SingleStore Notebooks
New

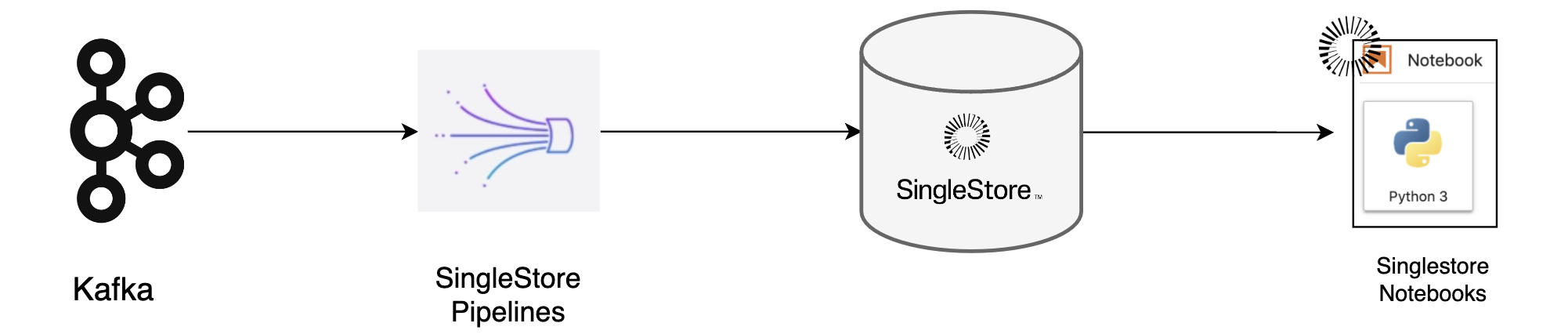


Real-Time Event Monitoring Dataset From Kafka
Notebook
Note
This notebook can be run on a Free Starter Workspace. To create a Free Starter Workspace navigate to Start using the left nav. You can also use your existing Standard or Premium workspace with this Notebook.
Introduction
The Real-Time Event Monitoring use case illustrates how to leverage Singlestore's capabilities to process and analyze streaming data from a Kafka data source. This demo showcases the ability to ingest real-time events, such as application logs or user activities, and perform immediate analysis to gain actionable insights. By working through this example, new users will learn how to set up a Kafka data pipeline, ingest streaming data into Singlestore, and execute real-time queries to monitor event types, user activity patterns, and detect anomalies. This use case highlights the power of Singlestore in providing timely and relevant information for decision-making in dynamic environments.
How to use this notebook
Create a database (You can skip this Step if you are using Free Starter Tier)
We need to create a database to work with in the following examples.
In [1]:
1shared_tier_check = %sql show variables like 'is_shared_tier'2if not shared_tier_check or shared_tier_check[0][1] == 'OFF':3 %sql DROP DATABASE IF EXISTS EventAnalysis;4 %sql CREATE DATABASE EventAnalysis;
Action Required
If you have a Free Starter Workspace deployed already, select the database from drop-down menu at the top of this notebook. It updates the connection_url to connect to that database.
Create Table
In [2]:
1%%sql2CREATE TABLE IF NOT EXISTS eventsdata /* Creating table for sample data. */ (3 `user_id` varchar(120) DEFAULT NULL,4 `event_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,5 `advertiser` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,6 `campaign` varchar(110) DEFAULT NULL,7 `gender` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,8 `income` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,9 `page_url` varchar(512) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,10 `region` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,11 `country` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL12)
Load Data using Pipeline
In [3]:
1%%sql2 3CREATE PIPELINE IF NOT EXISTS eventsdata /* Creating pipeline for sample data. */4AS LOAD DATA KAFKA 'public-kafka.memcompute.com:9092/ad_events'5ENABLE OUT_OF_ORDER OPTIMIZATION6DISABLE OFFSETS METADATA GC7INTO TABLE `eventsdata`8FIELDS TERMINATED BY '\t' ENCLOSED BY '' ESCAPED BY '\\'9LINES TERMINATED BY '\n' STARTING BY ''10(11 `events`.`user_id`,12 `events`.`event_name`,13 `events`.`advertiser`,14 `events`.`campaign`,15 `events`.`gender`,16 `events`.`income`,17 `events`.`page_url`,18 `events`.`region`,19 `events`.`country`20);21 22START PIPELINE `eventsdata`;
In [4]:
1%%sql2SELECT COUNT(*) FROM `eventsdata`
Sample Queries
Events by Region
In [5]:
1%%sql2SELECT events.country3AS `events.country`,4COUNT(events.country) AS 'events.countofevents'5FROM eventsdata AS events6GROUP BY 1 ORDER BY 2 DESC LIMIT 5;
Events by Top 5 Advertisers
In [6]:
1%%sql2SELECT3 events.advertiser AS `events.advertiser`,4 COUNT(*) AS `events.count`5FROM eventsdata AS events6WHERE7 (events.advertiser LIKE '%Subway%' OR events.advertiser LIKE '%McDonalds%' OR events.advertiser LIKE '%Starbucks%' OR events.advertiser LIKE '%Dollar General%' OR events.advertiser LIKE '%YUM! Brands%')8GROUP BY 19ORDER BY 2 DESC;
Ad visitors by gender and income
In [7]:
1%%sql2SELECT * FROM (3SELECT *, DENSE_RANK() OVER (ORDER BY z___min_rank) as z___pivot_row_rank, RANK() OVER (PARTITION BY z__pivot_col_rank ORDER BY z___min_rank) as z__pivot_col_ordering, CASE WHEN z___min_rank = z___rank THEN 1 ELSE 0 END AS z__is_highest_ranked_cell FROM (4SELECT *, MIN(z___rank) OVER (PARTITION BY `events.income`) as z___min_rank FROM (5SELECT *, RANK() OVER (ORDER BY CASE WHEN z__pivot_col_rank=1 THEN (CASE WHEN `events.count` IS NOT NULL THEN 0 ELSE 1 END) ELSE 2 END, CASE WHEN z__pivot_col_rank=1 THEN `events.count` ELSE NULL END DESC, `events.count` DESC, z__pivot_col_rank, `events.income`) AS z___rank FROM (6SELECT *, DENSE_RANK() OVER (ORDER BY CASE WHEN `events.gender` IS NULL THEN 1 ELSE 0 END, `events.gender`) AS z__pivot_col_rank FROM (7SELECT8 events.gender AS `events.gender`,9 events.income AS `events.income`,10 COUNT(*) AS `events.count`11FROM eventsdata AS events12WHERE13 (events.income <> 'unknown' OR events.income IS NULL)14GROUP BY 1,2) ww15) bb WHERE z__pivot_col_rank <= 1638416) aa17) xx18) zz19WHERE (z__pivot_col_rank <= 50 OR z__is_highest_ranked_cell = 1) AND (z___pivot_row_rank <= 500 OR z__pivot_col_ordering = 1) ORDER BY z___pivot_row_rank;
Pipeline will keep pushing data from the kafka topic. Once your data is loaded you can stop the pipeline using below command
In [8]:
1%%sql2STOP PIPELINE eventsdata
Conclusion
We have shown how to connect to Kafka using Pipelines and insert data into SinglestoreDB. These techniques should enable you to
integrate your Kafka topics with SingleStoreDB.
Clean up
Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created.
Drop the pipeline using below command
In [9]:
1%%sql2#DROP PIPELINE eventsdata
In [10]:
1#shared_tier_check = %sql show variables like 'is_shared_tier'2#if not shared_tier_check or shared_tier_check[0][1] == 'OFF':3# %sql DROP DATABASE IF EXISTS EventAnalysis;4#else:5# %sql DROP TABLE eventsdata;
Details
About this Template
The Real-Time Event Monitoring use case illustrates how to leverage SingleStore's capabilities to process and analyze streaming data from a Kafka data source.
This Notebook can be run in Shared Tier, Standard and Enterprise deployments.
Tags
starterloaddatakafka
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.
License
This Notebook has been released under the Apache 2.0 open source license.