

Linus Torvalds had some interesting things to say about AVX512: “I hope AVX512 dies a painful death… I absolutely detest FP benchmarks, and I realize other people care deeply. I just think AVX512 is exactly the wrong thing to do…”. Having had the unique opportunity of migrating a portion of SingleStore’s library of SIMD kernels from AVX2 to AVX512/VBMI over the last few months, I disagree. For one thing, AVX512 is not designed solely for floating-point workloads. SingleStore’s code fundamentally deals with whizzing bytes around, and AVX512 is more than up to the task.
In case you haven't heard of SingleStore, it's an extremely high-performance distributed SQL database management system and cloud database service that can handle all kinds of workloads, from transactional to analytical. It really shines for real-time analytics (summary aggregate queries on large volumes of rapidly changing data). We get our speed through compilation and, on our columnstore access method, vectorization. Squeezing the last, best bit of performance out of our vectorized execution is where SIMD comes in. AVX2 has given us several-times speedups. I investigated whether we can double that yet again with AVX512/VBMI.
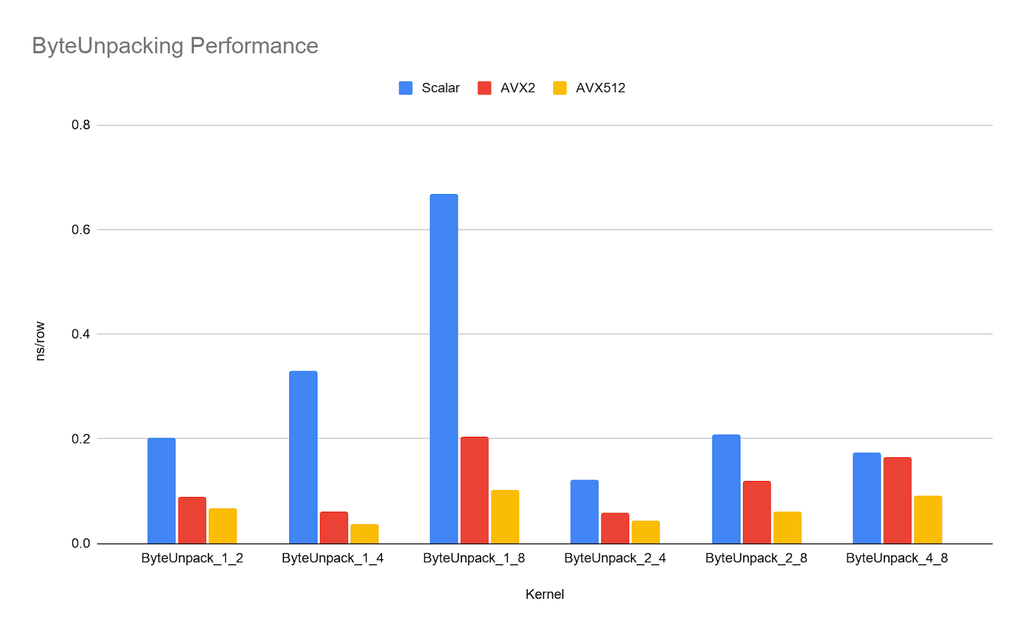
As an Intel partner with early access, I tested the performance of Ice Lake which was launched today. The results were good: on individual kernels, I could often approach or achieve a 2x speedup over the AVX2 implementation, simply by virtue of the doubled register size. While previous generations of CPUs supporting AVX512 had downclocking issues, the Icelake chips seemed to have negligible drops in clock speed even when running an AVX512 workload on all cores. Below is a chart showing the performance of the three versions of ByteUnpacking, a kernel which takes an array of values of byte width X and extends each value to byte width Y. This is denoted as ByteUnpack_X_Y in the chart. SingleStore uses ByteUnpacking extensively as data is read from disk and decoded.
However, even ignoring the performance aspects, I’d still argue that AVX512 is a big step over AVX2 for one important reason: ease of use. Developers have vectorized their code for years and will continue to do so. By making their SIMD instructions easier to use, Intel is saving developers thousands of hours. AVX512 is easier to use for two reasons:
- New, more powerful instructions
- Predicated instructions
More Powerful Instructions
AVX512 and especially VBMI/VBMI2 provide a whole suite of exciting new instructions:
- Multishift (bit-level selection of bytes)
- Expand/Compress
- Arbitrary byte-level permutes
The byte-level permutes are huge. When designing a SIMD algorithm, it’s often necessary to move data around within a register. In AVX terminology, intra-lane movement is called a shuffle while inter-lane movement is called a permute. This operation comes up in the byte unpacking kernel shown above.
As a toy example, suppose we want to put all of the even-indexed bytes in an AVX register into the lower half and the odd-indexed bytes into the top half. AVX2 provides 32- and 64-bit permutes and byte-granular shuffles. The code would look something like:
__m256i vecShuffle = _mm256_set_epi8(0xf, 0xd, 0xb, 0x9, 0x7, 0x5, 0x3, 0x1,
0xe, 0xc, 0xa, 0x8, 0x6, 0x4, 0x2, 0x0,
0xf, 0xd, 0xb, 0x9, 0x7, 0x5, 0x3, 0x1,
0xe, 0xc, 0xa, 0x8, 0x6, 0x4, 0x2, 0x0);
vec = _mm256_shuffle_epi8(vec, vecShuffle);
vec = _mm256_permute4x64_epi64(vec, 0xd8);
This pattern of a shuffle and a permute for arbitrary byte rearrangement is both frequent and cumbersome, as now there are two steps to the process. In contrast, AVX512 can do this in a single operation:
__m512i vecShuffle = _mm512_set_epi8(63, 61, 59, 57, 55, 53, 51, 49,
47, 45, 43, 41, 39, 37, 35, 33,
31, 29, 27, 25, 23, 21, 19, 17,
15, 13, 11, 9, 7, 5, 3, 1,
62, 60, 58, 56, 54, 52, 50, 48,
46, 44, 42, 40, 38, 36, 34, 32,
30, 28, 26, 24, 22, 20, 18, 16,
14, 12, 10, 8, 6, 4, 2, 0);
vec = _mm512_permutexvar_epi8(vecShuffle, vec);
Not only is this fewer instructions, it’s actually easier to think about: In the AVX512 version, we simply pick which byte ends up where by index. It’s more readable, less error-prone, and easier to write.
Predicated Instructions
AVX512 provides variants of each instruction prefixed with mask or maskz, which perform the operation only on elements with a 1 for the corresponding element in the input mask. The obvious use-case for this is conditionally performing operations. For example, SingleStore makes extensive use of both bit vectors (where true is denoted by a 1 bit) and byte vectors (where true is denoted by a 0xff byte). Using these predicated instructions, converting between the two is trivial:
__mmask64 bits = *bitVector;
__m512i bytes = _mm512_maskz_set1_epi8(bits, 0xff);
_mm512_storeu_si512(byteVector, bytes);
On top of that, AVX512’s comparisons provide bit vectors rather than byte vectors! This means that predicated instructions flow seamlessly one into another. For example, suppose we wanted to compact every element in an array greater than 10 and store it to some pointer output. We can use an instruction introduced in VBMI2 called compress, which squashes every element with a 1 in the mask to be adjacent to each other. The store variant of compress writes these to memory rather than outputting a register. AVX512/VBMI2 makes this task trivial:
__m512i vec10 = _mm512_set1_epi32(10);
__mmask16 mask = _mm512_cmpgt_epi32_mask(vecInput, vec10);
_mm512_compressstoreu_epi32(output, mask, vecInput);
The mask scheme gives the added advantage of easily knowing the number of elements passing the comparison using a popcount. The sheer utility provided by predicated instructions makes AVX512 much easier and simpler to program.
Conclusion
For the first time, I feel that I’m dealing with a friendly SIMD instruction set. I’ve only explored the tip of the iceberg with regards to the improved useability and developer-time savings provided by AVX512/VBMI. If your team is looking to improve performance but finds AVX2 or earlier daunting, give AVX512/VBMI a try. It really is easier to develop faster algorithms faster than on any other SIMD platform I’m aware of. Even if manually writing intrinsics is not your cup of tea, I’m sure compilers will have a much easier time of vectorizing code for AVX512/VBMI, and the performance benefits alone could be well worth it.

.png?width=24&disable=upscale&auto=webp)
.png?height=187&disable=upscale&auto=webp)



-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)



