
There is a trend in industry which says that modern applications need to be built on top of one or more special-purpose databases. That every application benefits from using the best-of-breed technology for each requirement. And that the plethora of special-purpose options available from certain cloud providers is reasonable to manage. That’s all BUNK. The reality is that navigating the choices, figuring out how to use them effectively, and dealing with the ETL and inevitable data sprawl, is so difficult that the pain far outweighs any technical advantage you might get. In the vast majority of use cases, a single modern, scalable, relational database can support all of an application’s needs, across cloud providers and on-premises.

Over the past decade, applications have become more and more data-intensive. Dynamic data, analytics, and models are now at the core of any application that matters. In order to support these requirements, there is a commonly held belief that modern applications need to be built on top of a variety of special-purpose databases, each built for a specific workload. It is said that this allows you to pick the best ones to solve your application needs.
This trend is apparent when you look at the plethora of open source data tools that have proliferated in recent years. Each one was built to scratch an itch; optimized for specific, narrow use cases seen in a smattering of projects. In response, some of the cloud vendors have packaged up these multiple database technologies for you to choose from, commonly forking from existing open source projects. You’re then meant to wire together several of these tools into the needed data solution for each application.
On the surface, the argument seems logical. Why bother to build or use general-purpose technology across multiple problem domains, maybe having to work around limitations that come from being a general-purpose solution, when you can use multiple tools, purpose-built for each of the specific problems you are trying to solve?
Andy Jassy, CEO of AWS, made this point in his keynote at the company’s Re:Invent conference recently. Saying: “In the past, customers primarily used relational databases, and the day for that has come and gone…. Customers have asked for, and demand, purpose-built databases.”
The claim is that relational databases are too expensive; not performant; don’t scale. That is supposedly why Amazon offers eight operational databases. (It had been seven, but they announced another one at the conference: Amazon Managed Apache Cassandra Service.) This is not including the various analytic data warehouse technologies from AWS, such as Redshift, Athena, and Spectrum. Jassy goes on a rant about how anyone who tries to convince you otherwise is fooling you, and you should just ignore the person and walk away. (See the 1:18:00 mark in the keynote.)
Well, I am that person – and I am not alone.
This is not to say that there is no value in each of the special-purpose database offerings. There are certainly use cases where those special purpose databases shine, and are truly the best choice for the use case. These are cases where the requirements in one specific dimension are so extreme that you need something special-purpose to meet them.
But the absolute requirement for specialty databases is mostly in outlier use cases, which are a tiny fraction of the total of workloads out there. In the vast majority of apps that people build, the requirements are such that they can be satisfied by a single, operational NewSQL database – a distributed relational database, supporting a mix of transactional and analytical workloads, multi-model, etc. – such as SingleStore. This is especially true when you find you need more than just a couple of special-purpose databases in your solution, or when your requirements are expected to change over time.
The burden of choice has always been the dilemma of the software engineer. It used to be that the choice was whether to buy an existing component or to build it yourself. You had to make the trade-off between the dollar cost to purchase the component – and the risk it might not be as good as you hoped – vs. the cost, in time and engineering resources, to build and maintain a custom solution.
Most experienced engineers would likely agree that, in most cases, it is better to buy an existing component if it can meet the requirements. The cost to build is always higher than you think, and the cost to work out issues and to maintain the solution over time often dwarfs the initial cost. In addition, having someone to call when something breaks is critical for a production system with real customers.
But then things changed.
How Choices Have Ballooned with Open Source and the Cloud
The emergence of open source software has fundamentally changed the “build vs. buy” choice. Now, it is a choice of build, buy – or get for free. And people love free.
Most engineers who use open source don’t really care about tinkering with the source code and submitting their changes back to the code base, or referring to the source code to debug problems. While that certainly does happen (and kudos to those who contribute), the vast majority are attracted to open source because it is free.
The availability of the Internet and modern code repositories like Github have made the cost to build software low, and the cost to distribute software virtually nothing. This has given rise to new technology components at a faster rate than ever seen before. Github has seen massive growth in the number of new projects and the number of developers contributing, with 40 million contributors in 2019, 25% of whom are new, and 44 million repositories.
On the face of it, this seems great. The more components that exist, the better the odds that the one component that exactly matches my requirements has already been built. And since they are all free, I can choose the best one. But this gives rise to a new problem. How do I find the right one(s) for my app?
Too Many Options
There are so many projects going on that navigating the tangle is pretty difficult. In the past, you generally had a few commercial options. Now, there might be tens or hundreds of options to choose from. You end up having to narrow it down to a few choices based on limited time and information.
Database technology in particular has seen this problem mushroom in recent years. It used to be you had a small number of choices: Oracle, Microsoft SQL Server, and IBM DB2 as the proprietary choices, or MySQL if you wanted a free and open source choice.
Then, two trends matured: NoSQL, and the rise of open source as a model. The number of choices grew tremendously. In addition, as cloud vendors are trying to differentiate, they have each added both NoSQL databases and their own flavors of relational (or SQL) databases. AWS has more than 10 database offerings; Azure and GCP each have more than five flavors.
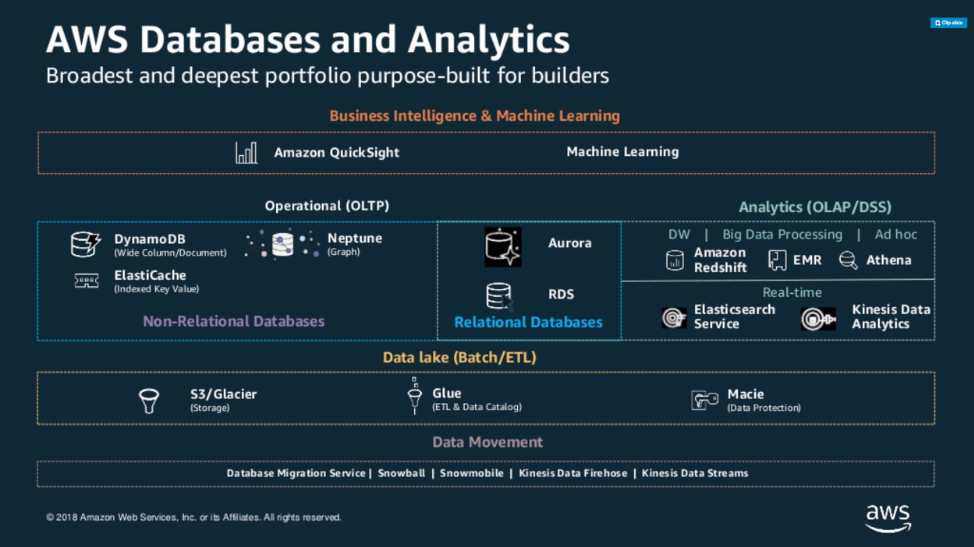
DBEngines (a site for tracking the popularity of database engines) has more than 300 databases on the list, with new ones getting added all the time. Even the definition of what is a “database” has evolved over time, with some simple data tools such as caches marketing themselves as databases. This is making it difficult to know, without a lot of research, whether a particular technology will match the requirements of your application. Fail to do enough research, and you can waste a lot of time building on a data technology, only to find it has some important gap that tanks your design.
Choosing a Specialty Database Type
There are many different flavors of databases on the list. Operational databases and data warehouses are the most common types, but there are several more. Each has a set of requirements which they solve.
| Database Types | Requirements |
|---|---|
| Operational Databases Oracle, SQL Server, Postgres, MySQL, MariaDB, AWS Aurora, GCP Spanner | - Fast Insert - Fast Record Lookup - High Concurrency - High Availability - High Resilience - Relational Model - Complex Query - Extensibility |
| Data Warehouses Teradata, Netezza, Vertica, Snowflake | - Fast Query - Aggregations - Large Data Size - Large Data Load - Resource Governance |
| Key-Value Stores Redis, GridGain, Memcached | - Fast Insert - Fast Record Lookup - High Concurrency - High Availability |
| Document Stores MongoDB, AWS DocDB, AWS DynamoDB, Azure Cosmos DB, CouchDB | - Fast Record Lookup - High Availability - Flexible Schema |
| Full-Text Search Engines Elasticsearch, AWS Elasticache, Solr | - Fuzzy Text Search - Large Data Sets - High Availability |
| Time Series: InfluxDB, OpenTSDB, TimescaleDB, AWS Timestream | - Simple queries over time series data |
| GraphDB: Neo4j, JanusGraph, TigerGraph, AWS Neptune | - Graph-Based Data Relationships - Complex Queries |
Table 1. Fitting Your Prospective Application to Different Database Types
Every database is slightly different in the scenario it excels at. And there are new specialty databases emerging all the time.
If you’re building a new solution, you have to decide what data architecture you need. Even if you assume the requirements are clear and fixed – which is almost never the case – navigating the bewildering set of choices as to which database to use is pretty hard. You need to assess requirements across a broad set of dimensions – such as functionality, performance, security, and support options – to determine which ones meet your needs.

If you have functionality that cuts across the different specialty databases, then you will likely need multiple of them. For example, you may want to store data using a standard relational model, but also need to do full text queries. You may also have data whose schema is changing relatively often, so you want to use a JSON document as part of your storage.
The combination of databases you can use in your solution is pretty large. It’s hard to narrow that down by just scanning the marketing pages and the documentation for each potential solution. Websites cannot reliably tell you whether a database offering can meet your performance needs. Only prior experience, or a PoC, can do that effectively.
How Do I Find the Right People?
Once you have found the right set of technologies, who builds the application? You likely have a development team already, but the odds of them being proficient in programming applications on each specific, new database are low.
This means a slower pace of development as they ramp up. Their work is also likely to be buggier as they learn how to use the system effectively. They also aren’t likely to know how to tune for optimal performance. This affects not just developers, but the admins who run, configure, and troubleshoot the system once it is in production.
How Do I Manage and Support the Solution with So Many Technologies?
Even after you pick the system and find the right people, running the solution is not easy. Most likely you had to pick several technologies to build the overall solution. Which means probably no one in your organization understands all the parts.
Having multiple parts also means you have to figure out how to integrate all the pieces together. Those integration points are both the hardest to figure out, and the weakest point in the system. It is often where performance bottlenecks accumulate. It is also a source of bugs and brittleness, as the pieces are most likely not designed to work together.
When the solution does break, problems are hard to debug. Even if you have paid for support for each technology – which defeats the purpose, if you’re using things which are free – the support folks for each technology are not likely to be helpful in figuring out the integration problems. (They are just as likely to blame each other as to help you solve your problem).
The Takeaway
Going with multiple specialty databases is going to cost you, in time, hassle, money and complexity:
- Investigation analysis. It takes a lot of energy and time to interrogate a new technology to see what it can do. The number of choices available is bewildering and overwhelming. Every minute you spend doing the investigation slows down your time to market.
- Many vendors. If you end up choosing multiple technologies, you are likely to have different vendors to work with. If the solution is open source, you are either buying support from a vendor, or figuring out how to support the solution yourself.
- Specialized engineers. It takes time and experience to truly learn how to use each new data technology. The more technology you incorporate into your solution, the harder it is to find the right talent to implement it correctly.
- Complicated integrations. The most brittle parts of an application are the seams between two different technologies. Transferring data between systems with slightly different semantics, protocols that differ, and connection technologies that have different scale points are the places where things break down (usually when the system is at its busiest).
- Performance bottlenecks. Meshing two different technologies is also where performance bottlenecks typically occur. With data technologies, it is often because of data movement.
- Troubleshooting integration problems. Tracking down and fixing these issues is problematic, as the people doing the tracking down are rarely experts in all the technologies. This leads to low availability, frustrated engineers, and unhappy customers.
Considering SingleStore – a New Solution for a New Era
Ideally, there would be a database infrastructure which is familiar; which has an interface that most existing developers know how to use and optimize; and which has functionality needed to handle 90% or more of the use cases that exist. It would need to be cloud-native – meaning it natively runs in any cloud environment, as well as in an on-premises environment, using cloud-friendly tools such as Kubernetes.
This ideal technology would also be distributed, so that it scales easily, as required by the demands of the application. This database would be the default choice for the vast majority of applications, and developers would only need to look for other solutions if they hit an outlier use case. Using the same database technology for the vast majority of solutions means the engineers will be familiar with how to use it, and able to avoid the issues listed above.
This is why we built SingleStore. Legacy databases like Oracle and SQL Server served this function for a long time. But the scale and complexity requirements of modern applications outgrew their capabilities.
These needs gave rise to the plethora of NoSQL systems that emerged out of the need to solve for the scale problem. (I discuss this in my blog about NoSQL and relational databases.) But the NoSQL systems gave up a lot of the most useful functionality, such as structure for data and SQL query support, forcing users to choose between scale and functionality.
NewSQL systems like SingleStore allow you to have the best of both worlds. You get a highly scalable cloud native system that is durable, available, secure, and resilient to failure – but with an interface that is familiar to developers and admins. It supports a broad set of functionality. It supports ANSI SQL. It supports all major data types – relational, semi-structured (native support for storing JSON and for ingesting JSON, AVRO and Parquet), native geo-spatial indexes, and Lucene-based full text indexes that allow Lucene queries to be embedded in relational queries. It has both rowstore and columnstore tables – currently merging into Universal Storage tables – supporting complex analytical workloads, as well as transactional and operational workloads.
SingleStore has support for transactions. It supports stored procedures and user-defined functions (UDFs), for all your extensibility needs. It can ingest data natively from all the major data sources from legacy database systems, to blob stores like S3 and Azure Blob, as well as modern streaming technologies such as Kafka and Spark.
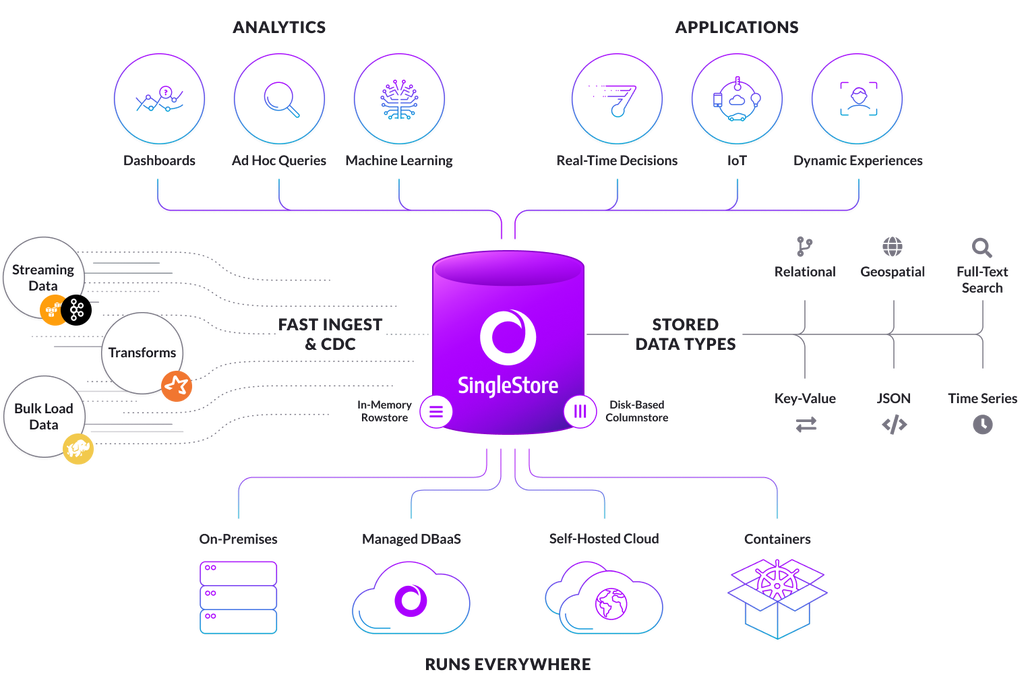
The combination of a shared-nothing scale-out architecture and support for in-memory rowstore tables means there is no need for a caching layer for storing and retrieving key-value pairs. Because SingleStore is wire protocol-compatible with MySQL, it supports a huge ecosystem of third-party tools.
SingleStore has a rich set of security features, such as multiple forms of authentication (username/password, Kerberos, SAML, and PAM). It supports role-based access control (RBAC) and row-level security for authorization. SingleStore supports encryption. You can use the audit feature to determine who accessed your data, and what was accessed.
Lastly, SingleStore can be deployed using standard command-line tools, on Kubernetes via a native Kubernetes Operator, or managed by SingleStore, via our managed service, Singlestore Helios.
SingleStore in Action
Let’s walk through some examples of a few customers who ran into these problems while first trying to build their solution using a combination of technologies, and how they ultimately met their requirements with SingleStore.
Going Live with Credit Card Transactions
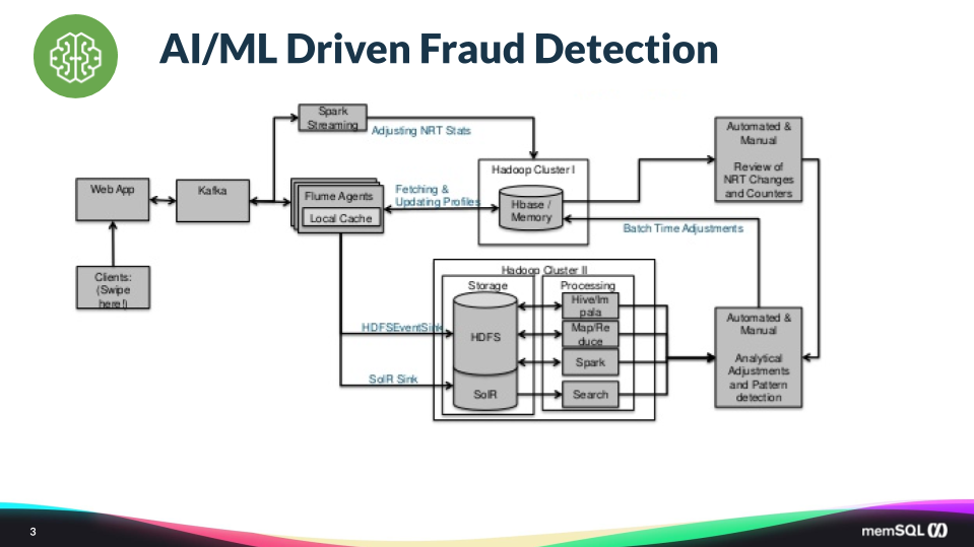
A leading financial services company ran into challenges with their credit and debit fraud detection service. The firm saw rising fraud costs and customer experience challenges that ultimately prompted re-building their own in-house solution. The goal was to build a new data platform that could provide a faster, more accurate service – one that could catch fraud before the transaction was complete, rather than after the fact, and be easier to manage.
You can see in the diagram below that the customer was using ten distinct technology systems. Stitching these systems together, given the complexity of interactions, was very hard.
Ultimately, the overall system did not perform as well as they hoped. The latency for the data to traverse all the systems was so high that they could only catch fraud after the transaction had gone through. (To stop a transaction in progress, you need to make a decision in tens or hundreds of milliseconds. Anything longer means an unacceptable customer experience.)
It was also hard to find people with the right experience in each of the technologies to be sure the system was being used correctly. Lastly, it was hard to keep the system up and running, as it would often break at the connection points between the systems.
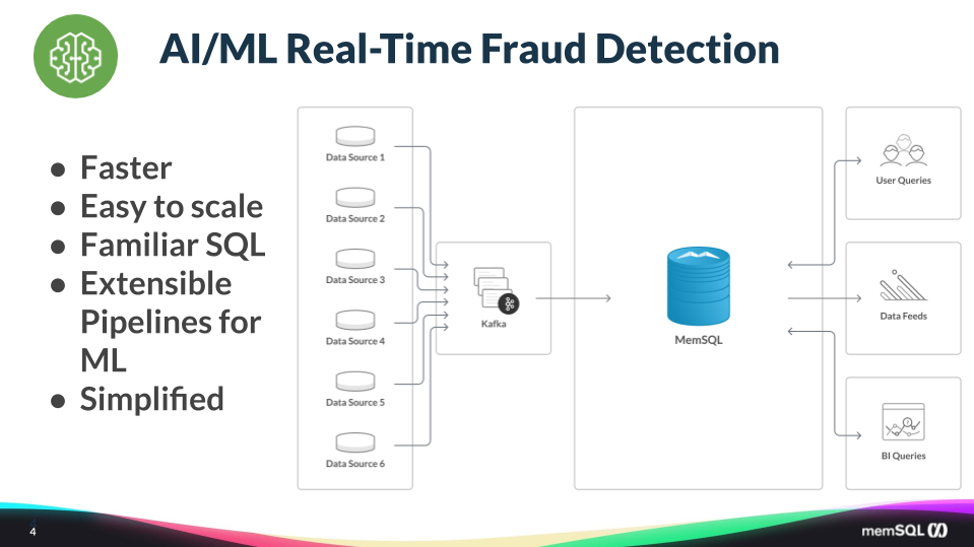
They replaced the above system with the architecture below. They reduced the ten technologies down to two: Kafka and SingleStore. They use Kafka as the pipeline to flow all the incoming data from the upstream operational systems.
All of that lands in SingleStore, where the analysis is done and surfaced to the application. The application then uses the result to decide whether to accept the credit card transaction or reject it. In addition, analysts use SingleStore to do historical analysis to see when and where fraud is coming from. They are now able to meet their service level agreements (SLAs) for running the machine learning algorithm and reporting the results back to the purchasing system, without impacting the user experience of the live credit card purchase.
Making e-Commerce Fanatics Happy
Another SingleStore customer, Fanatics, also used SingleStore to reduce the number of technologies they were using in their solution.
Fanatics has its own supersite, Fanatics.com, but also runs the online stores of all major North American sports leagues, more than 200 professional and collegiate teams, and several of the world’s largest global football (soccer) franchises. Fanatics has been growing rapidly, which is great for them as a business – but which caused technical challenges.
Fanatics’ workflows were very complex and difficult to manage during peak traffic events, such as a championship game. Business needs evolve frequently at Fanatics, meaning schemas had to change to match – but these updates were very difficult.
Maintaining the different query platforms and the underlying analytics infrastructure cost Fanatics a lot of time to keep things running, and to try to meet SLAs. So the company decided on a new approach.
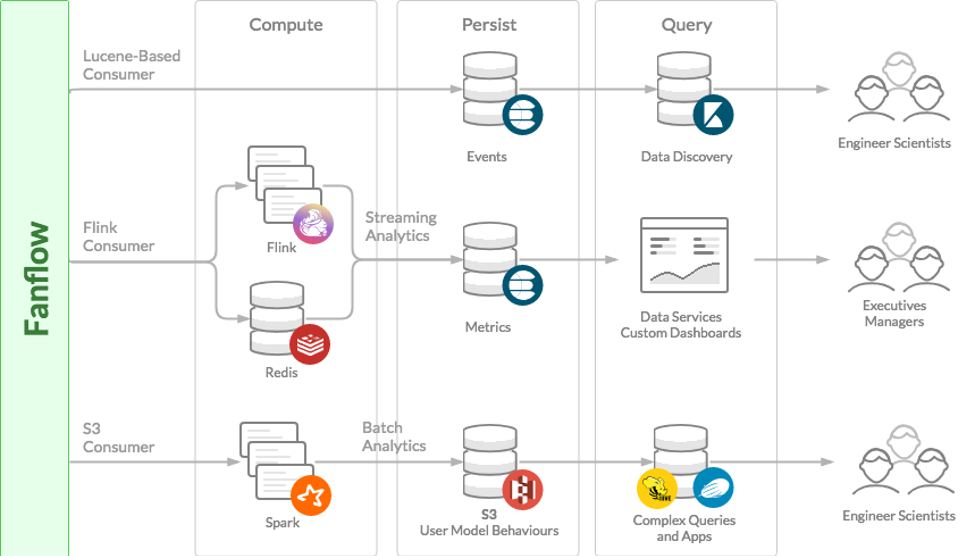
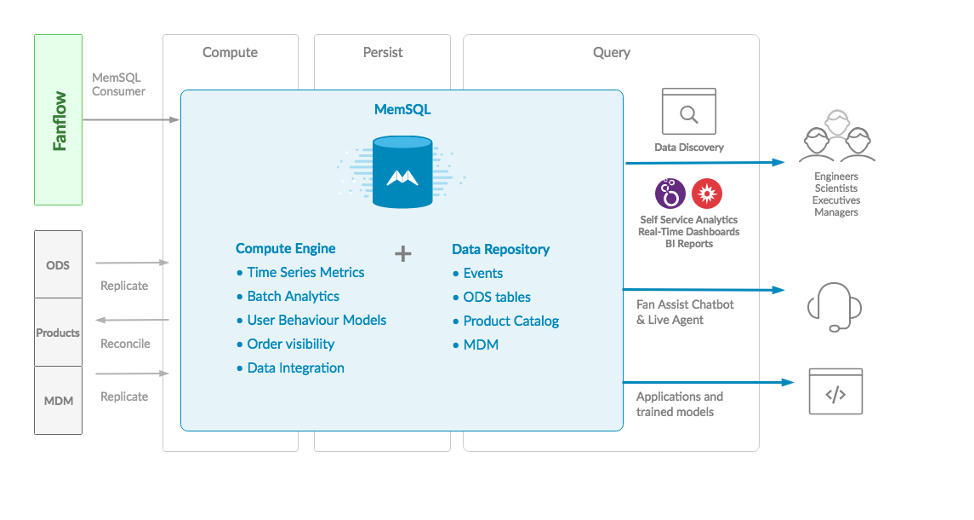
SingleStore replaced the Lucene-based indexers. Spark and Flink jobs were converted to SQL-based processing, which allows for consistent, predictable development life cycles, and more predictability in meeting SLAs.
The database has grown to billions of rows, yet users are still able to run ad hoc queries and scheduled reports, with excellent performance. The company ingests all its enterprise sources into SingleStore, integrates the data, and gains a comprehensive view of the current state of the business. Fanatics was also able to unify its users onto a single, SQL-based platform. This sharply lowers the barriers to entry, because SQL is so widely known.
The above are just two examples. SingleStore has helped many customers with simplification and performance of their application:
- SingleStore customer Thorn has built their application to find missing children using Singlestore Helios, making use of several features in SingleStore, vector matching for face matching, and full text search for text analysis.
- A major technology services company moved from a complex, multi-database solution to a simple solution, with Kafka for streaming, and SingleStore as the sole database.
- SME Solutions Group is building a business by moving their customers from complex data lake implementations to simpler, SingleStore-based solutions.
- Go Guardian, a fast-growing SaaS company, increased their scalability and simplified their infrastructure by moving from a legacy database + Druid to SingleStore.
Conclusion
Some cloud providers claim that you need to have eight different purpose-built databases, if not more, to build your application – and that it is impractical for one database to meet all of the requirements for an application.
We at SingleStore respectfully disagree. While there are some outlier use cases that may require a specialty database, the vast majority of applications can have all their key requirements satisfied by a single NewSQL database, such as SingleStore.
Even if you can build your solution using a number of special-purposes databases, the cost to investigate, build, optimize, implement, and manage those systems will outweigh any perceived benefit.
Keep it simple; use the database that meets your requirements. Try SingleStore for free today, or contact us for a personalized demo.








