
Retrieval Augmented Generation (RAG)
Build modern gen AI apps utilizing the RAG framework
RAG is a technique to retrieve data from outside a foundation model by injecting the relevant, curated enterprise data into prompts before it's sent to a public or private LLM.
RAG is more cost effective and efficient than pre-training or fine-tuning foundation models. It is one of the techniques used for “grounding” LLMs with information that is use-case specific and relevant, ensuring the quality and accuracy of responses — which is critical to reducing hallucinations in LLMs.

With a performant vector database together with an enterprise-grade data platform, SingleStoreDB makes it easy and efficient to build modern gen AI applications utilizing the RAG framework.
An enterprise-grade database with vector capabilities is critical to implement RAG. In this approach, the relevant enterprise data can be vectorized and stored in a database like SingleStoreDB. You can also easily bring in transactional data feeds or analytical data from diverse sources into SingleStoreDB, using it to power your generative AI application.
Read: Why Your Vector Database Should Not be a Vector Database
When a user puts in a question, it is first matched against the curated enterprise data in the database using semantic and hybrid search. Similar matching results are added to the user prompt, which is then sent over to the LLM (like GPT-4 or Llama2.0) for an accurate response based on the enterprise data.
Read: Getting Started with OpenAI Embeddings + Semantic Search
Key steps on how RAG works
For RAG in an enterprise setting, you utilize a data store with vector capabilities, since LLMs may require information to be retrieved from various unstructured and structured data sources within the enterprise.
Questions or prompt
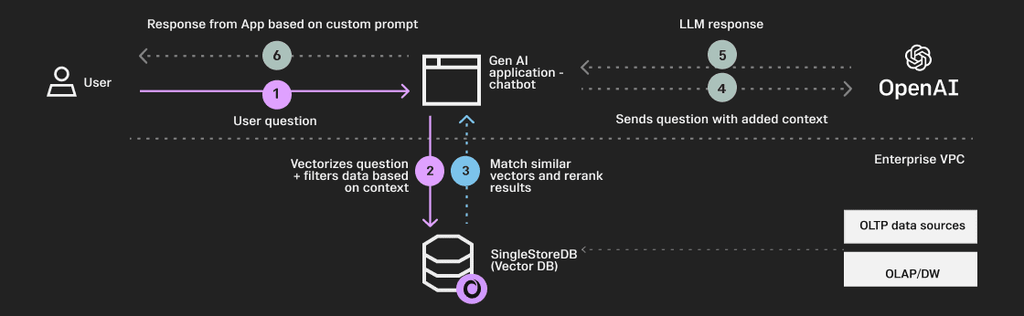
This is the first time in the interaction the user asks a question with the prompt for the chatbot. The prompt may contain a brief description of what the user expects in the output.
Querying SingleStoreDB
This is the most crucial step, where the question is vectorized and a semantic or hybrid search is carried out in real time to match and filter related documents or data within the enterprise. This may include querying SingleStoreDB as the vector and relational database, searching a set of indexed documents based on a keyword or invoking an API to retrieve data from remote or external data sources.
Millisecond extractions
In this step, the context and information relevant to the question are extracted from the curated enterprise datasets within SingleStoreDB using fast semantic and hybrid search. External data sources (including other transactional and analytical data) can be brought in as well. Results are then filtered, re-ranked and sent back to the gen AI application. All of this needs to happen in milliseconds to provide a seamless customer experience.
Increased accuracy
Once the context is generated, it’s injected into the original prompt to augment before it's sent to an LLM. The LLM receives a rich prompt with the additional context and the original query sent by the user — significantly increasing the model’s accuracy because it can access factual data.
Factually correct info
The LLM sends the response back to the chatbot with factually correct information and relevant context added on.
Get started with RAG + SingleStoreDB
Get started with quickstart modules and Notebook templates for RAG at SingleStore Spaces

Guide
A Beginner's Guide to Retrieval Augmented Generation (RAG)






















.svg)






.svg)
























