

This is the second blog post derived from the recent DZone webinar given by Rob Richardson, technical evangelist at SingleStore. (From the link, you can easily download the slides and stream the webinar.) Kubernetes was originally developed to manage containers running stateless workloads, such as computation-intensive processing tasks and web servers. It was then extended to allow you to manage stateful workloads, such as data tables and e-commerce sessions, but doing so is not easy. Rob is one of the relatively few people who have figured out how to do this well.
The webinar was well-attended, with a solid Q&A session at the end. There’s so much going on that we’ve split the webinar into three blog posts: The first blog post, Kubernetes and State; this blog post, which is the second in the series, Kubernetes File Storage, Configuration, and Secrets; and a third blog post, Kubernetes StatefulSets and Q&A. You can read through all three for education – or use them as a step-by-step road map for actual implementation. You can also see Rob’s Kubernetes 101 blog post for an introduction to Kubernetes.
As Rob mentions during his talk, SingleStore database software is well-suited for containerized software development, managed by Kubernetes. SingleStore has developed a Kubernetes Operator, which helps you use SingleStore within a containerized environment managed by Kubernetes. Alternatively, if you want to use a Kubernetes-controlled, elastic database in the cloud, without having to set up and maintain it yourself, consider Singlestore Helios. Singlestore Helios is available on AWS, Google Cloud Platform, and is coming soon on Microsoft Azure.
Following is a rough transcript of the middle part of the talk, illustrated by slides from the accompanying presentation. This second blog post dives into file storage in Kubernetes, Kubernetes configuration, and the use of secrets in Kubernetes.
Stateful Resources #1: Volumes
Here’s our first stop in the suite of stateful resources, volumes. With a volume, we probably want to store these files so the data isn’t lost to a pod restart, or to share data files between pods. Now the cool part is this is not that unlike a network share, where we just have a drive often on the network where we can store things. And so that’s kind of a good analog, but we’re actually going to create a symbolic link into the pod, so a certain directory just happens to be stored elsewhere.

Now, because it’s a network share, file locks don’t work the way we expect. So if I lock a file in one pod, and then try to read it or write it from the other pod, that operation will work just fine. So we need to architect our app slightly differently to not assume that files are locked. Perhaps each pod uses a different folder, or perhaps we’re only doing unique file names based on operations – but we need to be careful there, because file locks don’t work the way we expect.
So here’s a YAML file that defines a pod referencing a volume. And so I’ve eliminated some of the normal things that we would see in a pod file – all of the pieces about resiliency and health checks. But we’ve defined an image. We’ve defined a name for our container. And then we have this volume mount section, and this volume mount section talks about the details of the volume. So here, we give the name of the volume. And then the mount path – this is the path inside the container.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- image: nginx:alpine
name: myapp
# ... snip ...
volumeMounts:
- name: the-volume
mountPath: /path/in/container/to/dir
volumes:
- name: the-volume
hostPath:
path: /mnt/host/path/to/dir
So in /path/in/container/to/dir, if my app opens a file inside that directory, it’s as if it’s any other file running inside this container – it’s just a file on the file system. I can add more folders inside this directory. I can add more files to them. I can read and write those files, and to the application, it just believes that it’s part of the disk.
But this volume here is defined here, the-volume, and I can specify various mechanisms for getting that volume to be more durable. So in this case, I chose to make it a host path, and so here’s that path to the directory on the host. I could choose to put this inside my NAS or on a network share, or in an S3 blob, or wherever it makes sense to hold this data. I can make that much more durable.
Now, this is interesting, and it’s a great example of getting file storage off of my pod, into a more durable place. But it kind of mixes things. So the magic question is, well, who owns that storage spot – the developer, or Operations?
Should the developer own it, as they’re crafting the rest of that YAML file, and identifying the version of the image it should use? Should they own that hard drive? Or, Operations really wants to ensure that that’s backed up correctly. So do they want to identify the correct location, and perhaps the naming convention inside the SAN? And so we really want this separation between developer and Operations, and that’s where we can get into a really cool abstraction in Kubernetes where we can talk about persistent volumes and persistent volume claims.
Stateful Resources #2: Persistent Volumes and Persistent Volume Claims
Now, this does get a little bit hairy, so I’ve kind of nicely drawn it so that we can follow it. We have a storage system, a hard drive, and we can carve that storage up into blocks. We’ll call these blocks persistent volumes. Each block represents one thing that a pod can check out. So we’ll have a persistent volume, and then we’ll have a persistent volume claim that claims one of them. So a pod can say, “I need a hard drive and I need it to be five gigs.” And so it’ll go find a five gig spot and it’ll pull it out and it will sim link that as a folder within the container.
(This section of Rob’s talk, about persistent volumes and persistent volume claims, got kudos from a Kubernetes maintainer. Many organizations get partway through doing this work, give up, and hire an outsider to do it – but the explanation that Rob gives here should give you a fighting chance. – Ed.)
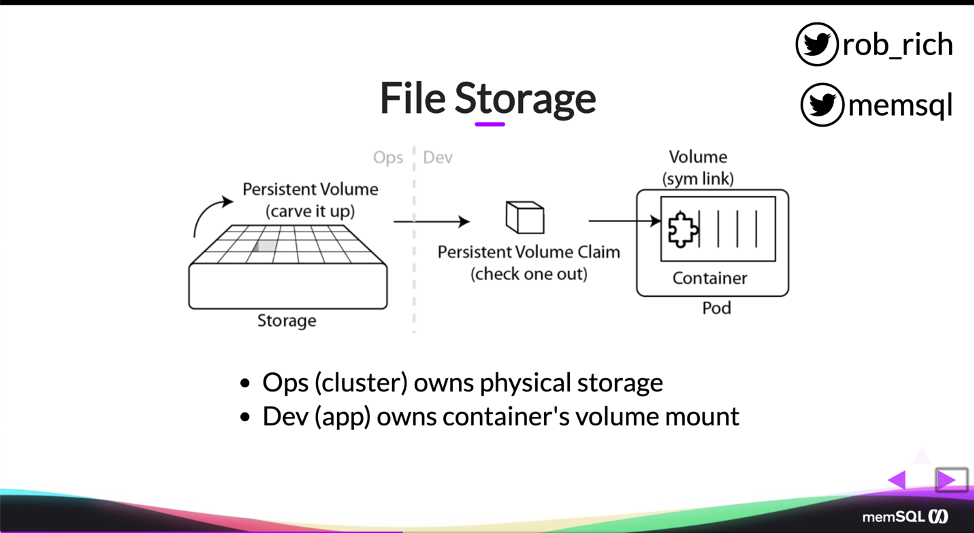
We have storage. We have the persistent volume. We have the persistent volume claim. And we have the pod definition. Now, the cool thing is the persistent volume claim and the pod can be owned by the developer. The persistent volume and the storage can be owned by Operations. And so we can have this really cool clean separation of concerns here, where we can ensure that that storage is backed up correctly and that it’s allocated according to our provisioning needs. And the developer can also assume that they just need storage and it just magically works, connecting it to the right folder within their pod. And so that’s a really elegant way to have persistent volumes and persistent volume claims that can separate the dev and ops points of responsibility.
So creating a persistent volume, here’s that ops part of it. We specify that host path, that path to where we want to actually store the directory. We can specify access modes, ReadWriteOnce in this case. (We can also say ReadWriteMany or ReadOnly .) And then we give it a storage size. In this case I said, “This path has a storage of 10 gigs. If you go over 10 gigs, then that drive is full.” Now, I may have more space on my hard drive, I just carve it into 10 gig pieces.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /mnt/host/path/to/dir
Here’s that persistent volume, and to claim it, the developer will claim a persistent volume claim specifying the details that they need. So in this case, I said I need something that is read write once and I need it to be at least three gigs. Now, the cool part is, we specified this as 10 gigs. I said I want three gigs or more and so it says, “Okay, I’ll grab that one.” We don’t need any other details other than the ReadWriteOnce match and the storage amount. We can specify other details like availability zone, affinity, or storage, speeds, quality of service details. But those are the two that we definitely need to do, ReadWriteOnce (or one of the other options) and the storage.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi # at least this much
So with that persistent volume claim, now here in my pod definition, rather than specifying where it’s actually stored, I’m going to reference that persistent volume claim’s name. So the pod will reference the persistent volume claim and all the rest of it will just work. Here in the volume mounts, I’m specifying the path and the container that I want it to connect to and everything just works.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- image: nginx:alpine
name: myapp
# ... snip ...
volumeMounts:
- name: the-volume
mountPath: /path/in/container/to/dir
volumes:
- name: the-volume
persistentVolumeClaim:
claimName: pv-claim
So we have the storage. We have that persistent volume. A pod can claim one of those persistent volume blocks and attach it into its container and now we have persistent storage inside of our pod. And we have that nice separation between dev and ops.
Stateful Resources #3: Configuration
So that’s persistent volumes, and now we have file storage. We can upload profile pictures. We can save CSV files that we have uploaded. All of the content associated with files, we can now stick into our application. But how do we know where that location is? Perhaps we want other config details or maybe we want config details that are environment specific. Now, the cool part about configuration within Kubernetes is we can mount these in two ways:
- As files on disk
- As environment variables
We’ll see examples of each.
In Kubernetes, here’s our simplistic example where we just list the environment variables that we want to define here in our pod. Here is the environment variable. Here’s the value we want it to be set at. And then, in our application-specific way, we can read that environment variable and take action.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- image: nginx:alpine
name: myapp
# ... snip ...
env:
- name: THE_MESSAGE
value: "Hello world"
- name: FOO
value: "bar"
Now, a similar mechanism. Who owns this configuration data? Again, we have to choose between dev vs. ops.
- Developer. Does the developer have to know all of the details in each environment?
- Operations. What if Operations really wants production secrets that are not exposed to developers?
And so let’s look at a mechanism within Kubernetes where we can split that out as well, the ConfigMap, which identifies all of those details. So for example, here in this ConfigMap, I have some data. I have a database, SingleStore. Logging is set to true. My API URL is set to this URL, and these can be environment specific details stored by operations. As a developer, I then just reference that ConfigMap by name and it just works.
apiVersion: v1
kind: ConfigMap
metadata:
name: the-configmap
data:
database: memsql
logging: 'true'
api_url: https://example.com/api
Here, instead of environment variables, I’m saying from ConfigMap ref and I just list that ConfigMap name. So as the developer, I can have one pod definition that will work in all environments. My application and my container can work identically through all environments. And then we just have environment-specific ConfigMaps that happen to be preloaded into our cluster so that we can reference the correct database. All those database connection details just get pulled right in and we’re able to connect to our database just fine.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- image: nginx:alpine
name: myapp
# ... snip ...
envFrom:
- configMapRef:
name: the-configmap # ConfigMap's name
ConfigMap as Env Vars
So, we can also mount this ConfigMap as files instead of as environment variables. And we may choose to do this so that it’s not available all the time, maybe a little bit less discoverable. So here we specify the mount path. That’s just some path in the container where I want to store all of my configuration details. Inside that folder, there’ll be a file for each of the ConfigMap keys. So inside the path and container to dir, I would have a database file and I would have a username file and I would have an API URL file. And my application could open that file, read the secret, and take appropriate action.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- image: nginx:alpine
name: myapp
# ... snip ...
volumeMounts:
- name: the-volume
mountPath: /path/in/container/to/dir
volumes:
- name: the-volume
configMap:
name: the-configmap # ConfigMap's name
ConfigMap as Files (One File per Key in Target Folder)
Stateful Resources #4: Secrets
So some of these configuration details, we may want to keep in secret. Rather than specifying them globally and storing them in plain text, we may want to use these encrypted. So let’s dig into secrets.

Secrets are stored encrypted at rest since Kubernetes 1.13. Arguably, that’s kind of late. Before this, it was stored as base 64 encoded. Oops. And because the secrets needed to be available on all hosts, because all hosts may run any pod, then if I compromise one of the hosts in my cluster, I could get access to all the secrets, just base 64 decode them, and get at them. That was solved in Kubernetes 1.13, and so now Kubernetes secrets are stored encrypted at rest. They are available on every host, so we do need to protect the host to ensure that those secrets are preserved, but they are encrypted at rest now. Alternatively, I may choose to put my secrets in a key vault like HashiCorp, and that’s a great solution as well.
So if I create these secrets, I can do that in a YAML file like I do here. This YAML file specifies the secret name is db-connection, and then here’s my list of secrets that I would like in this secret container. My database username is devuser. My database password is password, and I can store these in string data, just in plain text.
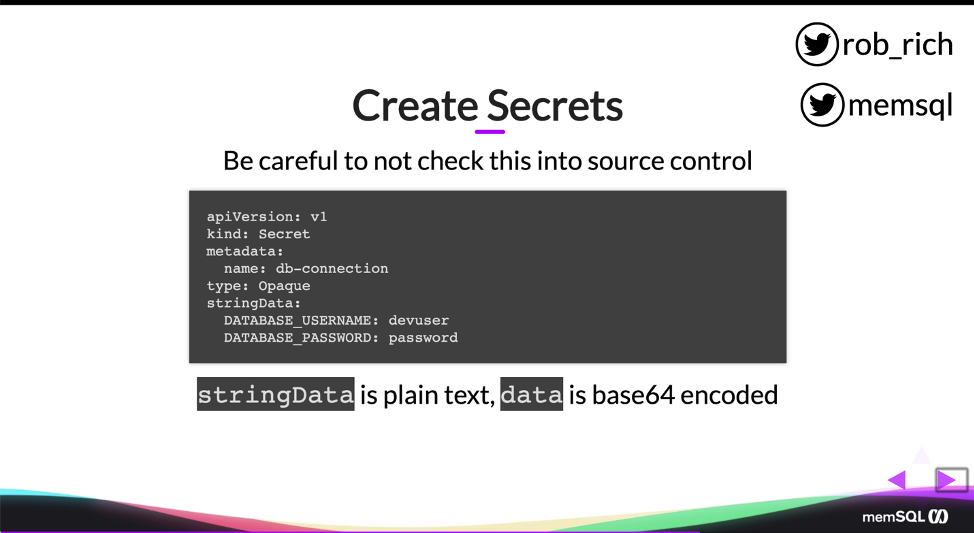
If I flip this string data with data, then these will be base 64 encoded. So base 64 encoding things is a smidge weird. They’re still not secret, but here’s that YAML definition. Now, I recommend not using this YAML definition, because it’s really easy to accidentally check this into source control – and once I’ve checked this into source control, then I’ve lost that secret data. I need to rotate my keys. I need to change my passwords. That data is now exposed.
apiVersion: v1
kind: Secret
metadata:
name: db-connection
type: Opaque
stringData:
DATABASE_USERNAME: devuser
DATABASE_PASSWORD: password
So rather than using a YAML file, I recommend using kubectl to create secrets. Now here, this is one long line. Each of these back ticks represents a continuation of that line. Here, as I’m creating the secret, I’m specifying the literal content for each thing. I can do this in a shell, where I can shortly thereafter kill my history, or I can pull that in from a file so I don’t even expose my passwords to the command line. But I can pull in those either as base 64 encoded content or, in this case, because I said from literal, I can pull that in from just plain text data.

So I say here in my DB-connection piece, I have two pieces of data I’d like to store in the secret. One is named username and its value is devuser and one is named password and its value is password. So we usually don’t change secrets a whole lot within our cluster. We just need them to be present, and so I find this command line or an API call to be a whole lot easier to maintain and to keep secure, rather than a YAML definition.
kubectl create secret generic db-connection \
--from-literal=username=devuser \
--from-literal=password='password'
So now, as I pull them into my application, we can do a similar kind of abstraction. Ops will own creating those secrets, perhaps rotating those secrets. And developers can then mount those either as environment variables or as files. In this case, I’m choosing to mount it as a file, so I have a volume mount.
Here’s my mount path. That’s the folder inside the container. I’m mounting it as read only as true because I really don’t want to change those secrets, not that I can, but I’m just making that explicit here. And then in my volume definition, previously we identified it from a ConfigMap, and then from a persistent volume claim. And here, instead of a persistent volume claim, we’re referencing it as a secret.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- image: nginx:alpine
name: myapp
# ... snip ...
volumeMounts:
- name: the-volume
mountPath: /path/in/container/to/dir
readOnly: true
volumes:
- name: the-volume
secret:
secretName: db-connection # The secret name
Secrets as Files (One File per Key in Target Connection)
So I have my secret name, DB-connection. And because I’ve specified that secret name, then in this directory I’ll have two files, a username file and a password file. Whenever my application needs to connect to the database, it can read those two files, grab those secrets, and continue on.
I can also choose to mount these as environment variables. Down here at the bottom, I’m still referencing that secret key ref as DB-connection, but I can also specify the key. In this case that is password, and it’s going to set an environment variable called DB-PASSWORD. Same thing with DB-USERNAME. I’ll set that value from the secret, and that’ll set that environment variable within my container. Now I can have one pod definition that is universal across all environments, and it can just assume that those secrets exist and pull in the applicable data as it starts up the pod.
So we’ve done some really, really cool things. We’ve got configuration details here, and we’ve got secrets so that we can store secret data. We can separate those details between developers and Operations to ensure that that content is preserved across environments, and secrets don’t leak into hands that don’t need them. We’ve got volumes where we can store our persistent data. And that may be enough with volumes and ConfigMaps and secrets to be able to get the majority of your application into Kubernetes.
Conclusion
This blog post, File Storage, Configuration, and Secrets, is the second in a series. The first, Kubernetes & State, appeared previously. The third, Kubernetes StatefulSets and Q&A, is coming up next. These are all part of a series covering Rob Richardson’s recent DZone webinar.
You can try SingleStore for free today. If you download the SingleStore database software, and want to manage it with Kubernetes, download the SingleStore Kubernetes Operator as well. Alternatively, use Singlestore Helios, our elastic managed database service in the cloud. We at SingleStore manage Singlestore Helios using our Kubernetes Operator, reducing complexity for you.







.png?width=24&disable=upscale&auto=webp)



