

This summer, SingleStore summer intern Sarah Wooders contributed substantially to an important area of performance at SingleStore: adaptive data compression that responds optimally to network conditions. For more on the difference this makes, see the performance blog for SingleStoreDB Self-Managed 6.7. – Editor
I’m a student at MIT majoring the computer science and mathematics. My current interests are in multicore and distributed systems, as well as performance engineering. My work became part of SingleStoreDB Self-Managed 6.7.
SingleStore Load Data
In SingleStore, data is divided into partitions and stored on corresponding leaf nodes in the cluster. When a user loads a file into SingleStore, a specialized aggregator node does a minimal parse of the file. The aggregator determines the partition to which each rows belongs and then forwards rows to the corresponding leaves, where most operations are completed.
In order to maximize performance, the database code should work around bottlenecks – any operation that runs relatively slowly compared to other operations that are part of a larger process. Often times, the bottleneck in the load pipeline is the network speed between the aggregator and the leaves, especially when parallel loads are being performed. With recent performance improvements throughout the data loading pipeline, including improved SIMD parsing on aggregators, we expect network bottlenecks to be increasingly common.
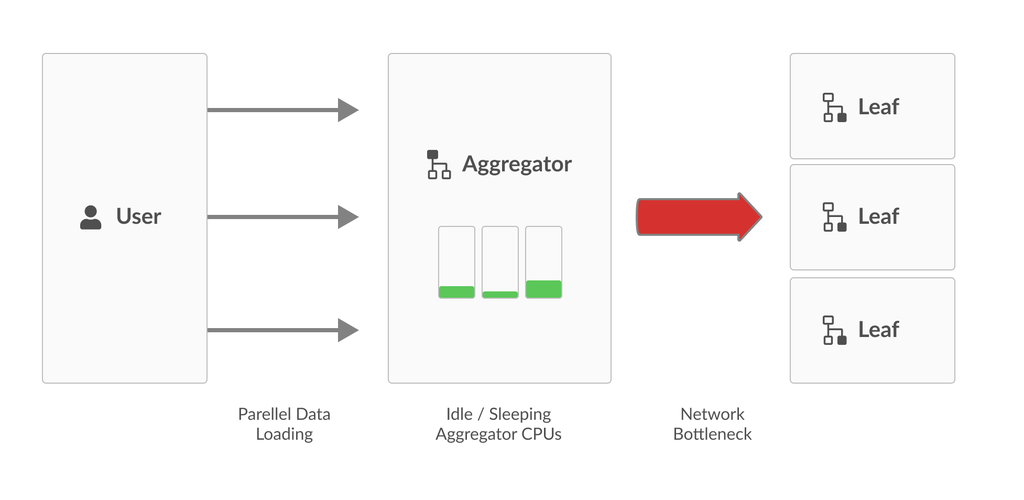
When the network is the bottleneck, aggregator CPUs spend a lot of time idle as they wait for the network to free up for more packets to be sent. So, in order to work around the bottleneck, we utilize the CPUs by having them compress packets while they wait. By having the aggregator threads compress packets while they wait on the network, we utilize otherwise unused resources to make better use of the network.
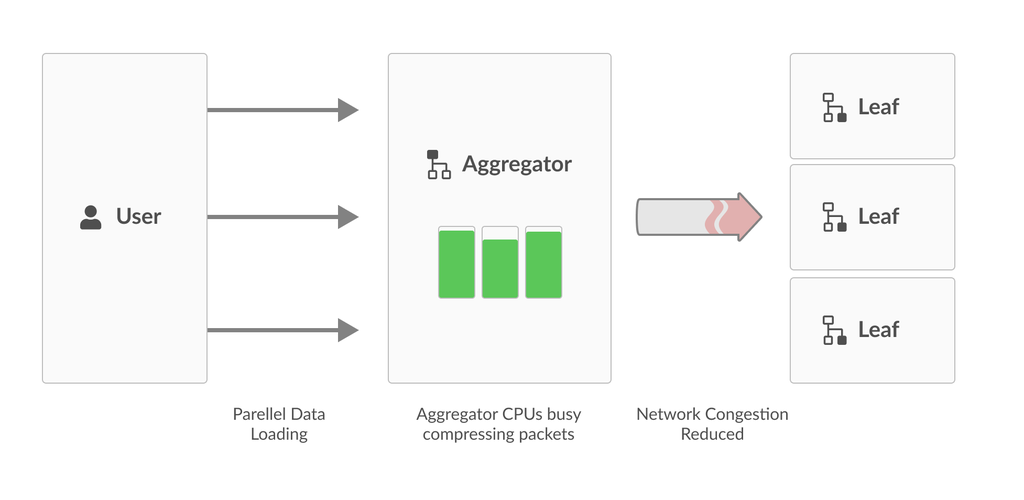
Adaptive Network Compression
If a cluster network is overloaded, while the aggregator has a large amount of CPU power at its disposal, it makes sense to compress all outgoing packets. However, when there is a less extreme disparity between network bandwidth and aggregator CPU power, compressing every buffer can actually result in the compression step being the bottleneck.
The aggregator should only compress packets when it is optimal to invest time compressing buffers instead of immediately trying to send. Thus, the primary challenge with using compression to reduce network congestion is identifying when to spend time compressing versus actually trying to send the packet.
When we started, if an aggregator tried to send a packet but experienced a failure due to congestion, the aggregator would sleep, wake up, and re-try. So the first approach we tried was to have the aggregator compress packets whenever it was supposed to sleep.
However, after implementing this approach, we found that the aggregator did not compress nearly as often as it should. Often times, the aggregator would start sleeping in the middle of sending a buffer. Partially sent buffers cannot be compressed, so the aggregator would rarely have an opportunity to compress packets, even with severe network bottlenecks.
Before we describe our final design, let’s go into some more detail about how the aggregator works. The aggregator is simultaneously parsing data and sending packets to leaves. One thread on the aggregator does the parsing, while another thread sends packets to leaves.
When the parsing thread reads a row from the loaded file, it determines which leaf partition the buffer belongs to and pushes it to a corresponding queue. The sending thread pops buffers from the same queue to send to leaves.

If the network speed allows the sending thread to send buffers quickly enough to keep up with the inflow from the buffer queue, the queue will remain mostly empty. Any buffers added to the queue will immediately be popped.
Thus, we decided how to determine when we have a network bottleneck by looking at the size of the queue. If the queue grows, we can conclude that the sending thread is falling behind the parsing thread, which probably means we have a network bottleneck.
So now, when the sending thread looks at the queue and see that more than four buffers are queued, it recognizes this as a network bottleneck. Before attempting to send the buffers, the sending thread will compress all four of the buffers in the queue.
We liked this approach a lot, not only because it was much better at immediately detecting network bottlenecks, but also because it ended up being just a couple of lines of code.
Results
We tested our new aggregator protocol using real customer data on an EC2 cluster with the following specs:
- 1 x R3.8xlarge aggregator (32 cores)
- 5 x R3.4xlarge leaves (16 cores)
- ~1 Gb/s Network
- 2.5GB input x 16 Parallel Loads = 40GB total, uncompressed
- 3x compression ratio using LZ4
We chose an aggregator with a large number of CPUs in order to try to saturate the 1GB/s network with 40GB of loaded data. We experimented with a full data load as well as a data load that skips the last stage of the load pipeline: the leaf table inserts. We chose to experiment with a load without leaf inserts as they were a bottleneck, because we were limited in the number of leaves we could include in our cluster.
| Description | Without leaf inserts | Full load |
|---|---|---|
| With compression | ~20s | ~24s |
| Without compression | ~54s | ~24s |
| Speedup | 2.7x | 2.3x |
| Average compression ratio | 2.7x | 2.9x |
| Data ingest rate | 2GB/s | 1.67GB/s |
We see that network compression allows us to load data at 1.67GB/s, which is faster than network speed!
The LZ4 compression ratio with our experiment data was 3x per packet, which means our speedup is bounded by 3x. The Level 3 load shows a speedup equal to the compression ratio, as the leaf insert time is excluded. The full load is also bottlenecked by the network; however, the full compression speedup cannot be achieved due the a bottleneck by the leaves. As a result, the full load has a higher compression ratio but lower speedup. We expect that with more leaf nodes available the speedup will approach 3x.
Concluding Thoughts
We expect a more dramatic speedup in clusters with weaker networks and more leaves. The speedup is bounded by the compression ratio, so in especially slow networks, LZ4 on a higher compression ratio setting can be used to increase the speedup.
One issue is that our protocol has no way of differentiating whether aggregator packets are failing to send because of a network bottleneck or a leaf bottleneck. In our experiment, the full load had a higher compression ratio, most likely because the pipeline was also bottlenecked by the leaves in addition to the network.
In the case where slow leaf inserts are the bottleneck, compressing packets may actually exacerbate the problem by requiring the leafs to perform decompression on the packets they receive. However, since LZ4 decompression is very fast (3900MB/s), we decided the performance impacts were negligible.
Acknowledgements
I’d like to thank Sasha Poldolsky and Joseph Victor for their mentorship throughout this project.
For more information on SingleStoreDB Self-Managed 6.7, see the press release and all eight blog posts on the new version: Product launch; managing and monitoring SingleStoreDB Self-Managed 6.7 (includes SingleStore Studio); the new free tier; performance improvements; the Areeba case study; the Wag! case study; the creation of the Visual Explain feature; and how we developed adaptive compression (this post).







-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)




