
SingleStore is steadily improving its high availability (HA) and disaster recovery (DR) features. The design of primary partitions and their corresponding secondary partitions on leaf nodes provided HA, while the replications configured on a remote cluster support DR. SingleStoreDB Self-Managed 7.0 marked a major milestone with the introduction of fast synchronous replication. This makes it much more practical to use high availability (HA) with SingleStore, as you can easily keep a live copy of your database contents in the cluster.
In this release, SingleStoreDB Self-Managed 7.1, we are adding a much-requested feature, fast disaster recovery failback (also known as simply DR failback). Our next release, SingleStoreDB Self-Managed 7.5, later in 2020, will add another much-requested feature, point-in-time restore.
In this blog post I will describe how DR failback has worked in the past and the important improvements in this new release, SingleStoreDB Self-Managed 7.1. We believe that you will find the new DR failback feature to be robust and highly useful.
Improvements in Replication for Failback
The point of DR is that you can quickly switch processing away from your primary cluster, if it fails or needs to be upgraded, and onto your secondary. In most scenarios, you will then want to fix your primary database, switch operations back to it, and return to using the copy that you had failed over to as your secondary: DR failback.
In previous releases of SingleStore, switching back to the original primary required you to halt operations, restore the original primary fully from the now-live backup site – a slow process – and only then resume operations. The length of the process, and resulting downtime, was a big problem, even preventing some sites from failing back.
Now, in SingleStoreDB Self-Managed 7.1, you can bring the primary up-to-date with the backup by restoring only the changes that have occurred since the original failure (the “disaster” in the term “disaster recovery”). This is usually much, much faster than a full restore, and greatly improves the recovery time objective (RTO), sharply reducing downtime and minimizing the risk of additional problems. With fast DR failback you can reverse a replication relationship in minutes, instead of hours or even days.
You may recognize that this improvement is also a significant step toward point-in-time restore (PITR), planned for the next major release of SingleStore.
Using the REPLICATE Statement for Fast Failback
The REPLICATE statement allows users to create a replica database from a primary database that resides in a different region. In previous releases of SingleStore, this replication was always a full replication. Just as it’s been with previous releases, the user can still pause and resume the replication as needed. But the full replication from scratch is not usually necessary, and takes a long time. We can do better.
SingleStoreDB Self-Managed 7.1 delivers a new capability to replicate only the differences between the secondary and the primary, instead of requiring full replication. This improves the customer’s recovery time objective (RTO) by a great deal. We will describe the commands here, and then walk you through the correct steps to use for a couple of real-life scenarios: restoring to the original database site after a failover, and handling upgrades to hardware and/or software, with the upgrades implemented one cluster at a time.
The following commands are used:
REPLICATE DATABASE db_name [WITH{SYNC | ASYNC} DURABILITY] FROM master_user[:'master_password']@master_host[:master_port][/master_db_name];
This is the version of replicate which SingleStore has had for a long time. In this version, you create a new replication relationship from the primary cluster/database to a secondary cluster/database. A new database, db_name, is created, and the system replicates master_db_name from scratch, in full, to new_db.
REPLICATE DATABASE db_name WITH FORCE DIFFERENTIAL FROM master_user[:'master_password']@master_host[:master_port][/master_db_name];
This is the new version of REPLICATE which is now available in SingleStoreDB Self-Managed 7.1. In this version, you create a new replication relationship from the primary cluster/database to a secondary cluster/database. (Note that the secondary database db_name should already exist for this command to work.) The system replicates master_db_name to db_name by replicating only the differences between the two.
Note: For simplicity, in the rest of this blog post, we use a database name in place of the complex user, password, and host string used in 1. and 2. above.
FLUSH TABLES WITH READ ONLY;
This is also a new feature in SingleStoreDB Self-Managed 7.1. This command marks databases read-only. Similar to its cousin, FLUSH TABLES WITH READ LOCK, the system allows read-only transactions to go through and flushes out already-started write transactions. Instead of queueing new WRITE transactions, the READ-ONLY command fails new WRITE transactions. This syntax is used to stop any new changes on the primary cluster so the secondary cluster has a chance to catch up before a DR failback.
UNLOCK TABLES;
This is an existing syntax for opening up the current database for reads and writes.
STOP REPLICATING db_name;
This is an existing syntax for stopping a DR replication relationship. Only after this command is run on a secondary cluster/db can it become a primary cluster/db to accept writes.
Scenario 1: The Original Primary Cluster Goes Down, then Comes Back Later
This is the classic DR failback scenario. The primary cluster goes down, and processing switches to the secondary. Then the primary cluster comes back up, and you want to switch processing from the secondary back to the primary, as quickly as possible. This is much quicker with the new WITH FORCE DIFFERENTIAL option for the REPLICATE command.
1. DB1 is serving the traffic and DB2 is replicating from DB1.
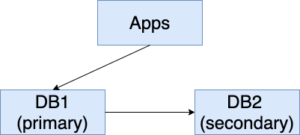
2. DB1 goes down (show in red background below). The user stops replication to DB2 and routes update and query traffic to DB2. New changes continue to be applied to DB2 and are stored as ChangeSet1 (CS1).
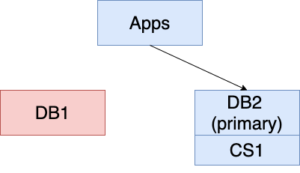
3. DB1 comes back online. It’s time to get the replication going from DB2 to DB1 so we are protected from the next disaster. With the new feature, DB1 only needs to catch up with DB2 for the changes made when DB1 was offline. This is much faster than replicating the whole DB2 to DB1. Now DB1 is replicating from DB1, and the roles of primary and secondary are reversed. Unfortunately, the world does not stop during the catching up period. More changes (ChangeSet2) are applied to DB2.
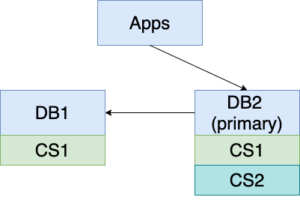
4. If you don’t need to make DB1 the primary database again, you are set. Life goes on. DB1 will catch up with DB2 again as time goes by. However, if DB1 is better equipped, with more memory, better CPU, more disk space, etc.; is closer to where most updates and/or queries originate; or is otherwise preferable, follow the steps below to make DB1 the primary database again.
5. Start by “locking” DB2 as READ-ONLY. You can achieve this with the syntax “FLUSH TABLES WITH READ ONLY”. (Or, you can pause all writes from the application(s), if that’s possible in your environment, and make sure existing write transactions are given the opportunity to complete.) Soon DB1 will catch up with DB2. The time to catch up with ChangeSet2 should be much shorter than the time to catch up with ChangeSet1.
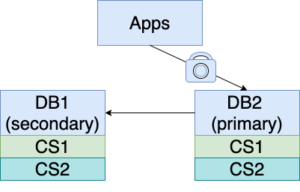
6. Now we can have DB1 serving the traffic, since it has the same content as DB2. Stop replicating from DB2 to DB1 and direct apps to write to DB1. New changes (ChangeSet3) are applied to the one-time, and now current, primary, DB1.
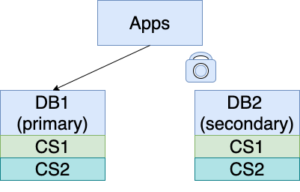
7. Let’s quickly unlock DB2 with the syntax “UNLOCK TABLES”. Then we can set up replication with the new syntax, “REPLICATE DB2 WITH FORCE DIFFERENTIAL FROM DB1”. DB2 is configured to replicate from DB1 now, starting from the beginning position where it was different from DB1. In other words, DB2 starts to catch up with CS3 and whatever future changes are made to DB1.
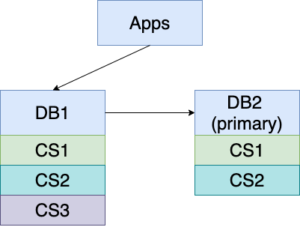
Scenario 2: I Want to Upgrade my Network, One Cluster at a Time
In this scenario, you need to upgrade your servers or networking connections, without taking the system down. These may be software or hardware upgrades/fixes. For example, you need to upgrade the OS on your servers to a new version, or you want to add more main memory and new SSDs to your machines. You want to rotate through clusters in my network to perform the upgrade. This section will describe how to perform this kind of rolling upgrade for SingleStore clusters.
Since you need to rotate through your entire network to perform the upgrade, you just need to look at a pair of DR clusters at a time. The goal is to upgrade one node, then the other, with minimum downtime and no data loss.
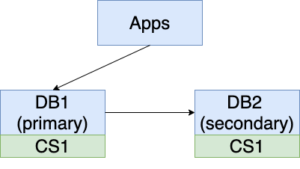
1. Before the upgrade starts, DB1 is serving the traffic, and DB2 is replicating from DB1.
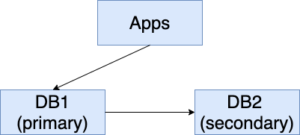
2. While DB1 is serving the traffic, bring down DB2 for the necessary upgrade (show in red background below). New changes (ChangeSet1) are made to DB1.
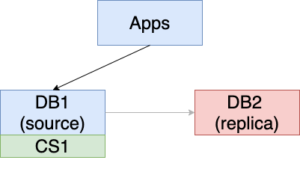
3. Power up DB2 after its upgrade is done.Since DB2 still remembers that it is replicating from DB1, users do not need to do anything. The replication is starting from where DB2 went offline. ChangeSet1 is replicated to DB2.
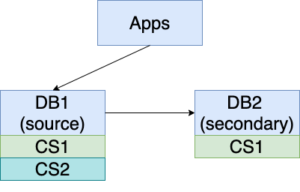
4. A small delta of changes, ChangeSet2, may exist between DB1 and DB2 at this time.
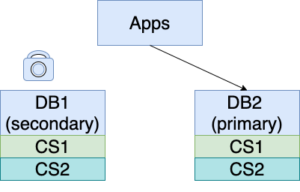
5. Lock DB1 for READ ONLY, then wait until DB2 catches up with DB1. This wait should be rather short.

6. Stop the replication from DB1 to DB2. Route the traffic from business applications to DB2.
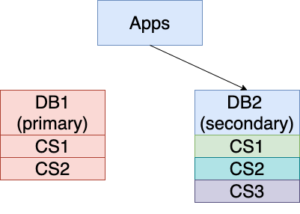
7. Unlock tables on DB1, bring it down (show in red background below) and upgrade it. More changes (CS3) are made to DB2 during this time.
8. Power up DB1 and start to replicate from DB2 using the new syntax “REPLICATE <DB1> WITH FORCE DIFFERENTIAL FROM <DB2>”. This statement will only replicate the missing parts (i.e., ChangeSet3) in DB1 from DB2.
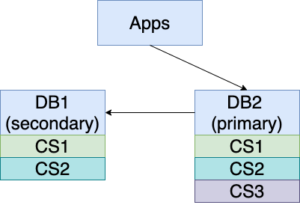
9. DB1 catches up with DB2 when the statement “REPLICATE … WITH FORCE DIFFERENTIAL …” is completed and returned for the missing updates (ChangeSet3) CS3. However, more changes may come in during this time.
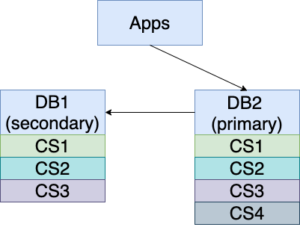
10. DB2 is the primary serving the traffic now. If we prefer to restore DB1 to its former status as the primary, then we need to perform steps similar to steps 5-7 of Scenario 1 to swap the primary and the secondary.
Conclusion
This blog has demonstrated the new replication options in SingleStoreDB Self-Managed 7.1 that replicate only the missing log records from the primary database. This feature saves a lot of time when you need to catch up a secondary cluster/database from a primary cluster/database. It can allow you to reverse a replication relationship in minutes, instead of hours or even days. You may now be able to accommodate server and networking failures, and needed upgrades, with minimal or no noticeable downtime. For more information, contact SingleStore, or you can try SingleStore for free.
References to SingleStore documentation:
Replicate Database
Stop Replicating Database
Flush Tables
Unlock Tables








