

This is the third blog post derived from the recent DZone webinar given by Rob Richardson, technical evangelist at SingleStore. (From the link, you can easily download the slides and stream the webinar.) Kubernetes was originally developed to manage containers running stateless workloads, such as computation-intensive processing tasks and web servers. It was then extended to allow you to manage stateful workloads, such as data tables and e-commerce sessions, but doing so is not easy. Rob is one of the relatively few people who have figured out how to do this well.
The webinar was well-attended, with a solid Q&A session at the end. There’s so much going on that we’ve split the webinar into three blog posts: The first blog post, Kubernetes and State; the second blog post, Kubernetes File Storage, Configuration, and Secrets; and this blog post, the third and final one, which covers Kubernetes StatefulSets, and the Q&A at the end of the webinar. You can read through all three for education – or use them as a step-by-step road map for actual implementation. You can also see Rob’s Kubernetes 101 blog post for an introduction to Kubernetes.
As Rob mentions during his talk, SingleStore database software is well-suited for containerized software development, managed by Kubernetes. SingleStore has developed a Kubernetes Operator, which helps you use SingleStore within a containerized environment managed by Kubernetes. Alternatively, if you want to use a Kubernetes-controlled, elastic database in the cloud, without having to set up and maintain it yourself, consider Singlestore Helios. Singlestore Helios is available on AWS, Google Cloud Platform, and is coming soon on Microsoft Azure.
Following is a rough transcript of the final part of the talk, plus the Q&A at the end, illustrated by slides from the accompanying presentation. This third blog post describes Kubernetes StatefulSets, plus a range of topics from the Q&A.
Kubernetes StatefulSets
At the end of the previous section, we had taken care of configuration details and secrets. We had discussed a couple of ways of separating those details between developers and Operations, so as to keep things orderly. We also created volumes in which to store our persistent data.
Now let’s take on StatefulSets and kind of level up and see if we can get even more of our application into place. StatefulSets allow us to create mechanisms where we have machines that need to talk to each other and have predictable names. Perhaps hosting a cluster, such as a database cluster.
So this is a bundle of machines. It creates pods with predictable names. And with that, we can then communicate between containers. It’s easy if I’m creating a cluster of machines, or if I’m trying to connect to a cluster of machines, where I have to list the machines. Now, if the pods are coming and going and each one gets a random name every time, how does my application keep track of those, and how does it go ask the system how to connect?
We avoid all of that by creating a StatefulSet. We can create a StatefulSet that will have a known number of machines – by which, I mean containers – and each of them will have a known name. And if one of them goes down, then a new one will come back with that exact same name, and the same data, and now we don’t need to keep track of the list of machines/containers.

We can think of a StatefulSet as a deployment with predictable names. A deployment is that mechanism where I can say, “I would like three copies of it,” and so it’ll always ensure that three pods are running. In this case, the StatefulSet is that deployment with three pods running, but we know what those machine names will be. They’ll be zero, one, and two. Kubernetes will ensure that two doesn’t start up until one is running as well.
So, StatefulSet use cases. We might want to spin up a Kafka cluster or an ELK stack cluster or a database cluster, such as my SingleStore. SingleStore uses lots of machines to distribute our data across commodity hardware so that we don’t need one big, beefy machine to be able to store our database. And with that distributed nature of SingleStore, we do need to have lots of machines and they need to be able to coordinate together. So with a StatefulSet, we can put our SingleStore machines into our Kubernetes cluster and ensure all of them are playing well together.
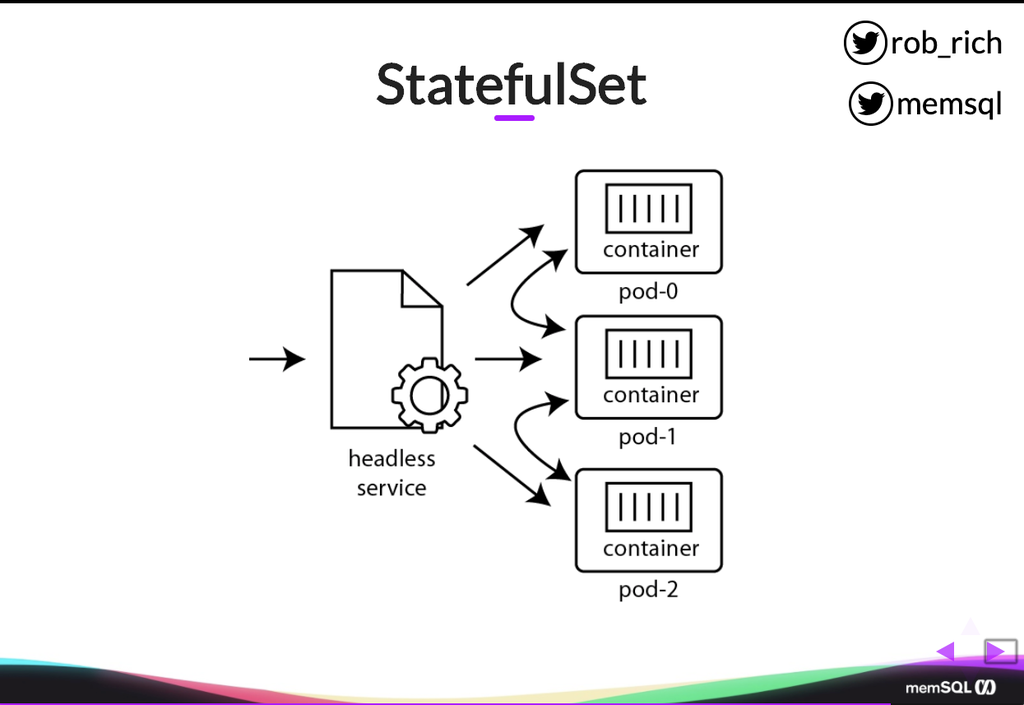
So here’s that mechanism of a StatefulSet. We have each pod with a predictable name. So here’s pod-0. Here’s pod-1. Here’s pod-2. Each one will have a container running in it and then we have this headless service that allows for communication between pods. If a container wants to reach out to a particular pod, it can through this headless service, given its known name. And then our inbound traffic can reach in through this headless service, or we could create another service that is specific for communicating to some or all of these StatefulSet containers.
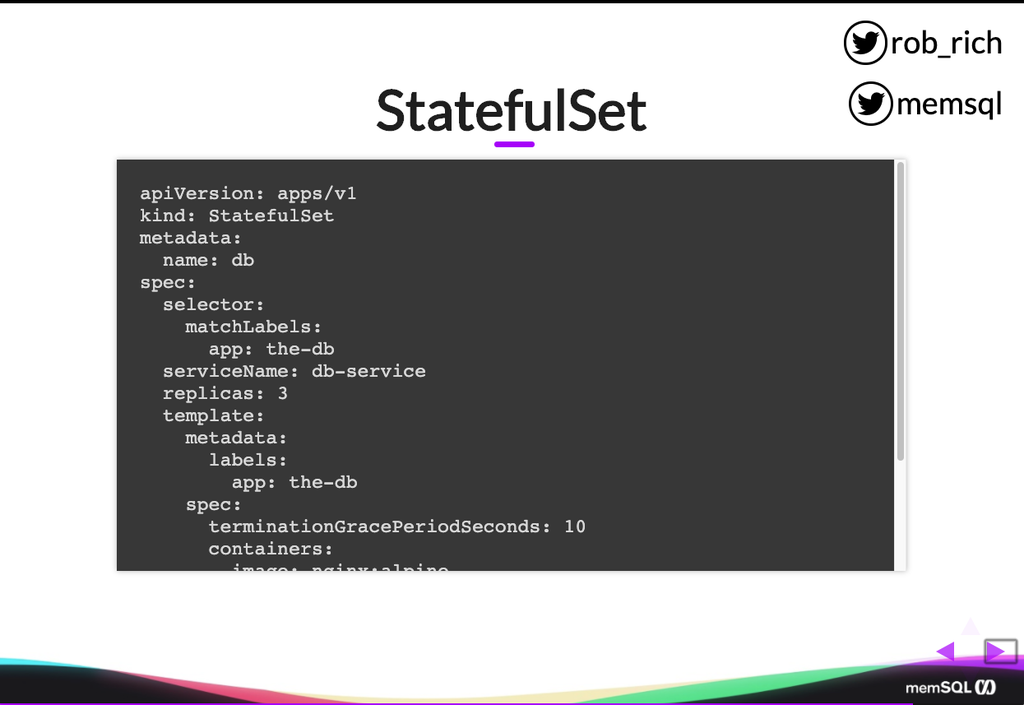
So here’s a YAML file that defines that StatefulSet. You’ll notice it looks not that unlike a template from a deployment definition. We have the number of replicas. We have a template that describes how we build our thing. We’ll give it a service name. That’s that headless service that we must create. Our match labels. All of this kind of mirrors a deployment. But in this case, as we specify our template, our template matches the same mechanism as well. The only real difference is that we’ve identified it as a StatefulSet, and we’re listing our headless service that we’re using as well.
So here’s that headless service, and what makes it headless is this cluster IP of none. The cluster IP of none says it’s not going to create a cluster IP. I can only connect to it by name. And the cool part then is that if I’m connecting to it to connect to any of the machines, I can do it much like I would a normal service. Let me just curl that service name. But if I want to speak to a particular machine, then I can talk to that machine. So in this case, perhaps the db-0 needs to talk to the db-1. So it’ll just connect to the db-1.db-service, and now it can communicate directly with that second pod through this headless service.
Most apps will connect to it this way, just as db-service, and at that point it’ll just round robin across all of them. So as I have my SingleStore database set up, I’ll create this headless service to connect to my aggregator nodes, and just call that the aggregator service. But then, as the aggregators need to connect to each other, or as the aggregators need to connect to the leaf nodes, then they can do that by referencing them by name here.

Now That We’ve Achieved Statefulness…
So here’s that stateful Kubernetes service. Now, in our application we had a whole lot more pieces. We had a certificate and a domain name. We have connection details off to a database cluster. We have paths to our file storage. We have storage details, things that need to stay more persistent. And as we look through each of these pieces, we can see that not only do we have all of our normal stateless services, our containers, our pods, our services, but we also have all of the stateful pieces.
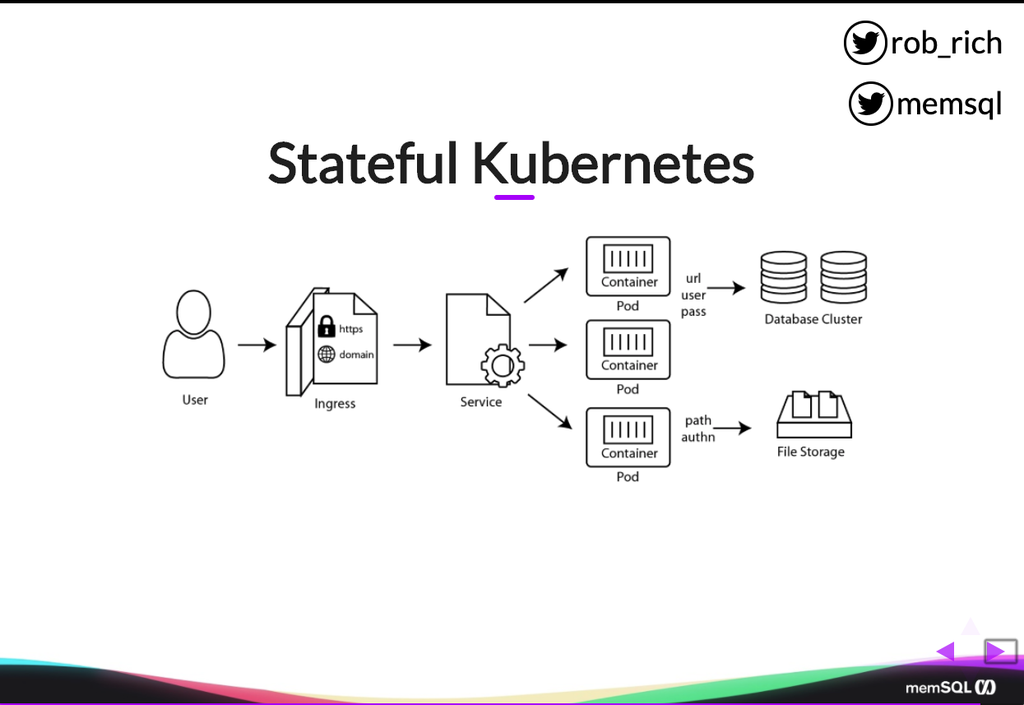
Here’s a ConfigMap that specifies the domain name. Here is a secret that is the certificate. Here’s a ConfigMap or a secret that specifies the connection details to get to our database cluster. We have persistent volumes and persistent volume claims that allow us to get to durable storage elsewhere. And we have a StatefulSet that allows us to define a database cluster, or another cluster that takes multiple machines of known machine names. All of these stateful pieces now allow us to move the rest of our application into our Kubernetes cluster and maintain business continuity across the complexities that become our application. Volumes, Secrets, ConfigMaps, and StatefulSets are that next level that get us to the “day two” experience in Kubernetes. (For the “day one” experience – an introduction to Kubernetes – see Rob’s Kubernetes 101 blog post. Ed.)
Q&A
Q: How do I version my container secrets?
A: We looked at a YAML definition that defined those secrets and I talked about how it’s scary to check those in the source control. Perhaps we want to create a separate repository that is known to be private, and check in those YAML files into the separate repository that keeps it secret. That’s one way to version our secrets. Another way is to keep the secrets elsewhere, perhaps in a vault like a HashiCorp vault or Azure key vault, and that will allow you to version the secrets as well.
Q: How do I get https certificates into the web server containers?
A: Let’s look at the stateful Kubernetes diagram again (above) and see how we did that. Now, if we were to terminate https here at the pods, we could map in a secret or a ConfigMap to get that content into each pod. I would really recommend a secret because it is a certificate. And so I could just map that in as one of the secrets, exposed either as environment variable or as a file. In this case, the certificate may get big. So perhaps mapping it in as a file might make more sense.
As we step back, probably we don’t want to terminate SSL here at the container. Probably, we want to terminate SSL at the firewall, at the gateway up here. And the cool part then is I don’t need to get the certificate into my container. I can get my certificate here into my Ingress controller, and I have a single ConfigMap or a single secret that points it to the Ingress controller, and the Ingress controller can terminate SSL. At that point, all of the traffic downstream is just http between pods, and that might be an easier way to solve that problem.
If I do need certificates in this communication between Ingress and service, between service and pods, then that’s where I would reach for something like Istio or Linkerd, a service mesh. And that service mesh can ensure that all of the communication within the cluster is encrypted separately. I still terminate SSL at the ingress controller, the public SSL. Then Istio picks up and will encrypt traffic between the Ingress controller and services, or between services and the pods, using sidecar proxies.
Q: Why would I choose containers over virtual machines like EC2?
A: What makes containers really, really powerful is that they act as ephemeral, isomorphic hardware. We can spin one up at the drop of the hat, and it only contains the differences between what I need to run my application and the host machine that is running that container. So containers end up being a lot lighter-weight, a lot smaller. Where a virtual machine may be tens or hundreds of gigs, a container is usually tens or hundreds of megs. And that shrinkage in storage cost also translates into run-time efficiency as well.
I can get a whole lot more containers running in a given cluster than I can virtual machines. Using containers does mean that I need to think more about how I deploy my application. I need to split it into pieces. I need to define my services that will load balance across my containers. I need to terminate my SSL at the ingress point, perhaps, or create other abstractions to be able to handle these containers, but it is a whole lot lighter-weight mechanism to run. And because it’s much lighter-weight, then you’ll get operational efficiencies straight out of the gate. Ultimately, if you can move your application into containers, you will probably make it faster and easier to run straight away.
Q: How do I create a deployment or a StatefulSet with one pod on each node in a cluster?
A: So I want to create a StatefulSet much like I would create this StatefulSet for a database cluster – but, instead of having a known number of pods, I want to have one on each machine in my cluster. Maybe I want to do monitoring or shipping logs into Prometheus or something like that. That is called a DaemonSet, rather than a StatefulSet, and we can think of it exactly like a deployment.
A DaemonSet is a deployment with one pod on each machine in the cluster. So ultimately, I’m not specifying the number of replicas. I’m just specifying hey, go do it. And it’ll put one pod on each node in my cluster.
Q: How do I get SingleStore running on Kubernetes?
A: We talked about how to create StatefulSets. SingleStore has three different types of machines. We have the leaf nodes that actually store the data. We have aggregators where clients connect to that and that will push the data across into all the leaf nodes that need to participate in that. And then we have a master aggregator, whose job it is to control the health of the cluster.
So ultimately, as we get SingleStore into Kubernetes, we’ll need three different StatefulSets. One for all of the leaf nodes, one for the aggregator nodes, and one for the master aggregator. But you don’t need to build up that complexity. If you want to, you can use the Kubernetes Operator created by SingleStore. It includes a custom resource definition where I can specify here’s how many aggregator nodes I want; here’s how many leaf nodes I want. And the operator will take care of deploying all of the pods, keeping them running, and deploying all the StatefulSets to ensure that I have durability and availability. I can also specify across availability zones if I would like. And ultimately, that operator then hides all of that complexity from us, removes all of the need to understand all that complexity. So I can just deploy the operator and fire it up and it just works.
If you want to take it to the next level of using Kubernetes and avoid all of that complexity, then Singlestore Helios is actually running on top of the Kubernetes operator. It is exactly that same database engine, but with Singlestore Helios, you just sign up. You provision an on-demand database and it’ll give you a database connection. At that point, enter those database connection details in your application, and you have database-on-demand.
The really cool thing is that all of the database backup and always-on details and all of the border security pieces that you might have to run by yourself are managed completely by Singlestore Helios. Singlestore Helios is available in Google Cloud and in AWS, and coming soon in Azure as well. And so you can start up a Singlestore Helios cluster in the public cloud and the region that you would like.
Q: Who should own the Kubernetes YAML files, developers or Operations?
A: When we were digging into volumes and persistent volumes, we started talking about this mechanism. If developers choose to own these, then developers should own the persistent volume claim and the pod definition. Probably also the service and the deployment. And operations should own the persistent volume and the storage. That’s a really elegant separation of concerns where all of the physical details are owned by Operations and all of the application specific details are owned by developers.
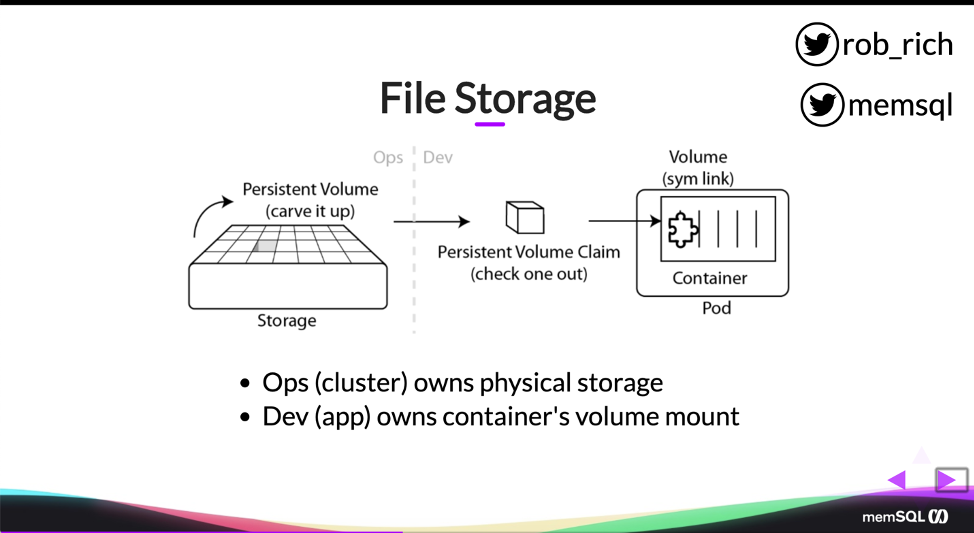
Now, we may choose to take a little bit different approach as well. We may just say, developers just want to focus on their app, and they just want to deploy it to somewhere, at which point we could opt to make all of the YAML files an Operations-specific thing. Perhaps they’re just bundled in as part of the build, and developers just build their application and commit their source code and the build server, the DevOps pipeline, actually pulls in all of the YAML files and containerizes the application and does all the things.
That is a way to kind of simplify those details away from developers so they don’t have to worry about them. The downside is it makes it more difficult for developers to really experience the same mechanism that applications run in when they’re in production.
At that point, developers say, “Well, how do I SSH into my container to do the last little bit of configuration?” That’s not really a thing in containers (laughs). So if you can give the YAML files to developers, I think that will really help in leveling up their skills and helping them really experience the system as it runs in production. If developers really, really don’t want to deal with it, perhaps you have a separate DevOps team that handles the integration pieces that would kick off during the build, but that does create layers of hierarchy that can get in the way sometimes.
Q: Why would I use containers over a platform-as-a-service, like Azure Web Apps or AWS Elastic Beanstalk?
A: Elastic Beanstalk is great for hosting apps. I may want to put them even into Lambda as a function-as-a-service. And that is a great abstraction platform. Under the hood, they probably have this load balancer that goes across all of the instances. They may have an ingress mechanism where I’m specifying the certificate. And if their assumptions on my hardware and framework really work for me, then Elastic Beanstalk or Azure Web Apps may be perfect.
As I get deeper into microservices, and I really want to take control over all of these containers and pods, and I want to create a mechanism where some containers are exposed publicly and some are only exposed to other services, as I want to get into authentication between services, then that’s where the platform-as-a-service mechanisms kind of fall down. They’re built more for that simpler case, where I have a website – arguably, a monolithic website – that I just want to get online. As I want to dig in deeper, I may want to take control of those pieces, and that’s when I want to go more towards containers and Kubernetes. If I’m just in that simpler case, maybe platform as a service or function as a service might even be a cheaper option for me.
Q: Should I provision my volume storage in the Kubernetes’ worker nodes hard drives?
As we were doing the volumes here, we were looking at – this one was mounted to the hostPath, which means written onto the hard drive of the Kubernetes node, that Kubernetes machine. And that is dangerous. We’re assuming that that node stays, that that’s persistent. I probably want to put this on my SAN (storage area network), or put this in an S3 bucket, perhaps an Azure Files storage where that data is more durable and available across all the nodes in the environment. If I just need a temporary folder to be able to dump stuff for a time and make sure that it’s available for the next request, perhaps the hostPath is sufficient, but it depends on the need.
hostPath is definitely faster, and so we won’t have network latency associated with getting to that persistent store. But it is fragile. We’re assuming when we say hostPath, that we don’t have pods on different nodes in our cluster, and that our host stays up. If that EC2 instance that happens to be running our cluster reboots or dies, then that hostPath resource may be gone on the next request. hostPath is great for temporary things. It’s not great for super durable things.
Q: Do I need an Ingress controller to run stateless content?
To get web traffic into stateless k8s resources, you generally have two options. Either you create an Ingress controller (the preferred way for http/https traffic) or you modify your service to be of type LoadBalancer (the preferred way for non-http traffic like tcp traffic).
An operator is not necessary to make stateless content work. An operator is a k8s mechanism to abstract away the details of an application that has many parts. One could configure the operator to simply say “I’d like my cluster to have 4 nodes”, and the operator can create the Deployments, Services, ConfigMaps, PersistentVolumes, PersistentVolumeClaims, Roles, RoleBindings, ServiceAccounts, and CronJobs to make it work. Without an operator, one would need to make all these things one’s self and manage their interrelated dependencies. An operator still does all this complexity, but wraps it in a simple experience for the consumer.
It is not correct that to do stateless one /must/ use Ingress, and it is also not correct that to do stateful one /must/ use an operator. It is correct that using Ingress makes stateless easier, and that using an operator makes stateful and stateless management easier.
Conclusion
This blog post, File Storage, Configuration, and Secrets, is the third in a series. The first, Kubernetes & State, and the second, File Storage, Configuration, and Secrets, appeared previously. These are all part of a series covering Rob Richardson’s recent DZone webinar.
You can try SingleStore for free today. If you download the SingleStore database software, and want to manage it with Kubernetes, download the SingleStore Kubernetes Operator as well. Alternatively, use Singlestore Helios, our elastic managed database service in the cloud. We at SingleStore manage Singlestore Helios using our Kubernetes Operator, reducing complexity for you.

.png?width=24&disable=upscale&auto=webp)








