

Kubernetes was originally developed to manage containers running stateless workloads, such as computation-intensive processing tasks and web servers. It was then extended to allow you to manage stateful workloads, such as data tables and e-commerce sessions. However, doing so is not easy. One of the people who has figured out how to do this well is our own Rob Richardson, technical evangelist at SingleStore. In a recent DZone webinar, this three-part webinar series, Rob shows you how to build stateful workloads in Kubernetes. (From the link, you can easily download the slides and stream the webinar.)
The webinar was well-attended, with a solid Q&A session at the end. There’s so much going on that we’ve split the webinar into three blog posts: This blog post, Introducing State in Kubernetes; a second blog post, File Storage, Configuration, and Secrets; and a third blog post, Kubernetes StatefulSets and Q&A. You can read through all three for education – or use them as a step-by-step road map for actual implementation. You can also see Rob’s Kubernetes 101 blog post for an introduction to Kubernetes.
As Rob mentions during his talk, SingleStore database software is well-suited for containerized software development, managed by Kubernetes. SingleStore has developed a Kubernetes Operator, which helps you use SingleStore within a containerized environment managed by Kubernetes. Alternatively, if you want to use a Kubernetes-controlled, elastic database in the cloud, without having to set up and maintain it yourself, consider Singlestore Helios. Singlestore Helios is available on AWS, Google Cloud Platform, and is coming soon on Microsoft Azure.
Following is a rough transcript of the talk, illustrated by slides from the accompanying presentation. This initial blog post covers the original, stateless functionality of Kubernetes; how stateful workloads were added; and how to go beyond kubectl get all to actually get all the things, not just some of them.
Kubernetes as a Stateless Platform
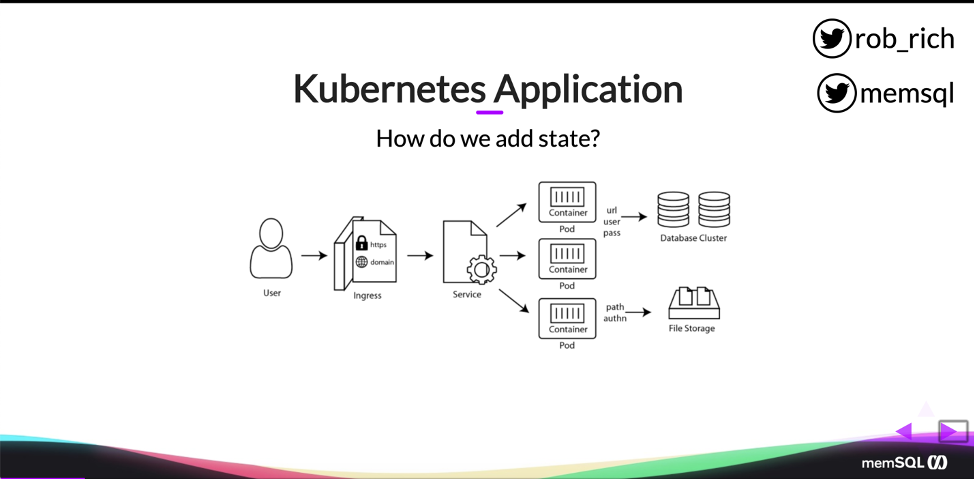
Kubernetes was originally designed to be a stateless platform, and so when we first look at Kubernetes, we probably build something like this. We’ve got our containers running inside of pods. We have a service in front of it. We may have an Ingress controller that routes traffic to the service. We got this. This is easy.
(I asked Rob for more about Ingress controllers and Operators, and he elaborated: “To make it easier to work with new or existing stateless software work in a Kubernetes environment, you can create an Ingress controller for it” – an example is this one for NGINX web server software. “To make it easier to work with new or existing stateful software work in a Kubernetes environment, you can create an Operator for it” – an example is the SingleStore Kubernetes Operator, which Rob describes further on in this webinar. He concluded by saying, “Working with an existing Operator or Ingress controller is much, much easier than creating a new one.” – Ed.)
Well yeah, it takes a little bit to get to this point, but this is really great. Users can come hit our Ingress controller. They can route to the service. The service goes to the pods, and all of that works great.

However, our apps probably look something like the below instead. We have a little bit more complexity here. So we still have our containers and they’re running inside of pods. We still have our service round robining between them. But with our Ingress controller, we’re probably terminating SSL here. So we’ll have a certificate. We’ll have domain configuration that is probably different between environments.
Additionally, we’ll likely have database content, or maybe file storage content, and we need to store configuration details to get to that content. And so we have a whole lot of state in our application that we didn’t have in that initial, simplistic example. So how do we get this state inside of Kubernetes? That’s what we’ll dig into today.
Today’s the Day Two experience, where we talk about getting state into Kubernetes. (For the Day One experience, an introduction to Kubernetes – see Rob’s previous blog post, Kubernetes 101. – Ed.) So what is state? State is anything that lives beyond the current lifetime. And so we can think of state as things living beyond the function call. That’s likely what we do when we’re writing software, is building variables that may live longer than a function call. As we talk about web requests, we may talk about things that live longer than a request and response cycle. So as I go save the data, I then need to go run another request to get that data back, and so that’s the state that I need to save.

We also have state that talks about server restarts. So I may need to save files on the file system, and if the server restarts, I want those files to stay on that file system. Or perhaps I’m going across a load balancer and so I need that file system to be shared across all my web servers. That’s state as well.
So these are the types of things that we’re going to talk about today – getting that state stored inside of Kubernetes:
- Configuration details
- Secrets
- Data stores
- File stores
- Singleton services
Among these, singleton services are special. This is a service which is making business decisions, and it needs a holistic and complete view of all of the system. So we need to have that one just maintain all of the pieces.
A database is a great example of a singleton service. We can’t have more than one copy of the database in our environment. We may have different machines as part of a single cluster, but ultimately, we need to have that one unique database. It’s not like each pod can connect to its own database and store its own data and then a different pod may get to a different database. We need to have that one single source of truth.

So we talked about configuration, secrets, data stores, and file stores, and these singleton services. Let’s dig into each one and start to explore how those work inside Kubernetes.
How to Really “Get All” for Stateful Resources
Now, one of the big annoying things is that, when we say kubectl get all, we don’t actually get everything. The name suggests that it’s supposed to get everything, but it really doesn’t. What it gets is all of the stateless resources.

The developers of Kubernetes made this choice deliberately, because for things that can’t be recreated easily, they don’t want to expose them prematurely. So that if we were to delete and recreate everything, maybe we couldn’t get that secret back, because we didn’t have the unencrypted data. Or if we destroyed and recreated a stateful service like a database, we couldn’t get that data back. So kubectl get all deliberately doesn’t show stateful resources.
The bummer part then is, as we go start exploring stateful resources, we’ll probably need a different mechanism for getting them. Now, we can definitely say kubectl get, and each of the things, and just list them. But if we say kubectl get all, we need to know that maybe our resources aren’t all listed there.
Luckily, there is a mechanism to get all the things. It’s massively complex.

First, I go grab all of the resources, kubectl api-resources. That will list all of the resources in my cluster, including custom resources, perhaps added by third party packages. Given that list, I could run that through an awk script to go grab the name, and I could comma separate them, and then I could say kubectl get that big list. So that’s kubectl get, kubectl api-resources, pipe it to awk, pipe it to grep, pipe it to xargs, pipe it to sed. I have that as an alias in my shell so that I can get all the all the things, including all of the stateful resources. You may choose to download these slides and copy that into your bash profile, as well and have a similar alias for truly getting all of the things.
Conclusion
This blog post, Introducing State in Kubernetes, is the first in a series covering Rob Richardson’s recent DZone webinar. Coming soon: the second blog post, File Storage, Configuration, and Secrets; and the third blog post, Kubernetes StatefulSets and Q&A.
You can try SingleStore for free today. If you download the SingleStore database software, and want to manage it with Kubernetes, download the SingleStore Kubernetes Operator as well. Alternatively, use Singlestore Helios, our elastic managed database service in the cloud. We at SingleStore manage Singlestore Helios using our Kubernetes Operator, reducing complexity for you.














