
Today we will talk about improving the speed of queries in MySQL. To do so, we’ll use a demo database that provides the same MySQL main page with the following structure:
ENTITY RELATIONSHIP DIAGRAM

The airportdb database is a large data set intended for use with MySQL DB systems. The database is approximately 2GB in size and consists of 14 tables containing a total of 55,983,205 records.
Table 1 airportdb Tables:
| Table Name | Rows |
|---|---|
| booking | 50831531 |
| flight | 416429 |
| flight_log | 0 |
| airport | 9939 |
| airport_reachable | 0 |
| airport_geo | 9854 |
| airline | 113 |
| flightschedule | 9851 |
| airplane | 5583 |
| airplane_type | 342 |
| employee | 1000 |
| passenger | 36346 |
| passengerdetails | 37785 |
| weatherdata | 4626432 |
You can download it here:
https://downloads.mysql.com/docs/airport-db.zip
Installation: https://dev.mysql.com/doc/airportdb/en/airportdb-installation-oci.html
Diagnosis of the consultation
You must execute the EXPLAIN command on the query that you want to optimize. This command helps us validate how the database manager is processing the query, and illuminates where the bottlenecks are — thus being able to improve our queries.
What we are going to focus on as the result of the use of EXPLAIN is the following:
- The order of the rows. The order in which the database consults the tables.
- The key column. Indicates the index that is being used to access that specific table (if any)
- The type column. Indicates the type of access to the table. The possible values, from best to worst, are:
- system
- const
- eq_ref
- ref
- Fulltext
- ref_or_null
- index_merge
- unique_subquery
- index_subquery
- range
- index
- ALL
Optimizations
Avoid FULL SCANS
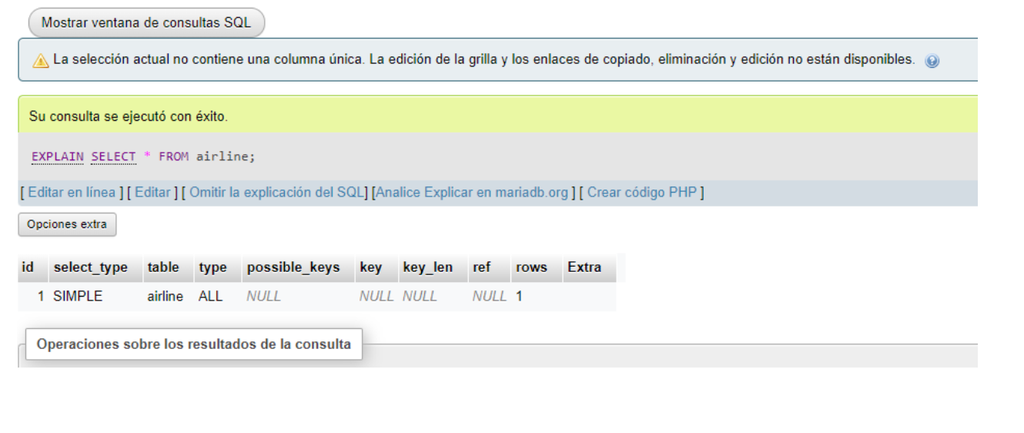
The EXPLAIN command can tell us if the access to the tables is typed ALL. This tells us the process that the database manager is executing is to read all the records of the said table, without making any type of filter. The consultation must be analyzed based on needs and analysis, and validates if possible to improve the consultation by making the pertinent changes.
For this, you could make use of indexes directly from the table created based on its primary keys, or evaluate the possibility of creating said indexes to tell the handler to search based on the created indexes.
SQL: EXPLAIN SELEC * FROM airline;.
Indexes
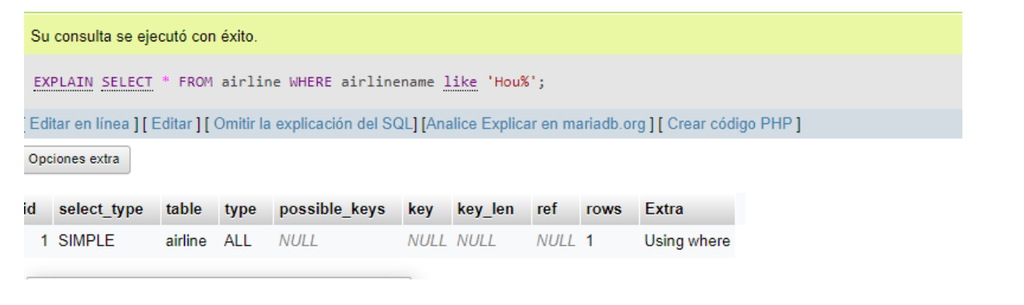
The indexes are a way to carry out the queries faster since we indicate to the handler where to carry out the search. If we want to search for the definition of "Airport" and search for words that start with "Aero", we will be doing the right thing.
But unlike this way of using the indices and searching for words that end with "port", we will make the handler of the database complete the search of all records that we have in the tables that are making the query. This would be the logic or the easiest explanation to understand for a search LIKE 'prefix_index%' is indexed and another LIKE '%suffix_index' that is not.
SQL: EXPLAIN SELECT * FROM airline where airlinename like 'Hou%';.
Group by and Order by
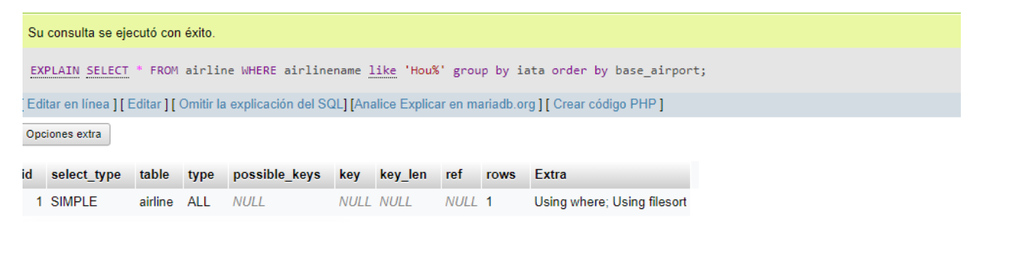
The use of group by and order by are also extremely important when we want to optimize a search, since it allows us to do the following: Grouping the records that the query will bring us will make the query return grouped data, so we will have less record than the base must process. And, the ‘order by’ gives us the possibility of ordering it to be able to bring the data in the way we require for our processes.
SQL: EXPLAIN SELECT * FROM airline where airlinename like 'Hou%' group by iata order by base_airport;.
Derived Tables and Subqueries
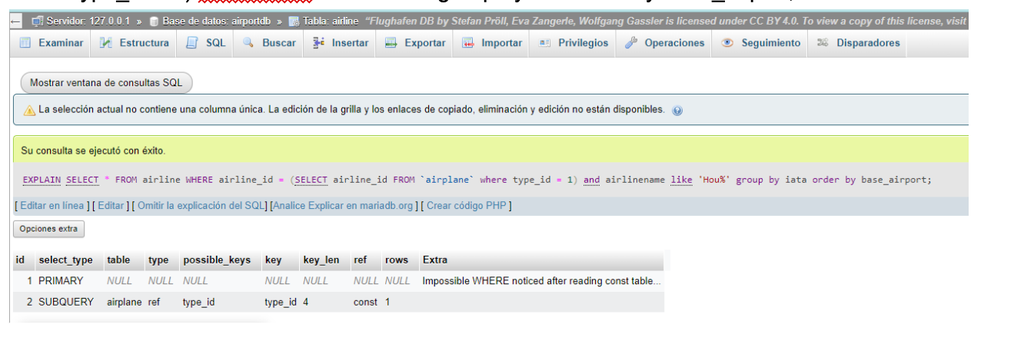
A derived table is a subquery that is executed within the FROM of the parent query, and a subquery is a Select statement within another Select statement. Both are handled through the database handler in a different way: the derived table performs a single query to the database and stores the information in a temporary table in memory, and that table is accessed once for each record of the parent query. The subquery is executed together with the parent query, and is reviewed for each record that the parent query has.
SQL: EXPLAIN SELECT * FROM airline where airline_id = (select airline_id from airplane where type_id = 1) airlinename like 'Hou%' group by iata order by base_airport;.
Summary
So we have the following: to optimize queries in a database, it is important to use the EXPLAIN command, which supports us in validating how the database is executing the query. To prevent our query from doing FULL SCAN for this we use the INDEXES. Additionally it is important to use the group by and order by in a way that our query brings fewer records for processing, and also takes into consideration that it is more optimal to use derived tables than subqueries — since the way the database handler processes it is faster with derived tables than with subqueries.
SingleStoreDB
SingleStoreDB is a real-time, distributed SQL database that unifies transactions and analytics in a single engine to drive low-latency access to large datasets, simplifying the development of fast, modern enterprise applications.
Built for developers and architects, SingleStoreDB delivers 10-100 millisecond performance on complex queries — all while ensuring your business can effortlessly scale.
SingleStoreDB is MySQL wire compatible and offers the familiar syntax of SQL, but is based on modern underlying technology that allows infinitely higher speed and scale versus MySQL. This one of the many reasons that SingleStore is the #1 top-rated relational database on TrustRadius.
For more information on how SingleStore is related and can turbocharge your MySQL, visit our comparisons page: https://www.singlestore.com/comparisons/mysql/.
Resources:




-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)



