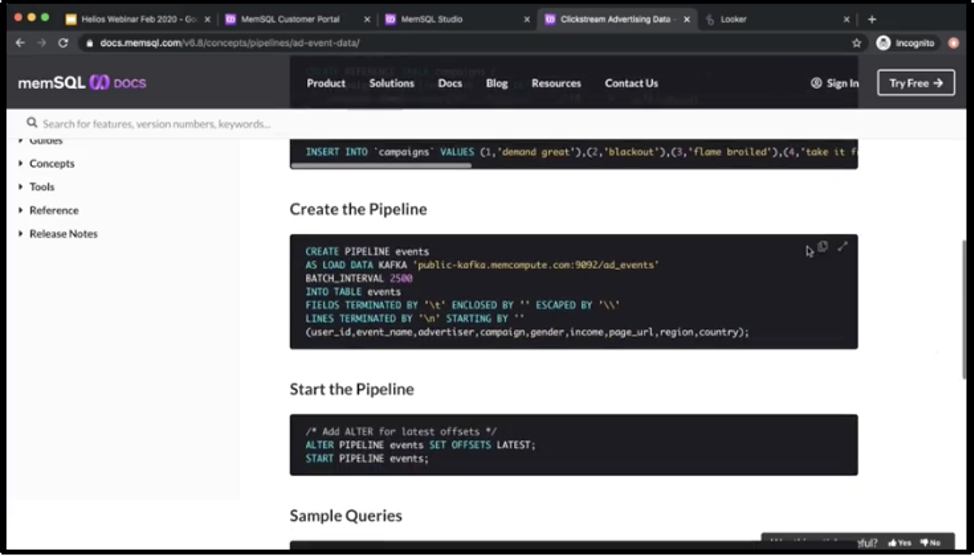
The pipelines feature is something that can connect to Kafka obviously, but it can also connect to other sources like AWS S3, Azure blobstore, HDFS. If you have data sitting in any of those places, then you can always use a pipeline to natively stream data directly to SingleStore.
For now we’re going to use Kafka, as it’s one of our most-used technologies. You can also specify a batch interval, how often you want to batch data into SingleStore. So right now it’s at 2,500 milliseconds or 2.5 seconds. I’m just going to make this 100 milliseconds and see what kind of results we get. We’re going to obviously send all the data into the events table that we created earlier. Then here are just all the fields that we want to populate coming in from the topic.
This pipeline is created. But if we go back to the dashboard, we’ll see that there’s no data being actually written yet because we haven’t started it. I just need to go back to the SQL editor and then alter the pipeline offsets so that we only get data basically from the latest offset. Then I’m going to finally start the pipeline.
Now if I go back to the dashboard, we should see rows being written at a steady pace into SingleStore. Just to reiterate, this demo is not to show you any performance aspects of SingleStore, it’s basically just a functional demo. Singlestore Helios can handle very high throughputs when it comes to ingestion and also query performance.
Now that we have data flowing in, let’s start running some queries. Here’s some prewritten SQL queries that we have written. Let’s explore what we have so far. Then like I mentioned, we’ll go over to a BI tool to see how this data looks in a dashboard format.
For a simple question, how many events have we processed so far? That number right now is 51,000 and every time you run this, we expect it to go up a few thousands. So if I ran it again, it should go up. So right now it’s at 57,000 and if I ran it again, it’s at 60,000.
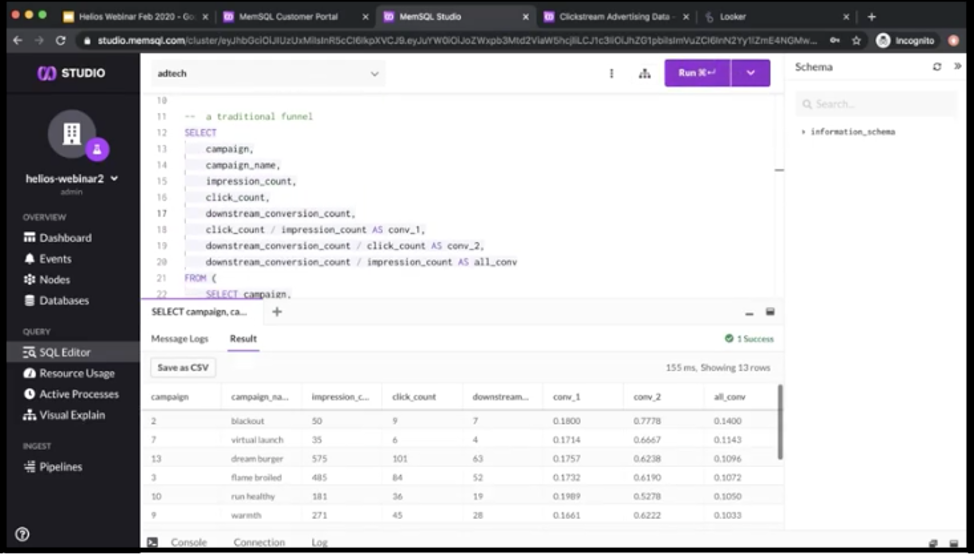
What campaigns are we running? This is the lookup table that we populated earlier. These are all the 14 campaigns that we are running right now. Then here’s the traditional funnel query for analysts to see broken everything down by campaign, how many impressions, clicks and downstreams they’re getting per campaign.
Let’s see how this data looks like in a Looker dashboard. Now Looker is a BI tool that we partner with and SingleStore works, integrates with almost all the BI tools out there. We are also MySQL compatible. If there’s a tool out there that does not have a SingleStore connector, you can always leverage the MySQL connector to connect to us.
This is the dashboard that’s basically reading off of the Singlestore Helios cluster that we just created. This number of ad events should match up with the number here. So yes, it’s 101. If I go back here, it should be close to that number.
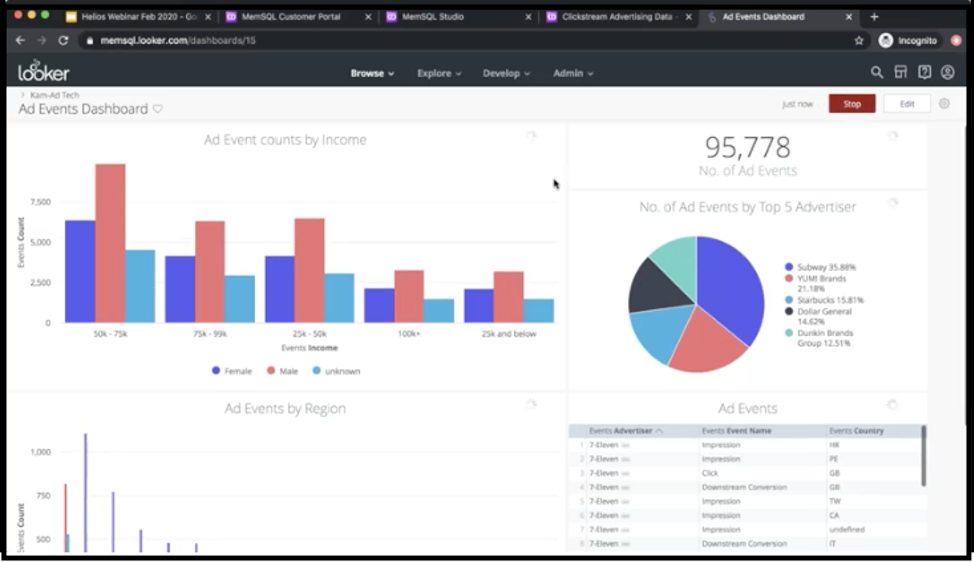
All right. This is basically just the raw number that’s coming into the SingleStore cluster right now. Here we just have some charts that are… By the way, all of them are updating in real time. So this is a dashboard that’s refreshing every one seconds. If I just click on edit and go to settings – yep, there it is.
So all these charts are set to auto-refresh every one second. Now almost all BI tools have that option, but they’re almost never used, because it’s really important for the underlying database to be able to handle a number of queries coming in at a steady pace and be able to respond back to all those queries in time so that the dashboard doesn’t choke up. We can see here that Singlestore Helios and SingleStore are able to do just that.
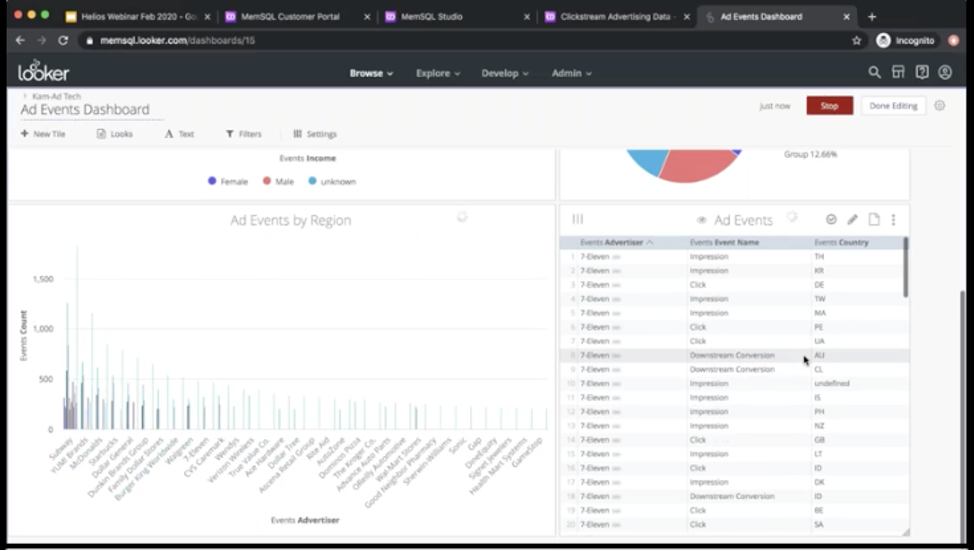
Here we can see we have a number of ad events by top five advertisers. Here it’s broken down, ad events by region and obviously which companies. Then here is just the raw table of ad events as they are coming in. It’s really important in SingleStore that we emphasize the time that goes from an event to happen to insight, to someone to analyze it. It’s extremely short.
Basically in the last 10 minutes or so, we basically created a cluster. We created databases. We even created a pipeline and then we started flowing the data in. And now we have a dashboard that we’re able to get insight from. And not only that, now that we have the insight, we can now take the appropriate action.
Even though this use case focuses basically on a lot of the ad tech aspects, it’s really important to know that we have done this for multiple industries, whether that’s IoT, financial services… We work with a variety of customers out there. The real value of SingleStore here is that you basically get the best of all worlds when it comes to speed, scale, and SQL. With speed, that could mean the time it takes to actually spin up a cluster in a distributed system that’s complex to set up. Now we are able to get it up and running in less than five minutes. Or it could be the ultra-fast ingest and the high performance you get when it comes to querying your data.
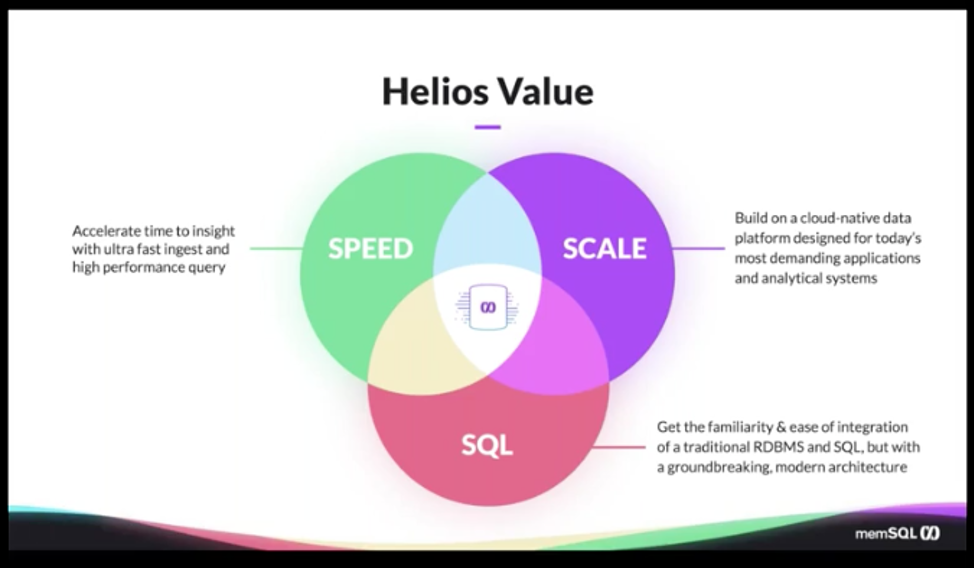
The scale-out mechanism of SingleStore is obviously really unique, the way that you can always expand your aggregator or leaf nodes. Then, in Singlestore Helios, it’s even easier now, because all it takes is one click of a button if you want to expand your cluster or shrink down. And all of those things are facilitated using SQL.
It’s really important to the companies that we work with and the analysts that we work with that they’re able to continue using SQL, because it is a powerful analytical language and you basically get the best of all worlds when it comes to using SingleStore. You still get to use SQL, but you get all the benefits of the speed and the scalability that you traditionally get only with NoSQL databases. (Because previously, those were the only databases that were scalable; now, NewSQL databases combine scalability and SQL. See our popular blog post on NoSQL. – Ed) Now we basically combine all three and give it to you in one package.
There’s also another use case that I wanted to cover. Medaxion is a company that I also personally work with. Medaxion is basically a medical analytics platform. They provide a platform for anesthesiologists to analyze medical data. It’s really important for them to have a 24/7, always-on analytics solution so that they can help and change lives.

Before SingleStore, they had some challenges – pretty simple challenges and fair challenges as well, that they weren’t able to get – their event to insight time was way too slow. Partly because of the legacy systems or single-box systems that are not able to keep up with the growth and demand that a lot of the startups face from time to time. In this case, MySQL couldn’t scale, and wasn’t able to fit their needs, and that was leading to a poor customer experience. As a result of that, Medaxion couldn’t help the anesthesiologists be at the right place at the right time, and also automate their work as much as possible.
When Medaxion came to us, they had these three requirements – of many more, but these three were the main requirements. They wanted something that was fast and they wanted something that had SQL. They wanted a database that could work natively with the Looker platform that we just saw. That’s what Medaxion uses as well. And they wanted to be able to write ad hoc SQL queries.
So they wanted something that could be scalable, that could have really high performance when it comes to ingest and querying, and also be accessible using SQL. They wanted a managed service. Now just like all other startups out there, there’s a lot of operational complexity when it comes to managing a distributed system. Of course when it’s a database that’s mission critical to your application, then it does have some complexity related.
They were very clear that they wanted a managed service because they didn’t want to add additional personnel just to handle the operations of a system like SingleStore. They wanted something obviously that had reliable performance, so something that was running 24/7, and no downtime whatsoever. When they switched to SingleStore, these were the results that we got.
We got really fast and scalable SQL, basically exactly what they wanted, and now they have dramatic performance gains and no learning curve. This boils down to the second point, we’re MySQL-compatible. There was a very low amount of work and risk involved when it comes to switching from a system like MySQL to SingleStore because we’re not only wire protocol-compliant, you’re already familiar with the language, and you’re already familiar with the tools that integrate with those technologies.
With Singlestore Helios, now they can just eliminate any operational headaches. They don’t have to worry about upgrading every two weeks. They don’t have to worry about high configuring, high availability, encryption, load balancing – a lot of those things are now taken care of by us and SingleStore experts. That leaves you, and in this case Medaxion, to just focus on development tasks. As a result of that, now they have near-real-time results. And they have what the CTO of Medaxion calls, “The best analytics platform in the healthcare industry.” They said it’s facilitated because of SingleStore.
I just want to thank you guys for your time today. If you do want to spin up your own Singlestore Helios trial, please feel free to go to singlestore.com/managed-service. All our trials are 48 hours, giving you more time to ingest your data, more time to test your queries. Of course, if you have any questions about pricing and billing, please reach out to us at info@singlestore.com.
Q&A
What is the uptime SLA guaranteed on Singlestore Helios?
That’s a good question. Uptime SLA on Singlestore Helios, we’re guaranteeing three nines of uptime, so 99.9%.
If the underlying storage is in S3, then storage will be cheaper.
That’s a good question. Right now you can’t have underlying storage be S3. You basically do have the ability to ingest data directly from S3, but the data does need to be within the SingleStore cluster.
How about the Kinesis pipeline?
Right now we only support Kafka pipelines, and Kinesis is something that would take some custom work. We do have some custom scripts available if you do want to ingest data from Kinesis, but right now natively we only connect to Kafka.
How does backup/restore work on Singlestore Helios?
We will take daily backups on Singlestore Helios for you and we’ll retain a copy of that backup for seven days. So you can always request a restore from a particular day in the last week or so. But you also have the ability to kick off your own backups whenever you desire. So you can always back up into your S3 bucket, or your Azure blobstore bucket, and then you can always restore from those technologies as well.


-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)






