SingleStore Notebooks
New


Retrieval Augmented Question & Answering with Amazon Bedrock
Notebook
Note
This notebook can be run on a Free Starter Workspace. To create a Free Starter Workspace navigate to Start using the left nav. You can also use your existing Standard or Premium workspace with this Notebook.
Challenges
When trying to solve a Question Answering task over a larger document corpus with the help of LLMs we need to master the following challenges (amongst others):
How to manage large document(s) that exceed the token limit
How to find the document(s) relevant to the question being asked
Infusing knowledge into LLM-powered systems
We have two primary types of knowledge for LLMs:
Parametric knowledge: refers to everything the LLM learned during training and acts as a frozen snapshot of the world for the LLM.
Source knowledge: covers any information fed into the LLM via the input prompt.
When trying to infuse knowledge into a generative AI - powered application we need to choose which of these types to target. Fine-tuning, explored in other workshops, deals with elevating the parametric knowledge through fine-tuning. Since fine-tuning is a resouce intensive operation, this option is well suited for infusing static domain-specific information like domain-specific langauage/writing styles (medical domain, science domain, ...) or optimizing performance towards a very specific task (classification, sentiment analysis, RLHF, instruction-finetuning, ...).
In contrast to that, targeting the source knowledge for domain-specific performance uplift is very well suited for all kinds of dynamic information, from knowledge bases in structured and unstructured form up to integration of information from live systems. This Lab is about retrieval-augmented generation, a common design pattern for ingesting domain-specific information through the source knowledge. It is particularily well suited for ingestion of information in form of unstructured text with semi-frequent update cycles.
In this notebook we explain how to utilize the RAG (retrieval-agumented generation) pattern originating from this paper published by Lewis et al in 2021. It is particularily useful for Question Answering by finding and leveraging the most useful excerpts of documents out of a larger document corpus providing answers to the user questions.
Prepare documents
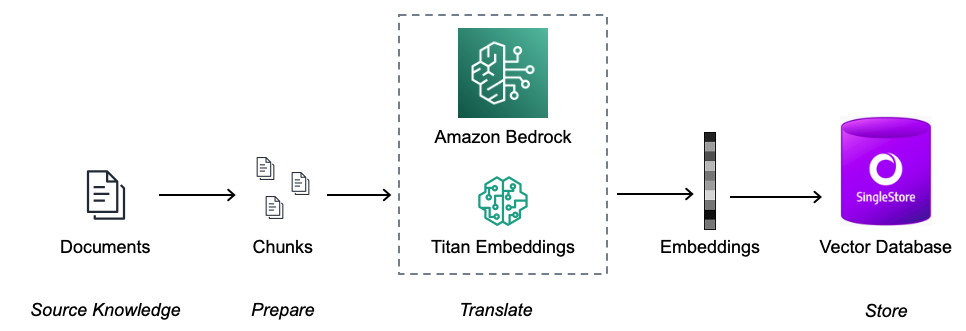
Before being able to answer the questions, the documents must be processed and a stored in a document store index
Load the documents
Process and split them into smaller chunks
Create a numerical vector representation of each chunk using Amazon Bedrock Titan Embeddings model
Create an index using the chunks and the corresponding embeddings
Ask question
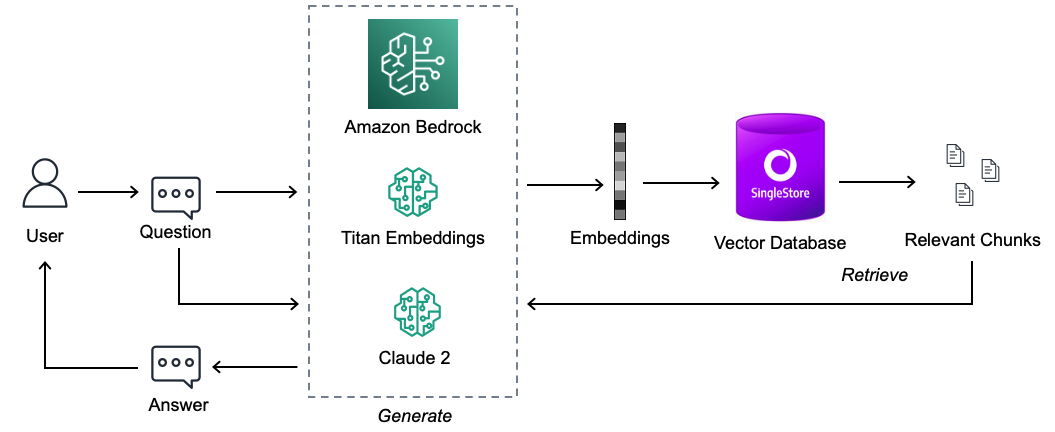
When the documents index is prepared, you are ready to ask the questions and relevant documents will be fetched based on the question being asked. Following steps will be executed.
Create an embedding of the input question
Compare the question embedding with the embeddings in the index
Fetch the (top N) relevant document chunks
Add those chunks as part of the context in the prompt
Send the prompt to the model under Amazon Bedrock
Get the contextual answer based on the documents retrieved
Usecase
Dataset
In this example, you will use several years of Amazon's Letter to Shareholders as a text corpus to perform Q&A on.
Implementation
In order to follow the RAG approach this notebook is using the LangChain framework where it has integrations with different services and tools that allow efficient building of patterns such as RAG. We will be using the following tools:
LLM (Large Language Model): Anthropic Claude available through Amazon Bedrock
This model will be used to understand the document chunks and provide an answer in human friendly manner.
Embeddings Model: Amazon Titan Embeddings available through Amazon Bedrock
This model will be used to generate a numerical representation of the textual documents
Document Loader:
PDF Loader available through LangChain for PDFs
These are loaders that can load the documents from a source, for the sake of this notebook we are loading the sample files from a local path. This could easily be replaced with a loader to load documents from enterprise internal systems.
Vector Store: SingleStoreDB available through LangChain In this notebook we are using SingleStoreDB to store both the embeddings and the documents.
Then begin with instantiating the LLM and the Embeddings model. Here we are using Anthropic Claude to demonstrate the use case.
Note: It is possible to choose other models available with Bedrock. You can replace the model_id as follows to change the model.
llm = Bedrock(model_id="...")
In [1]:
1!pip install boto3==1.34.74 langchain==0.1.14 pypdf==4.1.0 tiktoken==0.6.0 SQLAlchemy==2.0.29 --quiet
In [2]:
1import getpass2 3os.environ['AWS_DEFAULT_REGION']='us-east-1'4os.environ['AWS_ACCESS_KEY_ID']= getpass.getpass("AWS_ACCESS_KEY_ID: ")5os.environ['AWS_SECRET_ACCESS_KEY']=getpass.getpass("AWS_SECRET_ACCESS_KEY: ")
In [3]:
1import boto32import json3import sys
In [4]:
1from io import StringIO2import sys3import textwrap4 5 6def print_ww(*args, width: int = 140, **kwargs):7 """Like print(), but wraps output to `width` characters (default 140)"""8 buffer = StringIO()9 try:10 _stdout = sys.stdout11 sys.stdout = buffer12 print(*args, **kwargs)13 output = buffer.getvalue()14 finally:15 sys.stdout = _stdout16 for line in output.splitlines():17 print("\n".join(textwrap.wrap(line, width=width)))
In [5]:
1session = boto3.session.Session()2bedrock_client = session.client('bedrock')
Setup langchain
We create an instance of the Bedrock classes for the LLM and the embedding models. At the time of writing, Bedrock supports one embedding model and therefore we do not need to specify any model id. To be able to compare token consumption across the different RAG-approaches shown in the workshop labs we use langchain callbacks to count token consumption.
In [6]:
1bedrock_runtime_client = session.client('bedrock-runtime')2# We will be using the Titan Embeddings Model to generate our Embeddings.3from langchain.embeddings import BedrockEmbeddings4from langchain.llms.bedrock import Bedrock5from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler6 7# - create the Anthropic Model8llm = Bedrock(model_id="anthropic.claude-v2",9 client=bedrock_runtime_client,10 model_kwargs={11 'max_tokens_to_sample': 20012 },13 callbacks=[StreamingStdOutCallbackHandler()])14 15# - create the Titan Embeddings Model16bedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1",17 client=bedrock_runtime_client)
Data Preparation
Let's first download some of the files to build our document store.
In this example, you will use several years of Amazon's Letter to Shareholders as a text corpus to perform Q&A on.
Note
To get the external files, please add s2.q4cdn.com to the notebook Firewall.
In [7]:
1!mkdir -p ./RAG_Bedrock_data2 3from urllib.request import urlretrieve4urls = [5 'https://s2.q4cdn.com/299287126/files/doc_financials/2023/ar/2022-Shareholder-Letter.pdf',6 'https://s2.q4cdn.com/299287126/files/doc_financials/2022/ar/2021-Shareholder-Letter.pdf',7 'https://s2.q4cdn.com/299287126/files/doc_financials/2021/ar/Amazon-2020-Shareholder-Letter-and-1997-Shareholder-Letter.pdf',8 'https://s2.q4cdn.com/299287126/files/doc_financials/2020/ar/2019-Shareholder-Letter.pdf'9]10 11filenames = [12 'AMZN-2022-Shareholder-Letter.pdf',13 'AMZN-2021-Shareholder-Letter.pdf',14 'AMZN-2020-Shareholder-Letter.pdf',15 'AMZN-2019-Shareholder-Letter.pdf'16]17 18metadata = [19 dict(year=2022, source=filenames[0]),20 dict(year=2021, source=filenames[1]),21 dict(year=2020, source=filenames[2]),22 dict(year=2019, source=filenames[3])]23 24data_root = "./RAG_Bedrock_data/"25 26for idx, url in enumerate(urls):27 file_path = data_root + filenames[idx]28 urlretrieve(url, file_path)
As part of Amazon's culture, the CEO always includes a copy of the 1997 Letter to Shareholders with every new release. This will cause repetition, take longer to generate embeddings, and may skew your results. In the next section you will take the downloaded data, trim the 1997 letter (last 3 pages) and overwrite them as processed files.
In [8]:
1from pypdf import PdfReader, PdfWriter2import glob3 4local_pdfs = glob.glob(data_root + '*.pdf')5 6for local_pdf in local_pdfs:7 pdf_reader = PdfReader(local_pdf)8 pdf_writer = PdfWriter()9 for pagenum in range(len(pdf_reader.pages)-3):10 page = pdf_reader.pages[pagenum]11 pdf_writer.add_page(page)12 13 with open(local_pdf, 'wb') as new_file:14 new_file.seek(0)15 pdf_writer.write(new_file)16 new_file.truncate()
After downloading we can load the documents with the help of DirectoryLoader from PyPDF available under LangChain and splitting them into smaller chunks.
Note: The retrieved document/text should be large enough to contain enough information to answer a question; but small enough to fit into the LLM prompt. Also the embeddings model has a limit of the length of input tokens limited to 512 tokens, which roughly translates to ~2000 characters. For the sake of this use-case we are creating chunks of roughly 1000 characters with an overlap of 100 characters using RecursiveCharacterTextSplitter.
In [9]:
1import numpy as np2from langchain.text_splitter import RecursiveCharacterTextSplitter3from langchain.document_loaders import PyPDFLoader4 5documents = []6 7for idx, file in enumerate(filenames):8 loader = PyPDFLoader(data_root + file)9 document = loader.load()10 for document_fragment in document:11 document_fragment.metadata = metadata[idx]12 13 #print(f'{len(document)} {document}\n')14 documents += document15 16# - in our testing Character split works better with this PDF data set17text_splitter = RecursiveCharacterTextSplitter(18 # Set a really small chunk size, just to show.19 chunk_size = 1000,20 chunk_overlap = 100,21)22 23docs = text_splitter.split_documents(documents)
Before we are proceeding we are looking into some interesting statistics regarding the document preprocessing we just performed:
In [10]:
1avg_doc_length = lambda documents: sum([len(doc.page_content) for doc in documents])//len(documents)2print(f'Average length among {len(documents)} documents loaded is {avg_doc_length(documents)} characters.')3print(f'After the split we have {len(docs)} documents as opposed to the original {len(documents)}.')4print(f'Average length among {len(docs)} documents (after split) is {avg_doc_length(docs)} characters.')
We had 4 PDF documents which have been split into smaller chunks.
Now we can see how a sample embedding would look like for one of those chunks.
In [11]:
1sample_embedding = np.array(bedrock_embeddings.embed_query(docs[0].page_content))2print("Sample embedding of a document chunk: ", sample_embedding)3print("Size of the embedding: ", sample_embedding.shape)
Following the very same approach embeddings can be generated for the entire corpus and stored in a vector store.
This can be easily done using SingleStoreDB implementation inside LangChain which takes input the embeddings model and the documents to create the entire vector store.
⚠️⚠️⚠️ NOTE: it might take few minutes to run the following cell ⚠️⚠️⚠️
In [12]:
1from langchain.vectorstores import SingleStoreDB2 3db = SingleStoreDB.from_documents(4 docs,5 bedrock_embeddings,6 table_name = "amazon_data"7)
Similarity Search
Here you will set your search query, and look for documents that match.
In [13]:
1query = "How has AWS evolved?"
The first step would be to create an embedding of the query such that it could be compared with the documents
In [14]:
1query_embedding = bedrock_embeddings.embed_query("This is a content of the document")2np.array(query_embedding)
Basic Similarity Search
The results that come back from the similarity_search_with_score API are sorted by score from highest to lowest. The score value is represented by Dot product. Higher scores are better, for normalized vector embeddings this would approch 1.
In [15]:
1results_with_scores = db.similarity_search_with_score(query)2for doc, score in results_with_scores:3 print(f"Content: {doc.page_content}\nMetadata: {doc.metadata}\nScore: {score}\n\n")
Similarity Search with Metadata Filtering
Additionally, you can provide metadata to your query to filter the scope of your results. The filter parameter for search queries is a dictionary of metadata key/value pairs that will be matched to results to include/exclude them from your query.
In [16]:
1filter = dict(year=2022)
In the next section, you will notice that your query has returned less results than the basic search, because of your filter criteria on the resultset.
In [17]:
1results_with_scores = db.similarity_search_with_score(query, filter=filter)2for doc, score in results_with_scores:3 print(f"Content: {doc.page_content}\nMetadata: {doc.metadata}, Score: {score}\n\n")
Top-K Matching
Top-K Matching is a filtering technique that involves a 2 stage approach.
Perform a similarity search, returning the top K matches.
Apply your metadata filter on the smaller resultset.
Note: A caveat for Top-K matching is that if the value for K is too small, there is a chance that after filtering there will be no results to return.
Using Top-K matching requires 2 values:
k, the max number of results to return at the end of our queryfetch_k, the max number of results to return from the similarity search before applying filters
In [18]:
1results = db.similarity_search(query, filter=filter, k=2, fetch_k=4)2for doc in results:3 print(f"Content: {doc.page_content}\nMetadata: {doc.metadata}\n\n")
Now we have the relevant documents, it's time to use the LLM to generate an answer based on these documents.
We will take our inital prompt, together with our relevant documents which were retreived based on the results of our similarity search. We then by combining these create a prompt that we feed back to the model to get our result. At this point our model should give us highly informed information on how we can change the tire of our specific car as it was outlined in our manual.
LangChain provides an abstraction of how this can be done easily.
Customisable option
In the above scenario you explored the quick and easy way to get a context-aware answer to your question. Now let's have a look at a more customizable option with the help of RetrievalQA where you can customize how the documents fetched should be added to prompt using chain_type parameter. Also, if you want to control how many relevant documents should be retrieved then change the k parameter in the cell below to see different outputs. In many scenarios you might want to know which were the source documents that the LLM used to generate the answer, you can get those documents in the output using return_source_documents which returns the documents that are added to the context of the LLM prompt. RetrievalQA also allows you to provide a custom prompt template which can be specific to the model.
Note: In this example we are using Anthropic Claude as the LLM under Amazon Bedrock, this particular model performs best if the inputs are provided under Human: and the model is requested to generate an output after Assistant:. In the cell below you see an example of how to control the prompt such that the LLM stays grounded and doesn't answer outside the context.
In [19]:
1from langchain.chains import RetrievalQA2from langchain.prompts import PromptTemplate3 4prompt_template = """5 6Human: Use the following pieces of context to provide a concise answer to the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.7 8{context}9 10Question: {question}11 12Assistant:"""13PROMPT = PromptTemplate(14 template=prompt_template, input_variables=["context", "question"]15)16 17qa = RetrievalQA.from_chain_type(18 llm=llm,19 chain_type="stuff",20 retriever=db.as_retriever(21 search_type="similarity", search_kwargs={"k": 3}22 ),23 return_source_documents=True,24 chain_type_kwargs={"prompt": PROMPT},25 callbacks=[StreamingStdOutCallbackHandler()]26)
In [20]:
1query = "How did AWS evolve?"2result = qa.invoke({"query": query})3 4print(f'Query: {result["query"]}\n')5print_ww(f'Result: {result["result"]}\n')6print(f'\nContext Documents: ')7for srcdoc in result["source_documents"]:8 print_ww(f'{srcdoc}\n')
In [21]:
1query = "Why is Amazon successful?"2result = qa.invoke({"query": query})3 4print(f'Query: {result["query"]}\n')5print_ww(f'Result: {result["result"]}\n')6print(f'\nContext Documents: ')7for srcdoc in result["source_documents"]:8 print_ww(f'{srcdoc}\n')
In [22]:
1query = "What business challenges has Amazon experienced?"2result = qa.invoke({"query": query})3 4print(f'Query: {result["query"]}\n')5print_ww(f'Result: {result["result"]}\n')6print(f'\nContext Documents: ')7for srcdoc in result["source_documents"]:8 print_ww(f'{srcdoc}\n')
In [23]:
1query = "How was Amazon impacted by COVID-19?"2result = qa.invoke({"query": query})3 4print(f'Query: {result["query"]}\n')5print_ww(f'Result: {result["result"]}\n')6print(f'\nContext Documents: ')7for srcdoc in result["source_documents"]:8 print_ww(f'{srcdoc}\n')
Clean up
Clear the downloaded PDFs and the amazon_data table
In [24]:
1!rm -rf ./RAG_Bedrock_data
In [25]:
1%%sql2DROP TABLE IF EXISTS amazon_data
Conclusion
Retrieval augmented generation is an important technique that combines the power of large language models with the precision of retrieval methods. By augmenting generation with relevant retrieved examples, the responses we recieved become more coherent, consistent and grounded. You should feel proud of learning this innovative approach. I'm sure the knowledge you've gained will be very useful for building creative and engaging language generation systems.
In the above implementation of RAG based Question Answering we have explored the following concepts and how to implement them using Amazon Bedrock and it's LangChain integration.
Loading documents of different kind and generating embeddings to create a vector store
Retrieving documents to the question
Preparing a prompt which goes as input to the LLM
Present an answer in a human friendly manner
Take-aways
Leverage various models available under Amazon Bedrock to see alternate outputs
Explore options such as persistent storage of embeddings and document chunks
Integration with enterprise data stores
Thank You
Details
About this Template
Infuse domain-specific knowledge from SingleStoreDB into generative AI models on Amazon Bedrock to showcase Question & Answering using RAG (retrieval-agumented generation) to improve the quality of responses.
This Notebook can be run in Shared Tier, Standard and Enterprise deployments.
Tags
vectordbgenaibedrockragstarter
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.
License
This Notebook has been released under the Apache 2.0 open source license.