SingleStore Notebooks
New

Concatenate

Movie Recommendation
Notebook
Note
This tutorial is meant for Standard & Premium Workspaces. You can't run this with a Free Starter Workspace due to restrictions on Storage. Create a Workspace using +group in the left nav & select Standard for this notebook. Gallery notebooks tagged with "Starter" are suitable to run on a Free Starter Workspace
Source: Full MovieLens 25M Dataset - Appplication
This notebook demonstrates how SingleStoreDB helps you build a simple Movie Recommender System.
1. Install required libraries
Install the library for vectorizing the data (up to 2 minutes).
In [1]:
1!pip install sentence-transformers --quiet
2. Create database and ingest data
Create the movie_recommender database.
In [2]:
1%%sql2DROP DATABASE IF EXISTS movie_recommender;3CREATE DATABASE IF NOT EXISTS movie_recommender;
Action Required
Make sure to select the movie_recommender database from the drop-down menu at the top of this notebook. It updates the connection_url which is used by the %%sql magic command and SQLAlchemy to make connections to the selected database.
Create tags table and start pipeline.
In [3]:
1%%sql2CREATE TABLE IF NOT EXISTS tags (3 `userId` bigint(20) NULL,4 `movieId` bigint(20) NULL,5 `tag` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,6 `timestamp` bigint(20) NULL7);8 9CREATE PIPELINE tags10 AS LOAD DATA S3 'studiotutorials/movielens/tags.csv'11 CONFIG '{\"region\":\"us-east-1\", \"disable_gunzip\": false}'12 BATCH_INTERVAL 250013 MAX_PARTITIONS_PER_BATCH 114 DISABLE OUT_OF_ORDER OPTIMIZATION15 DISABLE OFFSETS METADATA GC16 SKIP DUPLICATE KEY ERRORS17 INTO TABLE `tags`18 FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY '\\'19 LINES TERMINATED BY '\r\n'20 NULL DEFINED BY ''21 IGNORE 1 LINES22 (userId, movieId, tag, timestamp);23 24START PIPELINE tags;
Create ratings table and start pipeline.
In [4]:
1%%sql2CREATE TABLE IF NOT EXISTS ratings (3 userId bigint(20) DEFAULT NULL,4 movieId bigint(20) DEFAULT NULL,5 rating double DEFAULT NULL,6 timestamp bigint(20) DEFAULT NULL7);8 9CREATE PIPELINE ratings10 AS LOAD DATA S3 'studiotutorials/movielens/ratings.csv'11 CONFIG '{\"region\":\"us-east-1\", \"disable_gunzip\": false}'12 BATCH_INTERVAL 250013 MAX_PARTITIONS_PER_BATCH 114 DISABLE OUT_OF_ORDER OPTIMIZATION15 DISABLE OFFSETS METADATA GC16 SKIP DUPLICATE KEY ERRORS17 INTO TABLE `ratings`18 FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY '\\'19 LINES TERMINATED BY '\r\n'20 NULL DEFINED BY ''21 IGNORE 1 LINES22 (userId, movieId, rating, timestamp);23 24START PIPELINE ratings;
Create movies table and start pipeline.
In [5]:
1%%sql2CREATE TABLE movies (3 movieId bigint(20) DEFAULT NULL,4 title text CHARACTER SET utf8 COLLATE utf8_general_ci,5 genres text CHARACTER SET utf8 COLLATE utf8_general_ci,6 FULLTEXT(title)7);8 9CREATE PIPELINE movies10 AS LOAD DATA S3 'studiotutorials/movielens/movies.csv'11 CONFIG '{\"region\":\"us-east-1\", \"disable_gunzip\": false}'12 BATCH_INTERVAL 250013 MAX_PARTITIONS_PER_BATCH 114 DISABLE OUT_OF_ORDER OPTIMIZATION15 DISABLE OFFSETS METADATA GC16 SKIP DUPLICATE KEY ERRORS17 INTO TABLE `movies`18 FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY '\\'19 LINES TERMINATED BY '\r\n'20 NULL DEFINED BY ''21 IGNORE 1 LINES22 (movieId, title, genres);23 24START PIPELINE movies;
Check that all the data has been loaded
There should be 25m rows for ratings, 62k for movies and 1m for tags. If the values are less than that, try the query again in a few seconds, the pipelines are still running.
In [6]:
1%%sql2SELECT COUNT(*) AS count_rows FROM ratings3UNION ALL4SELECT COUNT(*) AS count_rows FROM movies5UNION ALL6SELECT COUNT(*) AS count_rows FROM tags
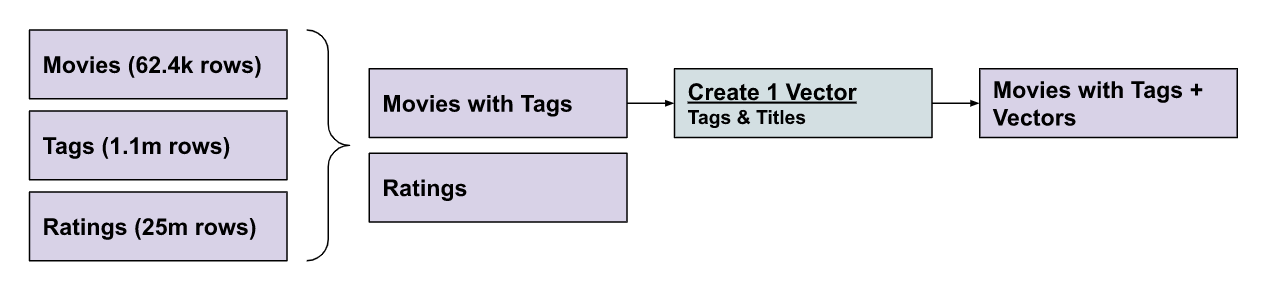
Concatenate tags and movies tables using all tags
In [7]:
1%%sql2CREATE TABLE movies_with_tags AS3 SELECT4 m.movieId,5 m.title,6 m.genres,7 GROUP_CONCAT(t.tag SEPARATOR ',') AS allTags8 FROM movies m9 LEFT JOIN tags t ON m.movieId = t.movieId10 GROUP BY m.movieId, m.title, m.genres;
3. Vectorize data
Initialize sentence transformer.
In [8]:
1from sentence_transformers import SentenceTransformer2 3model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_mpnet-base')
Query the movies_with_tags table and store the output in a variable named result. The result << syntax in the
%%sql line indicates that the output from the query should get stored under that variable name.
In [9]:
1%%sql result <<2SELECT * FROM movies_with_tags
Convert the result from the above SQL into a DataFrame and clean up quotes.
In [10]:
1import pandas as pd2 3df = pd.DataFrame(result)4 5# Curate the special characters6df['title'] = df['title'].str.replace('"', '')7df['allTags'] = df['allTags'].str.replace('"', '').str.replace("'", '')8 9data = df.to_dict(orient='records')
Check the first row of the list.
In [11]:
1data[0]
Concatenate title and tags.
In [12]:
1all_title_type_column = [f'{row["title"]}-{row["allTags"]}' if row["title"] is not None else row["title"] for row in data]
Create the embeddings for Title & Tag (~3 minutes).
In [13]:
1# Remove [:3000] if you want to vectorize all rows (~60 minutes)2all_embeddings = model.encode(all_title_type_column[:3000])3all_embeddings.shape
Merge the original data with the vector data.
In [14]:
1# Remember the list will be only 3,000 elements2for row, embedding in zip(data, all_embeddings):3 row['embedding'] = embedding
In [15]:
1data[0]
4. Create table for movie information and vectors
In [16]:
1%%sql2DROP TABLE IF EXISTS movie_with_tags_with_vectors;3 4CREATE TABLE movie_with_tags_with_vectors (5 movieId BIGINT(20) DEFAULT NULL,6 title text CHARACTER SET utf8 COLLATE utf8_general_ci,7 genres text CHARACTER SET utf8 COLLATE utf8_general_ci,8 allTags longtext CHARACTER SET utf8mb4,9 vector BLOB10)
Create a database connection using SQLAlchemy. We are going to use an SQLAlchemy connection here because one
column of data is numpy arrays. The SingleStoreDB SQLAlchemy driver will automatically convert those to
the correct binary format when uploading, so it's a bit more convenient than doing the conversions and
formatting manually for the %sql magic command.
In [17]:
1from singlestoredb import create_engine2 3conn = create_engine().connect()
Insert the data. Some rows might encounter errors due to unsupported characters.
In [18]:
1import sqlalchemy as sa2 3sql_query = sa.text('''4 INSERT INTO movie_with_tags_with_vectors (5 movieId,6 title,7 genres,8 allTags,9 vector10 )11 VALUES (12 :movieId,13 :title,14 :genres,15 :allTags,16 :embedding17 )18 ''')19 20conn.execute(sql_query, data[:3000])
5. Marrying Search ❤️ Semantic Search ❤️ Analytics
Build autocomplete search
This is en experimentat we started with to render a full text search.
In [19]:
1%%sql2WITH queryouter AS (3 SELECT DISTINCT(title), movieId, MATCH(title) AGAINST ('Pocahontas*') as relevance4 FROM movies5 WHERE MATCH(title) AGAINST ('Pocahontas*')6 ORDER BY relevance DESC7 LIMIT 10)8 SELECT title, movieId FROM queryouter;
Create user favorite movie tables
In [20]:
1%%sql2CREATE ROWSTORE TABLE IF NOT EXISTS user_choice (3 userid text CHARACTER SET utf8 COLLATE utf8_general_ci,4 title text CHARACTER SET utf8 COLLATE utf8_general_ci,5 ts datetime DEFAULT NULL,6 KEY userid (userid)7)
Enter dummy data for testing purposes.
In [21]:
1%%sql2INSERT INTO user_choice (userid, title, ts)3 VALUES ('user1', 'Zone 39 (1997)', '2022-01-01 00:00:00'),4 ('user1', 'Star Trek II: The Wrath of Khan (1982)', '2022-01-01 00:00:00'),5 ('user1', 'Giver, The (2014)', '2022-01-01 00:00:00');
Build semantic search for a movie recommendation
In [22]:
1%%sql2WITH3 table_match AS (4 SELECT5 m.title,6 m.movieId,7 m.vector8 FROM9 user_choice t10 INNER JOIN movie_with_tags_with_vectors m ON m.title = t.title11 WHERE12 userid = 'user1'13 ),14 movie_pairs AS (15 SELECT16 m1.movieId AS movieId1,17 m1.title AS title1,18 m2.movieId AS movieId2,19 m2.title AS title2,20 DOT_PRODUCT(m1.vector, m2.vector) AS similarity21 FROM22 table_match m123 CROSS JOIN movie_with_tags_with_vectors m224 WHERE25 m1.movieId != m2.movieId26 AND NOT EXISTS (27 SELECT28 129 FROM30 user_choice uc31 WHERE32 uc.userid = 'user1'33 AND uc.title = m2.title34 )35 ),36 movie_match AS (37 SELECT38 movieId1,39 title1,40 movieId2,41 title2,42 similarity43 FROM44 movie_pairs45 ORDER BY46 similarity DESC47 ),48 distinct_count AS (49 SELECT DISTINCT50 movieId2,51 title2 AS Title,52 ROUND(AVG(similarity), 4) AS Rating_Match53 FROM54 movie_match55 GROUP BY56 movieId2,57 title258 ORDER BY59 Rating_Match DESC60 ),61 average_ratings AS (62 SELECT63 movieId,64 AVG(rating) AS Avg_Rating65 FROM66 ratings67 GROUP BY68 movieId69 )70SELECT71 dc.Title,72 dc.Rating_Match as 'Match Score',73 ROUND(ar.Avg_Rating, 1) AS 'Average User Rating'74FROM75 distinct_count dc76 JOIN average_ratings ar ON dc.movieId2 = ar.movieId77ORDER BY78 dc.Rating_Match DESC79LIMIT80 5;
6. What are you looking for?
In [23]:
1search_embedding = model.encode("I want see a French comedy movie")
In [24]:
1sql_query = sa.text('''2 SELECT title, genres, DOT_PRODUCT(vector, :vector) AS score FROM movie_with_tags_with_vectors tv3 ORDER BY Score DESC4 LIMIT 105''')6 7results = conn.execute(sql_query, dict(vector=search_embedding))8 9for i, res in enumerate(results):10 print(f"{i + 1}: {res.title} {res.genres} Score: {res.score}")
Clean up
In [25]:
1%%sql2DROP DATABASE IF EXISTS movie_recommender
Details
About this Template
Movie recommendation engine using vectors stored in SingleStore to find your next watch.
This Notebook can be run in Standard and Enterprise deployments.
Tags
advancedvectordbgenaiopenai
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.
License
This Notebook has been released under the Apache 2.0 open source license.