


Hackathons are a big part of SingleStore's culture and a lot of our differentiating features have gotten their start during them. For this hackathon, a couple of us decided to dogfood SingleStore and build a serverless app.
We host two hackathons per year where anybody is free to work on any project they'd like (we have categories but they are not very strict and it's okay to ignore them):
- A longer one in July-August which is 5 days long.
- A shorter one in January-February which goes for 2 days.
We just held our longer hackathon in July, and one of the categories was "Dogfooding SingleStore". So, we decided to build an app using SingleStore and a serverless backend technology. The goal of this project was to demonstrate that SingleStore works really well with serverless backends, especially with the beta release of the SQL HTTP API a couple of months ago.
The SQL HTTP API, a new feature of SingleStore that's currently in Preview, allows you to send all SingleStore-supported SQL commands to your cluster via HTTP. This features offers a number of advantages, especially in serverless or microservices architectures because the cluster handles connection pooling for us.
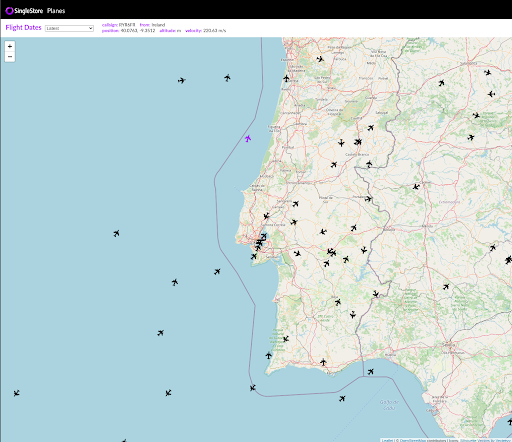
The application we decided to build is a graphical interface for showing all planes flying worldwide in real time using data from the OpenSky API. This application was already one of our open source reference solutions on GitHub but it was implemented with a Node.js/Express server backend. So, we created a new reference solution with the same UI but replaced the backend with a serverless implementation using Cloudflare Workers.
Our team was made up of:
- Lídia Custódio, Software Engineering Intern on the Singlestore Helios Team
- David Gomes, Engineering Manager on the Singlestore Helios Team
In this blog post, we'll talk about our experience building this application which is open source as well!

Our architecture is described in the diagram above. It consists of:
- A cron trigger Cloudflare Worker pulling data from the OpenSky API, cleaning it up a bit and saving it to a S3 bucket
- A SingleStore cluster running which pulls data from S3 with a SingleStore S3 pipeline.
- A REST API running on Cloudflare Workers which talks to a SingleStore cluster via the SQL HTTP API.
- We run our frontend with Cloudflare Pages.
This architecture is fairly simple and Cloudflare Workers will scale our API and frontend asset serving automatically for us. The SingleStore cluster can be resized as well if needed.
We could, however, simplify the architecture in the future by removing S3 from the equation. If SingleStore's pipelines supported loading data from HTTP, we could write a pipeline that loads data from HTTP and transforms it using a SingleStore stored procedure.
Why Cloudflare Workers?
We decided to use Cloudflare Workers over other serverless backend technologies such as AWS Lambda or Azure Functions. This was because Workers run on the edge and seemed fairly simple to set up.
Getting the SingleStore cluster running
This part was fairly easy, we just spun up a cluster in Singlestore Helios. The SQL HTTP API isn't enabled by default yet so we had to do that manually for this cluster (customers have to file a support ticket for this as of the time this blog post is being written).
The schema for this application is fairly simple to set up — there's a countries table and a flights table. Then, we have 2 SingleStore Pipelines to load data for each table. The schema is specified in our repository. The countries are loaded from a CSV file on S3 from Natural Earth Data. The flights are loaded with a pipeline as well, but from a set of CSV files that are also on S3. These files are populated by a cron trigger which we explain below.
Creating a cron trigger with Workers
Our goal was to show real-time flight data in the app. This meant that we would have to make periodic calls to the OpenSky API to get fresh data into our S3 bucket. To make this process easier and automated, we created a Cloudflare Worker with a cron trigger.
To create the cron trigger we added a field to our wrangler.toml configuration file that was created when creating a new Worker.
[triggers]
crons = ["*/1 * * * *"]
This will run a ScheduledEvent each minute. After talking with some folks from Cloudflare on their Discord, we found that doing anything more frequent than a minute isn't possible at the moment.
Then, the code for the worker is as simple as listening for a scheduled event:
addEventListener("scheduled", event => {
event.waitUntil(loadData());
});The loadData function will fetch the data from OpenSky API, clean it up a bit and upload it to a S3 bucket in AWS. We don't try to guarantee that only one of such workers is running at the same time. If multiple of them are scheduled at the same time, that's fine.The OpenSky API returns its current timestamp as well as the position and state for all flights in the world for that timestamp. This data then gets stored in S3 with that timestamp as the identifier and if 2 workers hit the same timestamp, the second call to S3 will just override the first one. In practice though, we've noticed that the cron trigger workers are very consistent and always running a minute apart from each other.
Writing this code wasn’t easy and involved a lot of debugging. We followed the documentation but we had a few issues:
- Cloudflare Workers doesn't yet have logging for cron triggers workers, so debugging our worker was really hard.
- Using the AWS SDK for JavaScript didn't work out of the box because it depends on some native Node.js modules that aren't supported in the Cloudflare Workers environment.
- We then pivoted towards calling the S3 API directly but getting the AWS API Authorization header right was really hard.
- Eventually, someone from the Cloudflare Workers community recommended aws4fetch which basically implements the Authorization header for us and allows us to more easily use the AWS HTTP API.
- In order to debug our worker, we changed it to listen both to a
scheduledevent as well as afetchevent, but this didn't go very well.
addEventListener("scheduled", event => {
// ...
});
addEventListener("fetch", event => {
// ...
});The goal with this was to allow us to "trigger" the worker more quickly by sending a GET request to its URL instead of having to wait for the next "tick" of the cron schedule (every minute). However, triggering the worker like this caused the cron trigger to stop working. We expected our worker to continue to execute every minute, and this took us a while to debug!

Creating the REST API with Workers
The previous worker’s only job was to upload the flight data to the S3 bucket. Now we need a way to fetch the necessary data from our database to show in our application. So, we created a new worker with the following API:
/api/datesreturns the list of timestamps for which we have flight data (one every minute)./api/flights/:datereturns all the flights at a specific date-time timestamp./api/countriesreturns the list of countries./api/countries/:datereturns an array of{name: string; count: number}objects that represent the number of flights over each country at a certain date-time timestamp.
(If you're looking for a proper tutorial on building APIs with Workers, we recommend this one.)
This Worker defines a fetch event listener:
import { handleRequest } from "./handler";
addEventListener("fetch", event => {
event.respondWith(handleRequest(event.request));
});And the handleRequest function looks like this:
import { Router, Request } from "itty-router";
import { Countries, CountriesCount } from "./handlers/countries";
import { Dates, Flights } from "./handlers/flight";
const router = Router();
router
.get("/api/flights/:date", Flights)
.get("/api/dates", Dates)
.get("/api/countries", Countries)
.get("/api/countries/:date", CountriesCount)
.get(
"*",
() =>
new Response("Not found", {
status: 404,
headers: {
"Access-Control-Allow-Origin": "*",
},
})
);
export const handleRequest = (request: Request): Response => {
return router.handle(request);
};Each route has a function associated with it. These functions (Flights, Dates, Countries and CountriesCount) all have a similar structure — they receive the request from the router and return a Response with the requested data. For example, this is what the function Countries looks like:
import { Request } from "itty-router";
import { getAllCountries } from "../data/countries_store";
export const Countries = async (): Promise<Response> => {
const body = JSON.stringify(await getAllCountries());
const headers = {
"Access-Control-Allow-Origin": "*",
"Content-type": "application/json",
};
return new Response(body, { headers });
};The main difference between these functions is the function they call to fetch the data. In this case, Countries calls for function getAllCountries which will return a list with all the countries. How do we fetch this data?
The SQL HTTP API and why it pairs so well with serverless applications
We fetch the data querying our cluster with the SQL HTTP API. There's a couple of reasons for this:
- In the serverless backend world, connection pooling is not an option since functions are scheduled ad-hoc. However, connection pooling is extremely important for application development and SingleStore's SQL HTTP API implements the pooling on the database's end.
- For Cloudflare Workers in specific (but also for some other serverless platforms), we're limited on the native APIs we can use and anything that can be done over HTTP is simplified. Without some work, mysql.js won't load in the Cloudflare Workers environment, but a
fetchcall "just works".
To query our database, we used the query/rows endpoint of the HTTP API. Our POST request's body contains our SQL query, any possible arguments to the query and the context database name.
To ease the process of creating a POST request, we created a wrapper query function. Here is a simple example with the getAllCountries function that we mentioned before:
export async function getAllCountries(): Promise<Country[]> {
const sql = `
select distinct
name
from
countries
group by
name
order by
name`;
const response = await query<Country>({
host,
username,
password,
sql,
database: "maps",
});
const countries = response.results[0].rows;
return countries;
}The query function returns a Promise with the results (or an error). Since query accepts a type argument (in this case, Country), the results will also be correctly typed.
We eventually want to open source this wrapper and make it more interesting with stateful authentication, result iteration and other neat features. However, this work is still being prioritized internally.
The SingleStore queries
The reason that SingleStore is so interesting for this app is because of its geospatial capabilities. In the app's user interface, we display which country a plane is currently hovering. We do this with the GEOGRAPHY_CONTAINS function:
select
f.load_date,
f.ica024,
f.callsign,
f.origin_country,
f.time_position,
f.last_contact,
f.longitude,
f.latitude,
f.baro_altitude,
f.on_ground,
f.velocity,
f.true_track,
f.vertical_rate,
f.altitude,
f.squawk,
f.spi,
f.position_source,
c.name as current_country
from
flights f
left outer join countries c on GEOGRAPHY_CONTAINS(c.boundary, f.position)
where
f.load_date = ?
order by
callsignIn the future, we could build some fun features on this app leveraging SingleStore's query performance.
Some examples include:
- Predicting how late a flight will be based on historical data and real-time indicators.
- Clicking on a country and seeing all flights which will hover it on their way to their destinations.
Continuous Integration and deployment
One of the most interesting parts of our project is our Continuous Integration setup. We made it such that:
- Frontend is auto-deployed to production (via Cloudflare Pages) on every commit to
main. - The API is auto-deployed to production on every commit to
main. - We weren't able to get the data loader to automatically deploy when it is changed.
Cloudflare Pages was fairly easy to set up since it can be connected to any GitHub repository via the Cloudflare UI.
For both the API and the data loader worker, we used cloudflare/wrangler-action to deploy through GitHub Actions and set it up like this:
.github/workflows/deploy.yml
name: Deploy
on:
push:
branches:
- main
paths:
- workers-api/**
- workers-data-load/**
- .github/workflows/deploy.yml
jobs:
deploy-api:
runs-on: ubuntu-latest
name: Deploy
steps:
- uses: actions/checkout@v2
- name: Publish
uses: cloudflare/wrangler-action@1.3.0
with:
apiToken: ${{ secrets.CF_API_TOKEN }}
workingDirectory: "workers-api"
deploy-data-load:
runs-on: ubuntu-latest
name: Deploy
steps:
- uses: actions/checkout@v2
- name: Publish
uses: cloudflare/wrangler-action@1.3.0
with:
apiToken: ${{ secrets.CF_API_TOKEN }}
workingDirectory: "workers-data-load"Conclusion
The hackathon was certainly a lot of fun, and we got to learn a lot about SingleStore's capabilities as well as how to build serverless edge applications. It's really important that databases which historically have only implemented connections on top of TCP start supporting HTTP as well for serverless backends.
With regard to Cloudflare Workers specifically, while it was extremely easy to get things running (for free), there's definitely some rough edges in the technology. This is to be expected since the product is quite new. We had to rely on the Discord community for Cloudflare Workers several times during the hackathon, and were always super pleased with the help that we got.
Our app is still running to this day and because it's serverless, we shouldn't have to do any maintenance (except maybe upgrading to a paid plan, but we're not expecting this application to be heavily used since it's just a demo).
These hackathons are a really important part of our culture and some of the features we talked about in this blog post, such as SingleStore Pipelines or the Singlestore Helios, were actually invented and prototyped during past hackathons. Oh and by the way, we're hiring engineers at SingleStore across a variety of teams and countries!
Footnotes:
[1]: Cloudflare introduced logs for Workers after our hackathon.













