SingleStore Notebooks
New



Employee Data Analysis JSON Dataset
Notebook
Note
This notebook can be run on a Free Starter Workspace. To create a Free Starter Workspace navigate to Start using the left nav. You can also use your existing Standard or Premium workspace with this Notebook.
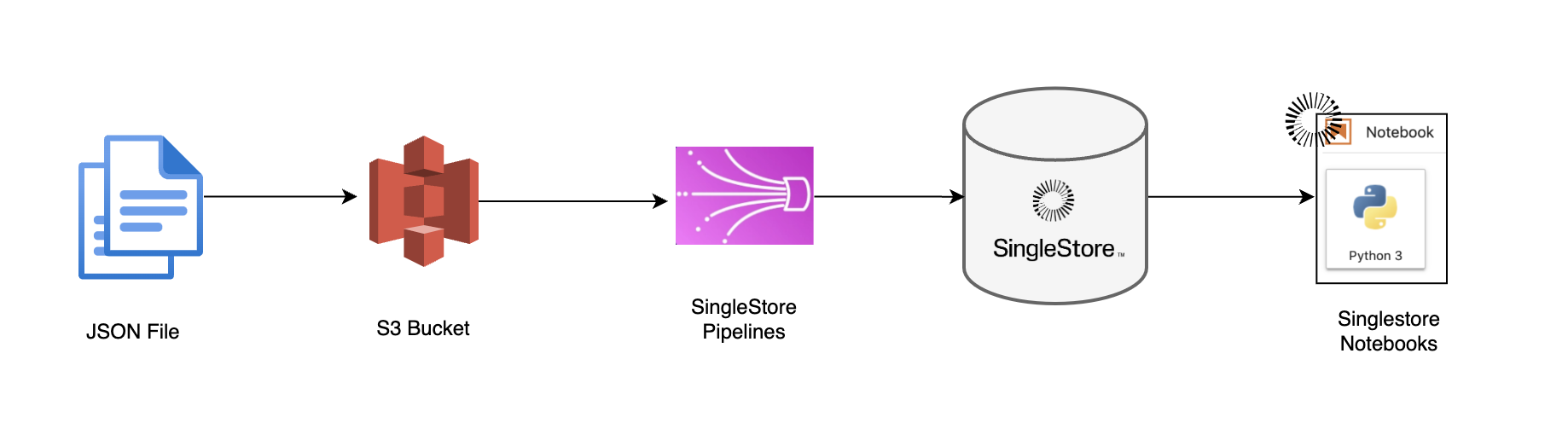
In this example, we want to create a pipeline from multiple JSON files stored in an AWS S3 bucket called singlestoredb and a folder called employeedata. This bucket is located in ap-south-1.
Each file has the following shape with nested arrays:
{
"userId": "88-052-8576",
"jobTitleName": "Social Worker",
"firstName": "Mavis",
"lastName": "Hilldrop",
"dataofjoining": "20/09/2020",
"contactinfo": {
"city": "Dallas",
"phone": "972-454-9822",
"emailAddress": "mhilldrop0@google.ca",
"state": "TX",
"zipcode": "75241"
},
"Children": [
"Evaleen",
"Coletta",
"Leonelle"
],
"salary": 203000
}
Demo Flow
How to use this notebook
Create a database (You can skip this Step if you are using Free Starter Tier)
We need to create a database to work with in the following examples.
In [1]:
1shared_tier_check = %sql show variables like 'is_shared_tier'2if not shared_tier_check or shared_tier_check[0][1] == 'OFF':3 %sql DROP DATABASE IF EXISTS HRData;4 %sql CREATE DATABASE HRData;
Action Required
If you have a Free Starter Workspace deployed already, select the database from drop-down menu at the top of this notebook. It updates the connection_url to connect to that database.
In [2]:
1%%sql2 3CREATE TABLE IF NOT EXISTS employeeData /* Creating table for sample data */ (4 userId text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,5 jobTitleName text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,6 firstName text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,7 lastName text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,8 dataofjoining text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,9 contactinfo JSON COLLATE utf8_bin NOT NULL,10 salary int NOT NULL,11 Children JSON COLLATE utf8_bin NOT NULL12 );
Create Pipeline To Insert JSON Data into Table
In [3]:
1%%sql2 3CREATE PIPELINE IF NOT EXISTS employeeData AS4LOAD DATA S3 'singlestoreloaddata/employeedata/*.json' /* Creating pipeline for sample data */5CONFIG '{ \"region\": \"ap-south-1\" }'6 /*7 CREDENTIALS '{"aws_access_key_id": "<Key to Enter>",8 "aws_secret_access_key": "<Key to Enter>"}'9 */10INTO TABLE employeeData11FORMAT JSON12(13 userId <- userId,14 jobTitleName <- jobTitleName,15 firstName <- firstName,16 lastName <- lastName,17 dataofjoining <- dataofjoining,18 contactinfo <- contactinfo,19 salary <- salary,20 Children <- Children21);22 23START PIPELINE employeeData;
Check if Data is Loaded
In [4]:
1%%sql2SELECT * from employeeData limit 5;
Sample Queries
Select Top 2 Employees with highest salary risiding in State 'MS'
In [5]:
1%%sql2select * from employeeData where contactinfo::$state = 'MS' order by salary desc limit 2
Select Top 5 Cities with highest Average salary
In [6]:
1%%sql2select contactinfo::$city as City,AVG(salary) as 'Avg Salary' from employeeData3 group by contactinfo::$city order by AVG(salary) desc limit 5
Number of employees with Children grouped by No of children
In [7]:
1%%sql2SELECT3 JSON_LENGTH(Children) as No_of_Kids,4 COUNT(*) AS employees_with_children5FROM employeeData6 group by JSON_LENGTH(Children);
Average salary of employees who have children
In [8]:
1%%sql2SELECT3 AVG(salary) AS average_salary_with_children4FROM employeeData5WHERE JSON_LENGTH(Children) > 0;
Select the total and average salary by State
In [9]:
1%%sql2SELECT3 contactinfo::$state AS State,4 COUNT(*) AS 'No of Employees',5 SUM(salary) AS 'Total Salary',6 AVG(salary) AS 'Average Salary'7FROM employeeData8GROUP BY contactinfo::$state limit 5;
Top 5 job title with highest number of employees
In [10]:
1%%sql2SELECT3 jobTitleName,4 COUNT(*) AS num_employees5FROM employeeData6GROUP BY jobTitleName order by num_employees desc limit 5;
Select the highest and lowest salary
In [11]:
1%%sql2SELECT3 MAX(salary) AS highest_salary,4 MIN(salary) AS lowest_salary5FROM employeeData;
Conclusion
We have shown how to connect to S3 using Pipelines and insert JSON data into SinglestoreDB. These techniques should enable you to
integrate and query your JSON data with SingleStoreDB.
Clean up
Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created.
In [12]:
1%%sql2#STOP PIPELINE employeeData;3 4#DROP PIPELINE employeeData;
Drop data
In [13]:
1#shared_tier_check = %sql show variables like 'is_shared_tier'2#if not shared_tier_check or shared_tier_check[0][1] == 'OFF':3# %sql DROP DATABASE IF EXISTS HRData;4#else:5# %sql DROP TABLE employeeData;
Details
About this Template
Employee Data Analysis use case illustrates how to leverage SingleStore's capabilities to process and analyze JSON data from a Amazon S3 data source.
This Notebook can be run in Shared Tier, Standard and Enterprise deployments.
Tags
starterloaddatajson
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.
License
This Notebook has been released under the Apache 2.0 open source license.