

On Tuesday, November 12th, SingleStore will be presenting a workshop at AWS Partner Developer Day. The workshop will be held at the AWS office at 350 West Broadway in New York City. The workshop will be focused on teaching customers how to enable real-time, data-driven insights. In the workshop, Amazon Sagemaker, the AWS managed service for deploying machine learning models quickly, will be shown working with SingleStore, a highly performant, cloud-native database. SingleStore supports streaming data analytics and the ability to run operational analytics workloads on current data, blended in real time with historical data, not yesterday’s closed data from a nightly batch update.
Putting Machine Learning into Production
Productionalizing a machine learning (ML) model has three phases. The lifecycle of a model begins with a build phase, then a training phase. After that, a model is selected to be used by the business.
Some of the selected champion models are deployed into production. These are the models that have the potential to drive significant, immediate business value.
Many organizations today are leveraging Amazon SageMaker’s highly scalable algorithms and distributed, managed data science and machine learning platform to develop, train and deploy their models. In the workshop, we will begin by leveraging a Sagemaker Notebook to build and train an ML model.
What SingleStore Adds to ML and AI
SingleStore adds a great deal to machine learning and AI, and a large share of SingleStore customers are running machine learning models and AI programs in production using SingleStore.
SingleStore helps modernize existing data infrastructure. The rapid flow of data through the infrastructure is vital to machine learning and AI. New tools, such as Python programs or the use of SparkML for running models, can be integrated with SingleStore directly. Processing is fast, running at production speeds.
Big data systems based on Hadoop were sold and installed with the promise of supporting machine learning and AI. These systems do indeed gather large amounts of data together, where it’s used for the data science work that build machine learning models.
However, when it comes time to run the models, HDFS – the file system for Hadoop – is often too slow. Data is not stored in SQL format, and custom queries are needed to retrieve key information. The queries, however, run too slowly for production.
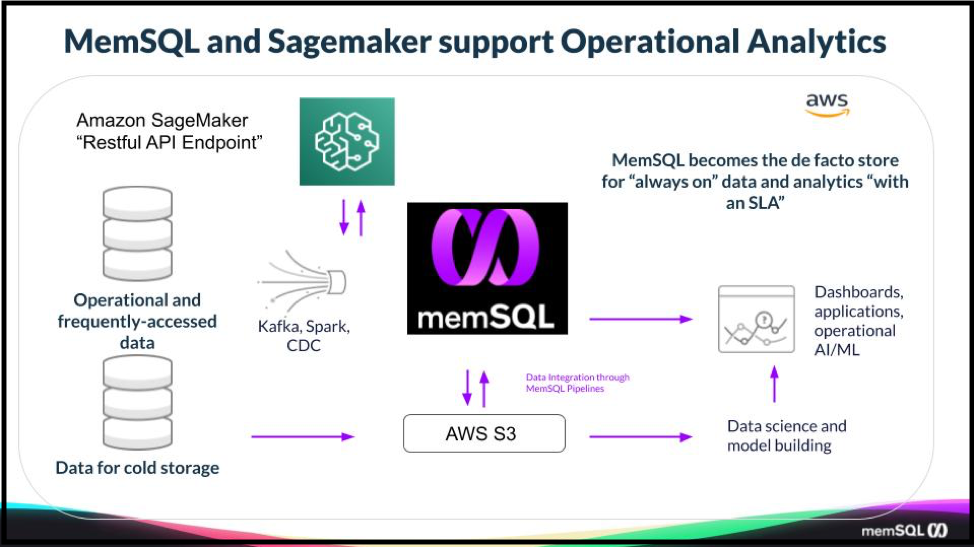
So data is transferred from the data lake to SingleStore for production. This has three key benefits: the data is now accessible to SQL queries; the queries run much faster; and the performance achieved is scalable, simply by adding more servers.

SingleStore integrates with a wide range of tools popular for use in developing and implementing machine learning models – many of which use Python as the programming language. Tools include pandas, NumPy, TensorFlow, scikit-learn, and named connectors in Microsoft SQL Server Analysis Services (SSAS), an analytics processing and data mining tool for Microsoft SQL Server. SSAS can pull in information from a wide range of different sources. The R programming language is also used, due to its facility with statistical computing and its widespread use for data mining.

All of these tools can be used along with SingleStore Pipelines. Data can be “scored on load” against a machine learning model. As data is transferred from a source – AWS S3, the Hadoop HDFS database, Kafka pipelines, or the computer’s file system – it is operated on by Python or executable code, scored against the model. This flexible capability allows models to be operationalized rapidly and for scoring to run at high speed.
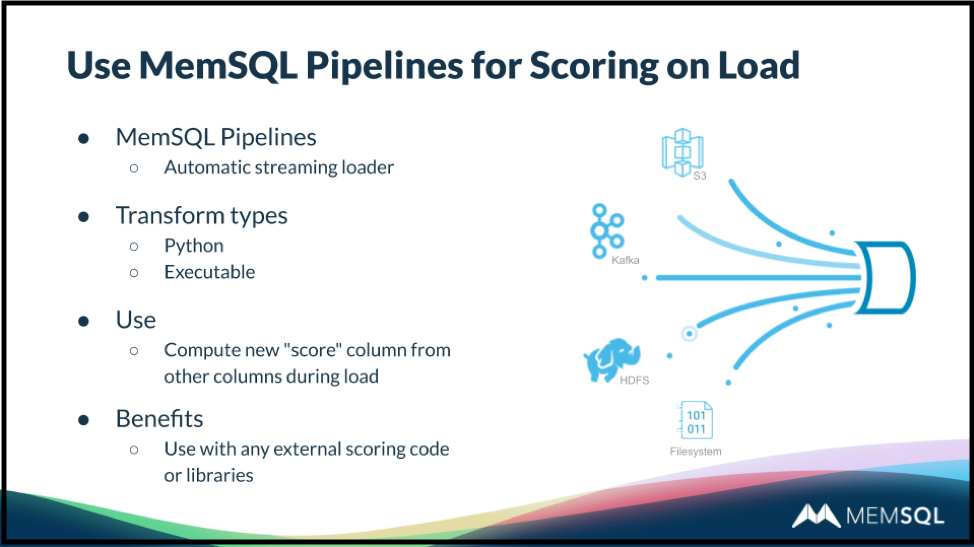
With SingleStore, user code can be implemented as user-defined functions (UDFs), stored procedures – the ability to run stored procedures on ingest is called Pipelines to Stored Procedures – user-defined aggregate functions, and more.
Because SingleStore is relational, with ANSI SQL support, common SQL functions such as joins and filters, and SQL-compatible tools (such as most business intelligence [BI] programs) are not only easy to use, but run fast, with scalability.

These capabilities allow SingleStore to work well as a partner environment for SageMaker.
What Happens in the Workshop
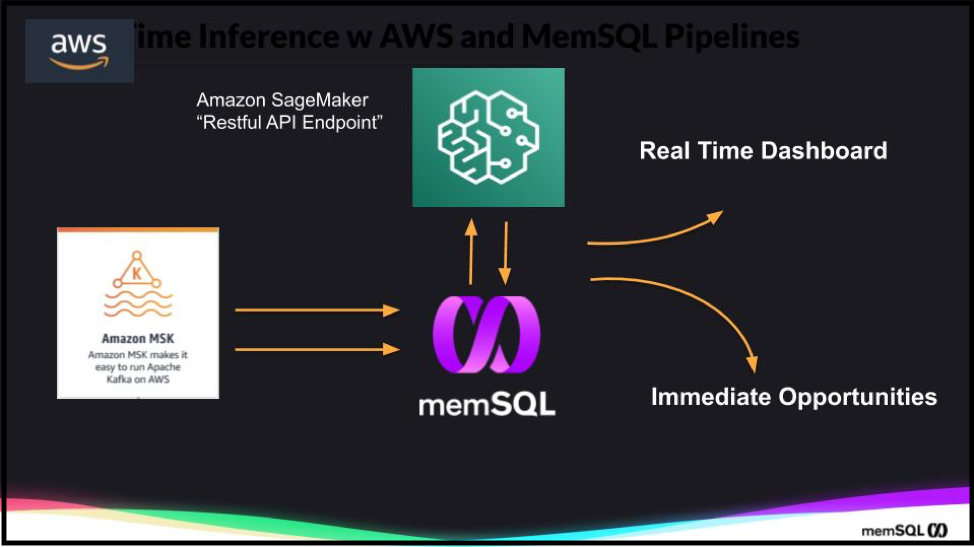
Once we have developed the ML model, it will be deployed in production, enabling potential significant value add to a real-time business process. This deployment step is also referred to as “operationalizing the model.”
With Sagemaker, our deployed model will be exposed as an inference API endpoint. At this point, we are ready to consume the ML model in a streaming data ingestion pipeline.
With SingleStore, both real time and historical data are available to both your training and operationalization environments, helping organizations greatly reduce time to value and operational costs, while at the same time improving the customer experience. As more data is made available to your model, it can be optimized over time, and dynamically redeployed and leveraged within SingleStore on AWS.
Participants in this half-day, hands-on workshop will be taught how to jointly deploy SingleStore real-time streaming ingest pipelines with Sagemaker inference ML endpoints. If you are a Data Engineer, Architect, or Developer, this session is designed for you.
We hope you can join us on November 12th in New York City, or at one of our future sessions.
For further information, email Mark Lochbihler, Director of Technical Alliances at SingleStore, or Chaitanya Hazarey, ML Specialist Solutions Architect at AWS.











