

The amount of data created in the past two years surpasses all of the data previously produced in human history. Even more shocking is that for all of that data produced, only 0.5% is being analyzed and used. In order to capitalize on data that exists today, businesses need the right tools to ingest and analyze data.
At SingleStore, our mission is to do exactly that. We help enterprises operate in today’s real-time world by unlocking value from data instantaneously. The first step in achieving this is ingesting large volumes of data at incredible speed. The distributed nature of the SingleStore environment makes it easy to scale up to petabytes of data! Some customers use SingleStore to process 72TB of data a day, or over 6 million transactions per second, while others use it as a replacement for legacy data warehouse environments.
SingleStore offers several key features for optimizing data ingest, as well as supporting concurrent analytics:
High Throughput
SingleStore enables high throughput on concurrent workloads. A distributed query optimizer evenly divides the processing workload to maximize the efficiency of CPU usage. Queries are compiled to machine code and cached to expedite subsequent executions. Rather than cache the results of the query, SingleStore caches a compiled query plan to provide the most efficient execution path. The compiled query plan does not pre-specify values for the parameters, which allows SingleStore to substitute the values upon request, enabling subsequent queries of the same structure to run quickly, even with different parameter values. Moreover, due to the use of Multi-Version Concurrency Control (MVCC) and lock-free data structures, data in SingleStore remains highly accessible, even amidst a high volume of concurrent reads and writes.
Query Execution Architecture
SingleStore has a two-tiered architecture consisting of aggregators and leaves. Aggregators act as load balancers or network proxies, through which SQL clients interact with the cluster. Aggregators store metadata about the machines in the cluster and the partitioning of the data. In contrast, leaves function as storage and compute nodes.
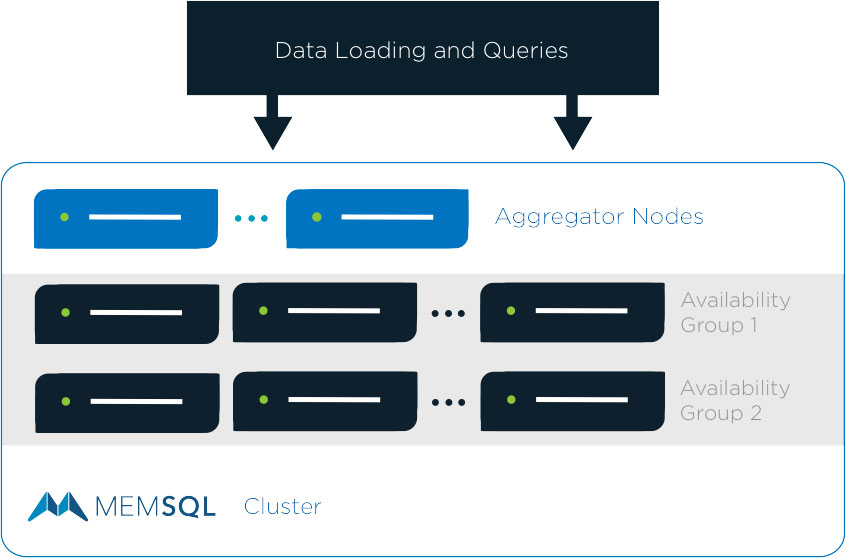
Highly Scalable
The highly scalable distributed system allows clusters to be scaled out at any time to provide increased storage capacity and processing power. Sharding occurs automatically and the cluster re-balances data and workload distribution. Data remains highly available and nodes can go down with no effect on performance.
In addition to being fast, consistent, and scalable, SingleStore persistently stores data. Transactions are committed to disk as logs and periodically compressed as snapshots of the entire database. If any node goes down, it can restart using one of these logs.
In-Memory and On-Disk Storage
SingleStore supports storing and processing data with an in-memory rowstore, or a memory or disk-based columnstore. The rowstore works best for optimum performance in transactional workloads because of the sheer speed of in-memory processing. The columnstore operates best for cost-effective data storage of large amounts of historical data for analysis. A combination of the rowstore and columnstore engines allows users to analyze real-time and historical data together in a single query.

Streamliner
In 2015, SingleStore introduced Streamliner, an integrated Apache Spark solution. Streamliner allows users to build real-time data pipelines. It extracts and transforms the data through Apache Spark, and loads it into SingleStore to persist the data and serve it up to a real-time dashboard or application.
Streamliner comes with a versatile set of tools ranging from development and testing applications to personalization for managing multiple pipelines in production. You can use Streamliner through the Spark tab in the SingleStore Ops web interface and through the SingleStore Ops CLI.
In addition to saving time by automating much of the work associated with building and maintaining data pipelines, Streamliner offers several technical advantages over a home-rolled solution built on Spark:
Streamliner provides a single unified interface for managing many pipelines, and allows you to start and stop individual pipelines without affecting other pipelines running concurrently.
Streamliner offers built-in developer tools that dramatically simplify developing, testing, and debugging data pipelines. For instance, Streamliner allows the user to trace individual batches all the way through a pipeline and observe the input and output of every stage.
Streamliner handles the challenging aspects of distributed real-time data processing, allowing developers to focus on data processing logic rather than low level technical considerations. Under the hood, Streamliner leverages SingleStore and Apache Spark to provide fault tolerance and transactional semantics without sacrificing performance.
The modularity of Streamliner, which separates pipelines into Extract, Transform, and Load phases, facilitates code reuse. With thoughtful design, you can mix, match, and reuse Extractors and Transformers.
Out of the box Streamliner comes with built-in Extractors, such as the Kafka Extractor, and Transformers, such as a CSV parser and JSON emitter. Even if you find you need to develop custom components, the built-in pipelines make it easy to start testing without writing much or any code up front.
Trial License
With these extensive capabilities for massive data ingest and analytics, SingleStore provides a robust solution for large influxes of data from IoT sources, business transactions, applications, and a variety of new sources cropping up today. Try it for yourself today: singlestore.com/cloud-trial/
Get The SingleStore Spark Connector Guide
The 79 page guide covers how to design, build, and deploy Spark applications using the SingleStore Spark Connector. Inside, you will find code samples to help you get started and performance recommendations for your production-ready Apache Spark and SingleStore implementations.
Download Here

.png?width=24&disable=upscale&auto=webp)








