

SingleStoreDB Self-Managed 7.0リリースで初めて導入されたUniversal Storageは、SingleStoreDB Self-Managed 7.1で急速に進化しました。Universal Storageにより、SingleStoreは世界最大規模のワークロードだけでなく、多くの小規模ワークロードも、極めて高いパフォーマンスと優れた価格性能でサポートできます。このリリースでは、新しいUniversal Storage機能により、選択的クエリにおいて行ストアに近いパフォーマンスを実現しながら、列ストアのコストがかかる分析ワークロードとトランザクションワークロードの混合サポートがさらに容易になります。
これは、SingleStore独自の特許取得済みUniversal Storage機能について説明する4部構成の記事の第2弾です。全容をご理解いただくには、第1部、第3部、第4部をお読みください。
SingleStore Universal Storageは、SingleStoreDB Self-Managed 7.0で導入され、行ストアと列ストアの両方のワークロードのパフォーマンスと総所有コスト(TCO)が大幅に向上しました。SingleStoreDB Self-Managed 7.1では、列ストア側で行ストアのようなパフォーマンスの側面がさらに向上しています。高性能なハイブリッドトランザクションおよび分析処理(HTAP)ワークロードのサポートは、データベース業界でますます重要になっています。業界アナリストは、この種のワークロードを「トランスリティカル」、「オペレーショナルアナリティクス」、「拡張トランザクション」、または「分析/拡張トランザクション処理(ATP)」と呼んでいます。ここではHTAPという用語を使用します。SingleStoreはHTAPパフォーマンスで業界をリードしており、価格性能比で従来製品を10倍以上上回っています。しかし、私たちは満足していません。私たちは、世界最大のワークロードをコスト効率よく、しかもSingleStore自身を含め、これまで誰も達成できなかったコスト効率でサポートしたいと考えています。 SingleStoreは昨年12月、画期的なUniversal Storage技術を搭載したSingleStoreDB Self-Managed 7.0をリリースしました。Universal Storageの目的は、HTAPワークロードの総所有コスト(TCO)を大幅に削減することです。さらに、Universal Storage技術により、SingleStore上で、これまでよりもはるかに低いTCOで、はるかに大規模なオンライントランザクション処理(OLTP)ワークロードを実行できるようになります。SingleStoreDB Self-Managed 7.1リリースでは、Universal Storageの改良により、より多くのユースケースをより効率的に処理できるようになり、HTAPアプリケーションとOLTPアプリケーションの両方を開発する際の作業負担を軽減しています。
SingleStoreDB Self-Managed 7.0 で導入されたUniversal Storage
SingleStoreDB Self-Managed 7.0 [ SS19 ]での導入以来、Universal Storage には、HTAP と OLTP の TCO とパフォーマンスを向上させるいくつかの機能が含まれています。
- 列ストアのハッシュインデックス[ CS19 ]により、キー値を指定して列ストア内の行を高速に見つけることができます。
- サブセグメント アクセスでは、行の位置が分かれば、列ストアから行を 1 桁のミリ秒単位で非常に速く取得できます。
- 列ストアの行レベル ロック。これにより、トランザクションを待機させることなく、列ストア内の複数の行の同時更新を処理できます。
- 行ストアの SPARSE 圧縮[ RS19 ]。これにより、NULL 値を多く含む行ストア内の幅の広いテーブル (つまり、SingleStore で見られる行ストア テーブルの多く) の RAM 使用量を半分以上に削減できます。
最初の3つの変更により、これまで行ストアでしか実現できなかった多くのタスクを列ストアで実行できるようになります。これにより、お客様は列ストアの高い圧縮率と、このディスクベースのテーブルタイプを使用することによるコストメリットを活用し、これらのワークロードにおいてこれまで不可能だったTCO(総所有コスト)を実現できます。
SingleStoreDB Self-Managed 7.1 におけるUniversal Storageの進化
行ストアでのスパース圧縮の導入により、メモリ内に格納される行ストア テーブルの速度上の利点が維持され、コストが約 50% 削減されます。また、これらの変更により、価格とパフォーマンスのバランスを取るために行ストアと列ストアを混在させた実装(複雑さは増します)を使用する必要性が減ります。望ましいバランスの取れた実装は、多くの場合、行ストアのみ、または列ストアのみで見つけることができます。そして現在、SingleStoreDB Self-Managed 7.1 の一部として、列ストア側のUniversal Storageがさらに強化されています。これらの変更により、より多くの列ストア操作が高速化され、列ストアの大きな価格上の利点 (5 ~ 10 倍の圧縮、メイン ストレージにメモリではなくディスクを使用する) を活用できるようになります。また、列ストアの既存のパフォーマンス上の利点 (高速スキャンなど) と、列ストア内の特定の操作に対する新しいパフォーマンス向上により、行ストアと同等の実行時間にさらに近づきます。
Universal Storageの次の実装
私たちは多くのお客様と協力し、HTAPにおける当社製品の使用方法を理解してきました。お客様から一貫して求められていたのは、一意性制約を自動的に適用する機能の強化です。これは、長年にわたり一意キー検証をサポートしてきたSingleStore行ストアで既に実現可能です。さらに、SingleStoreDB Self-Managed 7.0では、ハッシュインデックスと列ストアのサブセグメントアクセスにより、複数のステートメントを使用して既存のキーを確認し、キーが見つからない場合はそのキーを持つ新しいレコードを挿入することができました。しかし、列ストアテーブルで標準SQLの一意制約またはキーをサポートすることは明らかに理にかなっています。そうすれば、開発者の作業はより容易になります。
ユニークハッシュキー
そこで、SingleStoreDB Self-Managed 7.1では、既存のハッシュインデックスを拡張することで、列ストアにおける単一列の一意キーをサポートするようになりました。動作の簡単な例を以下に示します。まず、一意キー列 a を持つテーブル t を作成します。
create table t(
a int,
b decimal(18,5),
shard(a),
unique key(a) using hash,
key(a) using clustered columnstore);
unique key(a) using hash句 は、SingleStore に挿入および更新された行を検証させ、
a
memsql> insert t values(1, 10.0);
Query OK, 1 row affected (0.11 sec)
memsql> insert t values(2, 20.0);
Query OK, 1 row affected (0.01 sec)
最後に、重複キー 2 を挿入してみます:
memsql> insert t values(2, 30.0);
ERROR 1062 (23000): Leaf Error (127.0.0.1:3308): Duplicate entry '2' for key 'a_2'
一意性チェックのパフォーマンス
ハッシュインデックスの一意性チェックのパフォーマンスレベルを分析するために、上記のテーブル t に1600万行を挿入しました。その後、以下のステートメントを実行して1000行の新規行を挿入しました。
insert into t
select a+(select max(a) from t), 1000000*rand()
from t
limit 1000;
insert into t
select a+(select max(a) from t), 1000000*rand()
from t
limit 1;
これら両方の INSERT ステートメントは、一意性チェックに関して OLTP レベルのパフォーマンスを示しています。
列ストアにおける高度に選択的な結合
SingleStoreDB Self-Managed 7.0 では、列ストア ハッシュ インデックスのサポートが導入され、列ストアでの OLTP タイプのクエリのサポートが拡大しました。ただし、OLTP での一般的な結合パターンでは、1 つのテーブルに非常に選択的なフィルターを適用し、ソース テーブルから 1 行または数行を生成して、それらの行を別のテーブルと結合します。OLTP 用データベースでは通常、このためにネスト ループ結合が使用されます。外部テーブルのすべての行に対して、内部テーブルでインデックス シークが実行されます。SingleStoreDB Self-Managed 7.1 では、このような選択性の高い結合を適応型ハッシュ結合アルゴリズムを使用してサポートしています。このアルゴリズムでは、まず、選択性の高いフィルターを適用したテーブルのハッシュ ビルドが実行されます。次に、ハッシュ テーブルに数行しかない場合は、ネスト ループ結合の実行に切り替え、プローブ側のテーブルの結合列のインデックスを介して、より大きなテーブル (プローブ側) をシークします。一方、ハッシュビルド側で大量の行が生成される場合は、通常のハッシュ結合が行われます。選択的結合にこの新しい戦略を活用できる、シンプルなスキーマとクエリの例を以下に示します。
create table orders(
oid int,
d datetime,
key(d) using clustered columnstore,
shard(oid),
key(oid) using hash);
create table lineitems(
id int,
oid int,
item int,
key(oid) using clustered columnstore,
shard(oid),
key(oid) using hash);
insert into orders values(1, now());
-- repeat the statement below until orders has 33.5 million rows
insert into orders
select oid+(select max(oid) from orders), now()
from orders;
lineitems に追加します。各明細項目は 1 つの注文に属し、各注文には正確に 2 つの明細項目が含まれます。insert into lineitems select oid, oid, 1 from orders;
insert into lineitems select oid + 1000*1000*1000, oid, 2 from orders;
d の選択的な日時値を見つけます。select d, count(*)
from orders
group by d;
orders の1行にのみ出現していることがわかります。そのうちの1つは 2020-03-30 16:47:05 です。次のクエリは、この日付を使用して、正確に2行の結合結果を生成します。select *
from orders o join lineitems l on o.oid = l.oid
where o.d = "2020-03-30 16:47:05";
o.dをフィルター処理して注文の 1 行を検索し、新しい選択的結合アルゴリズムを使用して、 lineitems.oidのハッシュ インデックスを介して lineitems に結合します。 SingleStore Studio のプロファイラーは、このクエリがわずか1 ミリ秒で実行されたことを示しています。 これは、列ストアの TCO の利点をすべて備えた OLTP レベルの速度です。 プロファイル プラン シェイプの関連部分を図 1 に示します。 クエリ プランは、最初に右側の ColumnStoreScan 演算子で注文テーブルをシークして 1 行を取得することによって機能します。 次に、上記のハッシュ ビルドにより、1 行を含むハッシュ テーブルが構築されます。 ビルド側が小さいことを認識して、HashJoin 演算子はネストされたループ結合戦略に動的に切り替えます。左側のlineitems の列ストア ハッシュ インデックスをシークして、一致する行を検索します。 次に結合を完了し、2 つの行を出力します。
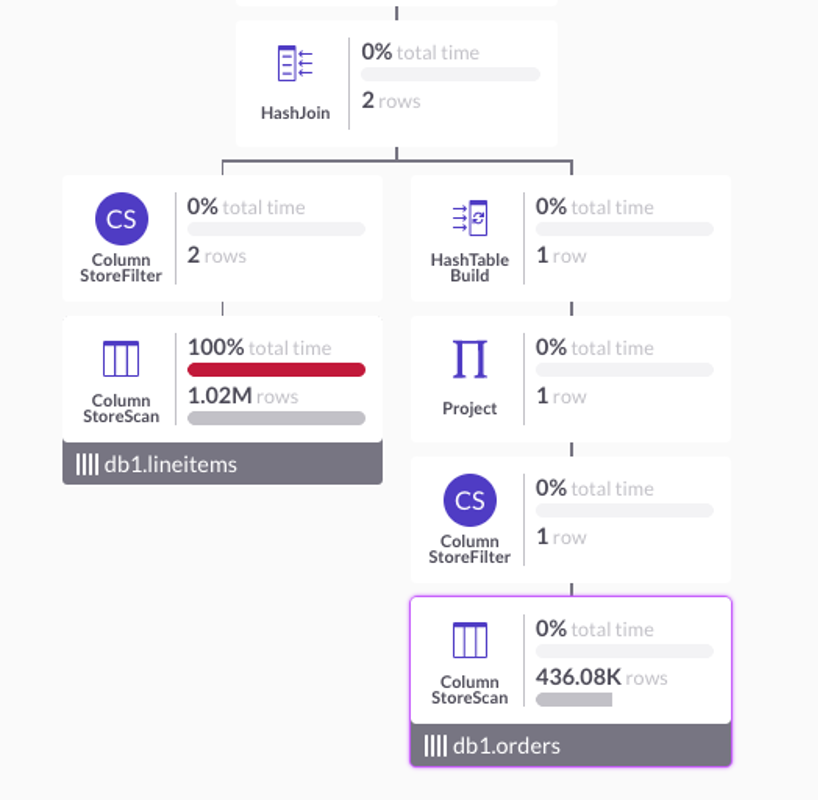
join indexと記載されています。例:"executor":"ColumnStoreFilter",
"keyId":4294968023,
"condition":[
"o.oid = l.oid bloom AND l.oid = o.oid **join index**"
],
join indexを示す条件が表示される場合があります。**CONDITION**
o.oid = l.oid bloom AND l.oid = o.oid **join index**
インデックスがない場合と比較したメリット
ordersとlineitems でハッシュ インデックスなしで同じクエリを再度実行したところ、クエリには 1 ミリ秒ではなく 7 ミリ秒かかりました。私にとって最も驚いたのは、ハッシュ インデックスがない場合でも結合パフォーマンスが 7 ミリ秒と非常に良好だったことです。これは、セグメント除去 [ OTD19 ]、エンコードされたデータの操作 [ OED19 ]、ブルーム フィルタ、サブセグメント アクセスなどの他の結合パフォーマンス機能がいかに優れているかを示しています。それでも、ハッシュ インデックスを追加すると 7 倍という劇的な改善が見られます。このテストは、ハーフハイト リーフ ノードを 1 つだけ持つ Singlestore Helios テスト クラスターで実行されました。もちろん、選択的結合パフォーマンスの結果は、ハードウェアの種類、クラスター サイズ、スキーマ、およびデータ サイズによって異なります。
結論
Universal Storageは、SingleStoreにおけるHTAPとOLTPの両方のTCOを大幅に削減するための、複数リリースにわたる主要な取り組みです。当社の列ストアテーブル型は、多くのユースケースでHTAPとOLTPをサポートするために必要なすべての機能を備えています。Universal Storageの進化は今後も継続されます。例えば、列ストアにおける複数列の一意キーや、列ストアのUPSERTサポートなどは、今後の予定に含まれています。7.1以降のリリースでも、この分野の継続的な改善にご期待ください。
SingleStore の特許取得済みユニバーサル ストレージ機能の全容を知るには、シリーズのパート 1、パート 3、パート 4をお読みください。
参考文献
[CS19] SingleStore Columnstore、SingleStore の概念、https://archived.docs.singlestore.com/v7.0/concepts/columnstore/、2019 年。 [MSL19] Leaf、SingleStore の概念、https: //archived.docs.singlestore.com/v7.0/concepts/leaf/ 、2019 年。 [OED19]エンコードされたデータに対する操作について、 SingleStore の概念、https://archived.docs.singlestore.com/v7.0/concepts/understanding-ops-on-encoded-data/、2019 年。 [OLTP17] OLTP とは何ですか? https://database.guide/what-is-oltp/、2017 年。 [OTD19]テーブル データ構造の最適化、 SingleStore ドキュメント、https://archived.docs.singlestore.com/v7.0/guides/development/development/optimizing-table-data-structures/、2019 年。 [RS19] Rowstore、SingleStore の概念、https://archived.docs.singlestore.com/v7.0/concepts/rowstore/、2019 年。 [SS19] SingleStore Universal Storage – そして、1 つに https://www.singlestore.com/blog/memsql-Universal Storage-then-there-was-one/、2019 年 9 月。

.png?width=24&disable=upscale&auto=webp)











