

Modern tech stacks require developers to juggle several different parts of their application: frontend UI, orchestration, APIs and the database.
As application data intensity increases, each of these components grows in complexity — but developers often find that solving the database problem is the most helpful long-term solution. Today, we’ll discuss some mistakes that developers make in designing their SingleStore databases for scaling to higher ingestion rates, lower latency queries and more concurrency.
Understanding Distributed SQL Databases
Before getting into some of the areas developers struggle with, it’s important to understand a few key concepts of distributed SQL databases and SingleStoreDB Universal Storage:
- Shard Key: Partitioning data across n nodes is a concept you may be familiar with from other distributed SQL databases. The key used to partition data in SingleStoreDB is called a shard key.
- Sort Key: Also known as the columnstore key, this index dictates how column segments are sorted in a Universal Storage table. This helps ensure segment elimination when accessing data.
Mistake #1: Choosing the Wrong Shard Key
Accidentally choosing the wrong shard key is the most common mistake that SingleStoreDB developers make. This quickly becomes apparent when you may not be getting the blazing fast query speeds you expected on your first try. If you’ve already used the query profiler in SingleStoreDB, you’ll be familiar with “Rebalance” and “Broadcast” operations that also may indicate a suboptimal shard key.
Shard keys that lead to unbalanced partitions are the most detrimental to query performance. If one partition has more data than another, it will be asked to do more work during SELECTs, UPDATEs and DELETES. In this case, partitions with the least data will be the least performant, dragging down the overall execution of the query. For example, let’s take this table that we have partitioned by first (representing a user’s first name):
CREATE TABLE people (
user VARCHAR(24),
first VARCHAR(24),
last VARCHAR(24),
SHARD KEY(first)
);
Once we load data into the table, it ends up looking like this:
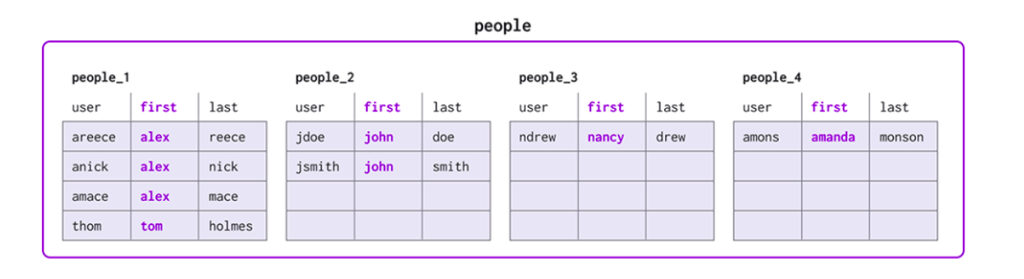
To fix this, we could try a few things:
- Change the shard key to
user, the highest cardinality column, so data is more evenly distributed across the partitions - Add an auto_increment column called
idfor even higher cardinality - Finally, we could also have a compound shard key of both options (
id,user)
Keep in mind that once data is ingested into one table, you will have to run `INSERT … SELECT …` operations to copy that data into a table with a new shard key.
It is also very important to consider your query workload when selecting a shard key. For example, say we changed the schema in the above example to the following:
CREATE TABLE people (
id INT AUTO_INCREMENT,
user VARCHAR(24),
first VARCHAR(24),
last VARCHAR(24),
SHARD KEY(id,user)
);
Consider that we would like to join to a separate address table. We want to ensure that that table has a shard key matching the people table. This ensures the join happens on a single partition within the database, significantly reducing the amount of repartitions, broadcasts and overall network traffic required with the query.
Looking for more questions to ask when selecting shard keys? We’ve got plenty.
Mistake #2: Choosing the Wrong Sort Key
The concept of a sort key is more related to SingleStoreDB’s Universal Storage table type, rather than a distributed SQL concept like shard keys. For this reason, developers almost always miss this step! Missing a sort key can leave your Universal Storage tables completely unorganized and hard to scan when you query.
Universal Storage tables store columns in segments of up to 1 million rows at a piece. Without a sort key, data is stored in segments based on the order it’s ingested. However, when a sort key is defined, segments are organized into ranges of data which makes it incredibly easy to find. For example, consider this schema:
CREATE TABLE people (
id INT AUTO_INCREMENT,
user VARCHAR(24),
first VARCHAR(24),
last VARCHAR(24),
SORT KEY (user),
SHARD KEY (id)
);
Here is an example of how the sort key takes effect. Now, if we run a query like select * from people where user LIKE e% — the query engine will only scan this segment, rather than searching across all of the segments for the answer! This is called segment elimination.

Mistake #3: Mismatched Data Types Across Tables
Comparing mismatched data types can be a silent killer of query performance. When doing comparisons in queries, it is critical to make sure the matching happens across consistent data types. Not doing so can negatively impact your query results and performance.
Take for example a simple table with an id column:
CREATE TABLE t (id VARCHAR(50), PRIMARY KEY (id));
INSERT INTO t values ('123.0');
INSERT INTO t values ('123');
INSERT INTO t values ('0123');
This query:
SELECT * FROM t WHERE id = 123;
Returns:

This may not have been the intended result of the query.
Running this same command with the EXPLAIN command before the query would yield these two warnings:
- WARNING: Comparisons between mismatched data types, which may involve unsafe data type conversions and/or degrade performance. Consider changing the data types, or adding explicit typecasts. See our mismatched data type documentation for more information.
- WARNING: Comparison between mismatched data types: (
t.id= 123). Types 'varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL' vs 'bigint(20) NOT NULL'.
In this scenario, you could consider either using quotes around the id column in the query, or changing the datatype in the DDL. Of course, the user may be perfectly content with the query result as-is, but it’s important to note the potential risk.
Documentation: Handling Data Type Conversion Level
Summary
Developers love the various different knobs they can turn on Singlestore Helios, while also maintaining the simplicity of a managed cloud database. As you have seen, there are just a few things to look out for when trying out all of the cool features of a distributed SQL database with patented Universal Storage.
Fortunately, we have a team of SingleStoreDB engineers always standing by to help! Whether you’re just getting started or you’re ready to go to production with your app on SingleStoreDB, our engineers are standing by to assist you with shard keys, sort keys or any other technical questions you have!
Schedule your time to chat with SingleStore engineers today.











