

Universal Storage, first introduced in the SingleStoreDB Self-Managed 7.0 release, advances quickly in SingleStoreDB Self-Managed 7.1. Universal Storage allows SingleStore to support the world’s largest workloads – as well as many smaller workloads – with extremely high performance and excellent price-performance. In this release, new Universal Storage features make it even easier to support blended analytical and transactional workloads that achieve near-rowstore performance for selective queries, but at columnstore costs.
This is the second in a series of four articles that describe SingleStore's unique, patented Universal Storage feature. Read Part 1, Part 3 and Part 4 in the series to learn the whole story.
SingleStore Universal Storage appeared in SingleStoreDB Self-Managed 7.0, with notable improvements in performance and total cost of ownership (TCO) for both rowstore and columnstore workloads. In SingleStoreDB Self-Managed 7.1, we make further improvements to rowstore-like aspects of performance on the columnstore side. Support for high performance hybrid transactional and analytical processing (HTAP) workloads is becoming increasingly important in the database industry. Industry analysts refer to this kind of workload as “translytical,” “operational analytics,” “augmented transactions,” or “analytic/augmented transaction processing (ATP).” We’ll use the term HTAP here. SingleStore leads the industry for HTAP performance, outdistancing legacy products by a factor of ten or more in price-performance. But we’re not satisfied. We want to support the world’s largest workloads cost-effectively — more cost-effectively than anyone, even SingleStore, has achieved to date. SingleStore shipped the first installment of our groundbreaking Universal Storage technology in SingleStoreDB Self-Managed 7.0 last December. The purpose of Universal Storage is to dramatically reduce total cost of ownership (TCO) for HTAP workloads. Moreover, Universal Storage technology can allow much larger online transaction processing (OLTP) workloads to be run on SingleStore, with much lower TCO, than ever before. In the SingleStoreDB Self-Managed 7.1 release, we’ve improved Universal Storage to handle more use cases more efficiently, and make the developer’s job easier when creating both HTAP and OLTP applications.
Universal Storage Introduced in SingleStoreDB Self-Managed 7.0
Beginning with its introduction in SingleStoreDB Self-Managed 7.0 [SS19], Universal Storage has included several capabilities which improve TCO and performance for HTAP and OLTP:
- Hash indexes on columnstores [CS19], to allow fast location of a row in a columnstore, given its key value.
- Sub-segment access, which allows quick retrieval of a row from a columnstore – very quickly, in single-digit milliseconds – once its position is known.
- Row-level locking for columnstores, which allows many concurrent updates of multiple rows in a columnstore to proceed, without requiring transactions to wait.
- SPARSE compression for rowstores [RS19], which can cut RAM usage by half or more for wide tables in rowstore that have lots of NULL values (ie, many of the rowstore tables we see at SingleStore).
The first three changes make it possible to accomplish many tasks in columnstore that were formerly only practical in rowstore. This allows customers to take advantage of the high degree of compression in columnstore, and the costs advantages of using this disk-based table type, to achieve previously impossible TCO for these workloads.
Universal Storage Advances in SingleStoreDB Self-Managed 7.1
The advent of sparse compression in rowstores preserves the speed advantages of rowstore tables, based as they are in memory, while cutting costs by roughly 50%. Also, together, these changes reduce the need to use mixed rowstore/columnstore implementations, in an effort to find price/performance sweet spots. (At the expense of added complexity.) The desired sweet spot can now often be found either entirely in rowstore, or entirely in columnstore. And now, as part of SingleStoreDB Self-Managed 7.1, we are making further improvements to Universal Storage on the columnstore side. These changes speed up more columnstore operations, enhancing the degree to which you can enjoy the large price advantages of columnstore (5-10x compression, and the use of disk rather than memory for main storage), along with the existing performance advantages of columnstore (fast scans, for example), and new performance improvements for specific operations in columnstore that bring it ever closer to rowstore-like execution times.
The Next Installment of Universal Storage
We’ve worked with many of our customers to understand how they’re using our product for HTAP. Something they’ve consistently asked for is enhancements to the ability to enforce uniqueness constraints automatically. They can already do this with SingleStore rowstores, which have supported unique key validation for years. In addition, in SingleStoreDB Self-Managed 7.0, with hash indexes and subsegment access on columnstores, you could use multiple statements to check for an existing key, then insert a new record with that key if the key was not found. But clearly, it made sense to support standard SQL UNIQUE constraints or keys on a columnstore table. That would make the developer’s job easier.
Unique Hash Keys
So, in SingleStoreDB Self-Managed 7.1, we will now support single-column unique keys on columnstores, via an extension of our existing hash indexes. Here’s a simple example of how it works. First, we create a table, t, with a unique key, column a.
create table t(
a int,
b decimal(18,5),
shard(a),
unique key(a) using hash,
key(a) using clustered columnstore);
The clause, unique key(a) using hash, causes SingleStore to validate inserted and updated rows, making sure no duplicates are added to column a. You must shard the table on the unique key so the uniqueness test can be done locally on a single leaf node [MSL19]. Now, we insert two rows with different keys:
memsql> insert t values(1, 10.0);
Query OK, 1 row affected (0.11 sec)
memsql> insert t values(2, 20.0);
Query OK, 1 row affected (0.01 sec)
Finally, we try to insert a duplicate key, 2:
memsql> insert t values(2, 30.0);
ERROR 1062 (23000): Leaf Error (127.0.0.1:3308): Duplicate entry '2' for key 'a_2'
This fails because of the duplicate key.
Performance of Uniqueness Checking
To analyze the performance level of the hash index uniqueness checking, I inserted 16 million rows in the table, t, used above. Then I ran this statement to insert 1000 new rows:
insert into t
select a+(select max(a) from t), 1000000*rand()
from t
limit 1000;
Running this command using the Profile option in SingleStore Studio (Profile) shows this took 39 milliseconds, which is a fraction of a millisecond per row. Profile shows that the following command to insert one row takes less than one millisecond:
insert into t
select a+(select max(a) from t), 1000000*rand()
from t
limit 1;
Both of these INSERT statements are showing OLTP-level performance for uniqueness checking.
Highly-Selective Joins on Columnstores
SingleStoreDB Self-Managed 7.0 introduced support for columnstore hash indexes, broadening the support for OLTP-type queries on columnstores. However, a common join pattern in OLTP is to have a very selective filter on one table, which produces one or a few rows from the source table, and then join those rows with another table. Databases for OLTP normally use a nested-loop join for this. For each and every row from the outer table, an index seek will be done on the inner table. SingleStoreDB Self-Managed 7.1 supports this kind of highly selective join using an adaptive hash join algorithm, which first does a hash build for the table with the highly-selective filter. Then, if only a few rows are in the hash table, it switches to perform a nested-loop join that seeks into the larger table (on the probe side) via the index on the join column of the table on the probe side. If, on the other hand, the hash build side produces a lot of rows, then a normal hash join will be done. Here’s an example of a simple schema and query that can take advantage of this new strategy for selective joins.
create table orders(
oid int,
d datetime,
key(d) using clustered columnstore,
shard(oid),
key(oid) using hash);
create table lineitems(
id int,
oid int,
item int,
key(oid) using clustered columnstore,
shard(oid),
key(oid) using hash);
Now, add some sample data to orders:
insert into orders values(1, now());
-- repeat the statement below until orders has 33.5 million rows
insert into orders
select oid+(select max(oid) from orders), now()
from orders;
Add 67.1 million rows of data to lineitems, such that each line item belongs to an order, and each order has exactly two line items.
insert into lineitems select oid, oid, 1 from orders;
insert into lineitems select oid + 1000*1000*1000, oid, 2 from orders;
Find a selective datetime value for d to search on:
select d, count(*)
from orders
group by d;
The result shows that a couple of datetime values only appear in one row in orders, in my test. One of these is 2020-03-30 16:47:05. The following query uses this date to produce a join result with exactly two rows:
select *
from orders o join lineitems l on o.oid = l.oid
where o.d = "2020-03-30 16:47:05";
It filters on o.d to find a single row of orders, then joins to lineitems via the hash index on lineitems.oid, using the new selective-join algorithm. The profiler in SingleStore Studio shows that this query runs in only one millisecond. That’s OLTP-level speed, with all the TCO advantages of columnstore. The relevant part of the profile plan shape is shown in Figure 1. The query plan works by first seeking into the orders table to get one row, in the ColumnStoreScan operator on the right. The hash build above then builds a hash table with one row in it. Recognizing that the build side is small, the HashJoin operator dynamically switches to a nested-loop join strategy. It seeks the columnstore hash index on lineitems, on the left, to find matching rows. Then it completes the join and outputs two rows.
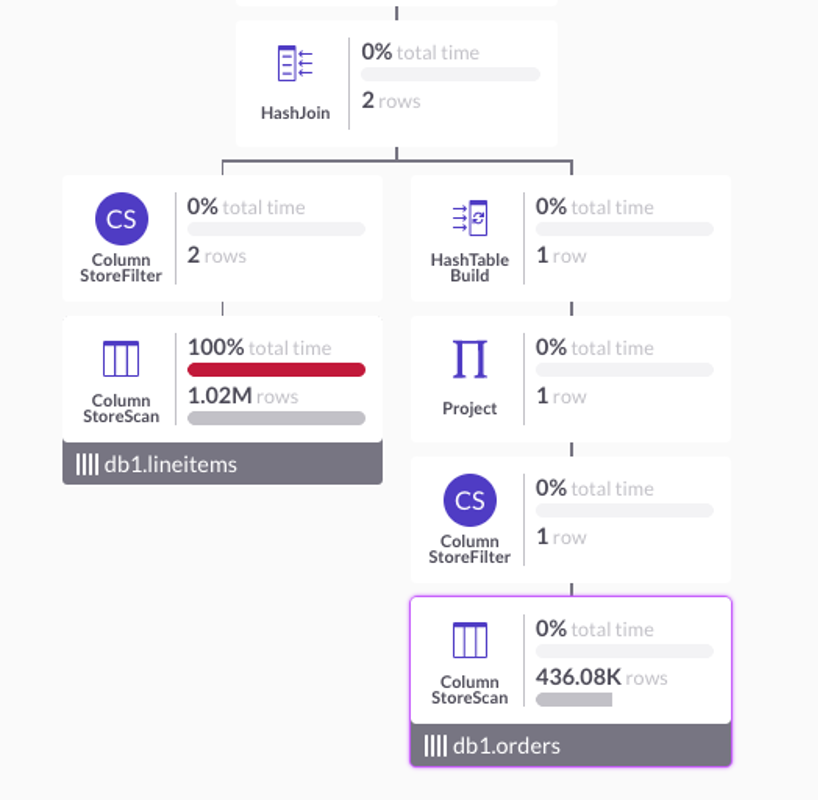
Figure 1. Sub-plan of PROFILE PLAN for selective join of orders and lineitems. To see if a plan may be able to do a join via a hash index, look into the JSON profile plan. If the strategy is available in your plan, you will see join index in descriptions of columnstore filter operators. For example:
"executor":"ColumnStoreFilter",
"keyId":4294968023,
"condition":[
"o.oid = l.oid bloom AND l.oid = o.oid **join index**"
],
Or, click on the ColumnStoreFilter operator in Studio and you may see a condition that mentions join index, like this, in the properties pane on the right:
**CONDITION**
o.oid = l.oid bloom AND l.oid = o.oid **join index**
Benefits Compared to No Indexes
I ran the same query again without the hash indexes on orders and lineitems, and the query took 7 milliseconds, instead of 1 millisecond. The most surprising thing about this for me was that the join performance was as good as it was – 7ms, that is – even without the hash indexes. That’s an indication of how good our other join performance features are, like segment elimination [OTD19], operations on encoded data [OED19], Bloom filters, and sub-segment access. Nevertheless, there is a dramatic improvement, 7x, when the hash indexes are added. This test was run on a Singlestore Helios test cluster with only a single half-height leaf node. Of course, your results for selective join performance will vary depending on the type of hardware, cluster size, schema, and data size.
Conclusion
Universal Storage is a major, multi-release effort at SingleStore to dramatically improve TCO for both HTAP and OLTP. Our columnstore table type now has all the features needed to support HTAP and OLTP for many use cases. We’re continuing to advance Universal Storage. For example, multi-column unique keys on columnstores, and UPSERT support for columnstores, are in our future. Stay tuned for continued improvements in this area in our releases after 7.1.
Read Part 1, Part 3 and Part 4 in the series to learn the whole story behind SingleStore's patented Universal Storage feature.
References
[CS19] SingleStore Columnstore, SingleStore Concepts, https://archived.docs.singlestore.com/v7.0/concepts/columnstore/, 2019. [MSL19] Leaf, SingleStore Concepts, https://archived.docs.singlestore.com/v7.0/concepts/leaf/, 2019. [OED19] Understanding Operations on Encoded Data, SingleStore Concepts, https://archived.docs.singlestore.com/v7.0/concepts/understanding-ops-on-encoded-data/, 2019. [OLTP17] What is OLTP? https://database.guide/what-is-oltp/, 2017. [OTD19] Optimizing Table Data Structures, SingleStore Documentation, https://archived.docs.singlestore.com/v7.0/guides/development/development/optimizing-table-data-structures/, 2019. [RS19] Rowstore, SingleStore Concepts, https://archived.docs.singlestore.com/v7.0/concepts/rowstore/, 2019. [SS19] SingleStore Universal Storage – And Then There Was One, https://www.singlestore.com/blog/memsql-Universal Storage-then-there-was-one/, September, 2019.












