


SingleStoreDB can supercharge your apps with AI. In this blog, we demonstrate how semantic search can be performed on your data in SingleStoreDB — including code examples and a motivating case study from Siemens, a SingleStore customer.
What Is Semantic Search?
At its core, semantic search relies on natural language processing (NLP) to accurately interpret the context and intent behind a user's search query. Unlike traditional keyword-based search methods, semantic search algorithms take into account the relationship between words and their meanings, enabling them to deliver more accurate and relevant results — even when search terms are vague or ambiguous.
Semantic search relies heavily on machine learning algorithms to identify language patterns and understand concept relationships. Embeddings are a key tool in semantic search, creating vector representations of words that capture their semantic meaning. These embeddings essentially create a "meaning space," where words with similar meanings are represented by nearby vectors.
What Is SingleStoreDB?
SingleStoreDB is a real-time, distributed SQL database designed to handle both transactional (OLTP) and analytical (OLAP) within a unified engine. With support for fast writes and efficient querying, SingleStoreDB excels at managing large-scale transactional workloads and delivering real-time analytics.SingleStoreDB is available as a cloud service (Singlestore Helios) or for self-hosted installation.
SingleStoreDB is also a multi-model database and provides vector database extensions, in addition to support for relational, semistructured, full-text, spatial and time-series data. Its vector capabilities include built-in functions for vector similarity calculations such as cosine similarity and Euclidean distance.
These functions can be leveraged in SQL queries to perform similarity calculations efficiently on large volumes of vector data. Moreover, filters on metadata (other descriptive data about objects for which you've created vector embeddings) can be easily intermixed with vector similarity search, by simply using standard SQL WHERE clause filters. An easy way to get started is to sign up for a Singlestore Helios trial — and get $600 in credits.
Is SingleStoreDB the Optimal Foundation for Semantic Search in Your Applications?
SingleStoreDB's patented Universal Storage supports both OLTP and OLAP workloads, making it ideal for semantic search use cases. Adding embeddings to your data is simple — just place the vector data in a binary or blob column, using json_array_pack() or unhex() functions.
Efficient retrieval of high-dimensional vectors and handling of large-scale vector similarity matching workloads are made possible by SingleStoreDB’s distributed architecture and efficient low-level execution. You can also rely on SingleStoreDB’s built-in parallelization and Intel SIMD-based vector processing to take care of the heavy lifting involved in processing vector data.
This enables you to achieve fast and efficient vector similarity matching without the need for parallelizing your application or moving lots of data from your database into your application. We previously benchmarked the performance of our vector matching functions in our blog, “Image Matching in SQL with SingleStoreDB.” We ran the dot_product function as a measure of cosine similarity on 16 million records in just 5 milliseconds.
With its support for SQL, SingleStoreDB provides developers with a familiar and powerful interface for building semantic search applications. SQL can be used to create complex queries and perform advanced analytics on the text data stored in SingleStoreDB. In fact, with just one line of SQL, developers can run a semantic search algorithm on their vector embeddings, as demonstrated in the following example.
SingleStoreDB's ability to update and query vector data in real-time enables us to power applications that continuously learn and adapt to new inputs, providing users with increasingly precise and tailored responses over time. By eliminating the need for periodic retraining of machine-learning models or other time-consuming processes, SingleStoreDB allows for seamless and efficient provision of real-time insights.
See Semantic Search with SingleStoreDB in Action!
The following tutorial will guide you through an example of adding embeddings to each row in your SingleStoreDB database using OpenAI APIs, enabling you to run semantic search queries in mere milliseconds using Python. Follow along to add embeddings to your dataset in your desired Python development environment.
Our goal in this example is to extract meaningful insights from a hypothetical company’s employee review dataset by leveraging the power of semantic search. By using OpenAI's Embeddings API and vector matching algorithms on SingleStoreDB, we can conduct sophisticated queries on the reviews left by employees about their company. This approach allows us to delve deeper into the true sentiments of employees, without being constrained by exact keyword matches.
Step 1: Install and import dependencies in your environment
Install the following dependencies in your development environment using pip3.
1pip3 install mysql.connector openai matplotlib plotly pandas scipy scikit-learn requests
Then start python3 — and at the python3 command prompt, import the following dependencies.
1import os2import openai3import json4from openai.embeddings_utils import get_embedding5import mysql.connector6import requests
Step 2: Create an OpenAI account and get API connection details
To vectorize and embed the employee reviews and query strings, we leverage OpenAI's embeddings API. To use this API you will need an API key, which you can get here. You'll need to add a payment method to actually get vector embeddings using the API, though the charges are minimal for a small example like we present here. Once you have your key, you can add it to your environment variables as OPENAI_API_KEY.
1os.environ["OPENAI_API_KEY"] = "<your-openai-api-key>"2openai.api_key = os.getenv("OPENAI_API_KEY")
Step 3: Sign up for your free SingleStoreDB trial and add your connection details to your Python environment
We'll go through the example using Singlestore Helios, but of course you can self-host it and run the example in a similar way. If you're going to use our cloud, sign up for your Singlestore Helios trial and get $600 in credits.
First, create your workspace using the + icon next to your desired workspace group. S-00 is sufficient for this use case.
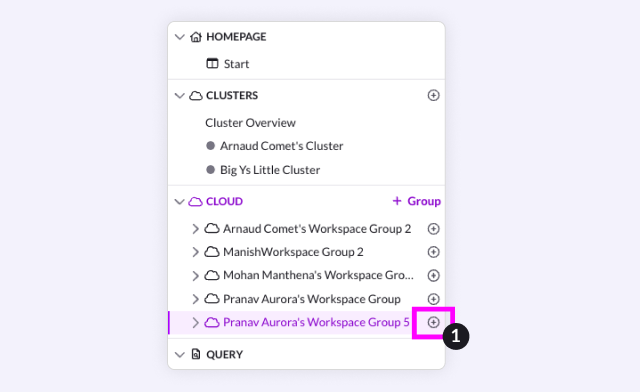
Next, navigate to your workspace group, and hit connect to your workspace. Go to SQL IDE connection details and copy your Host and Port.
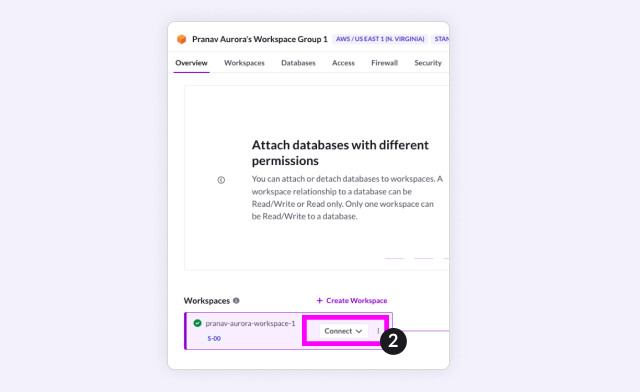
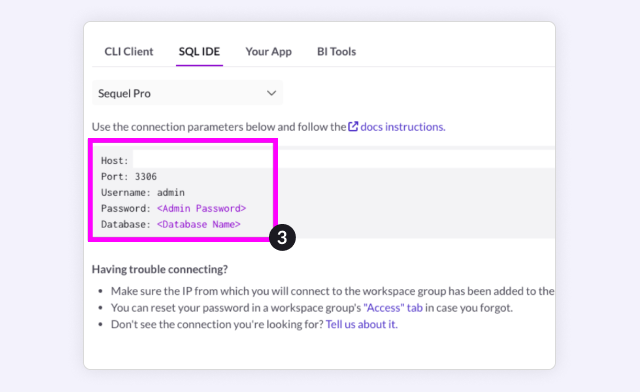
Create a database attached to this workspace and add your connection details to your development environment.
1s2dbuser = "admin"2s2dbpassword = "<your-password>"3s2dbhost = "<your-s2-db-host>"4s2dbdatabase = "<your-db-name>"
If you're developing with SingleStoreDB running locally, you could use:
s2dbuser = 'root' and s2dbhost = 'localhost' instead.
Connect to your SingleStoreDB instance using mysql.connector.
1cnx = mysql.connector.connect(2 user=s2dbuser,3 password=s2dbpassword,4 host=s2dbhost,5 database=s2dbdatabase6)
Step 4: Create a table in your database and import our sample data for this example
If you already have data you want to perform embeddings on, load your data using our docs and proceed to Step 5. To use our sample data, continue with Step 4.
First, we create a table called reviews in our database which has the schema: date_review, job_title, location, review.
1createcursor = cnx.cursor()2createquery = ("CREATE TABLE reviews (date_review VARCHAR(255), job_title VARCHAR(255), location varchar(255), review TEXT);")3createcursor.execute(createquery)
Next, we import some sample data of reviews left by employees of a firm (15 rows). This data is made up, and similar to the real dataset that Christoph Malassa at Siemens is working with.
1url = "https://raw.githubusercontent.com/singlestore-labs/singlestoredb-samples/main/Tutorials/ai-powered-semantic-search/hr_sample_data.sql"2response = requests.get(url)3sql_script = response.text4new_array = sql_script.split('\n')5 6for i in new_array:7 if (i != ""):8 createcursor.execute(i)9 10cnx.commit()
Step 5: Create vector embeddings for each entry in your SingleStoreDB database and add a new column in your database with the associated embeddings
To embed the reviews in our SingleStoreDB database we iterate through each row in the table, make a call to OpenAI’s embeddings API with the text in the reviews field and update the new column called embeddings for each entry.
1cursor = cnx.cursor(buffered=True)2 3# updates the schema of reviews to add a new column called embeddings4alterquery = ("ALTER TABLE reviews ADD embeddings blob")5cursor.execute(alterquery)6 7# selects all reviews from the table8query = ("SELECT review FROM reviews")9cursor.execute(query)10rows = cursor.fetchall()11 12# for each review, find the embeddings using OpenAI embeddings API and insert it into the database13for i in rows:14 review_embedding = json.dumps(get_embedding(i[0], engine="text-embedding-ada-002"))15 update_query = ("UPDATE reviews SET embeddings = JSON_ARRAY_PACK(%s) WHERE review=%s")16 data = (review_embedding, i[0])17 cursor.execute(update_query, data)18 19cnx.commit()20cursor.close()21cnx.close()
Step 6: Run the semantic search algorithm with just one line of SQL
We will utilize SingleStoreDB's distributed architecture to efficiently compute the dot product of the input string (stored in searchstring) with each entry in the database and return the top five reviews with the highest dot product score.
Each vector is normalized to length one, hence the dot product function essentially computes the cosine similarity between two vectors — an appropriate nearness metric. SingleStoreDB makes this extremely fast because it compiles queries to machine code and runs dot_product using SIMD instructions.
1# replace the next line with2# searchstring = input("Please enter a search string: ")3# to run interactively.4searchstring = "Unmotivated and Uninspired"5search_embedding = json.dumps(get_embedding(searchstring, engine="text-embedding-ada-002"))6 7cnx = mysql.connector.connect(8 user=s2dbuser,9 password=s2dbpassword,10 host=s2dbhost,11 database=s2dbdatabase12)13cursor = cnx.cursor()14query = ("SELECT review, DOT_PRODUCT(embeddings, JSON_ARRAY_PACK(%s)) AS Score FROM reviews ORDER BY Score DESC LIMIT 5")15cursor.execute(query, (search_embedding,))16 17results = cursor.fetchall()18 19i = 020for res in results:21 i = i + 122 print(i, ": ", res[0], "Score: ", res[1])
The preceding code shows how SingleStoreDB can perform K-nearest-neighbor search using a standard SQL SELECT … ORDER BY/LIMIT K query.
Here are some interesting results we obtained from our dataset using the input string “Unmotivated and Uninspired”. What's remarkable is that these employee reviews didn't explicitly mention these keywords in the input string, demonstrating the power of semantic search.
By embedding each review, storing the embeddings into SingleStoreDB and using efficient vector matching against the input string, we could identify the reviews that captured the same essence and meaning. This approach enabled us to quickly pinpoint which employees might feel “unmotivated and uninspired” and gain insight into the underlying reasons. Closest Matches for Search Phrase "Unmotivated and Uninspired"
Employee Review | Score |
“Excellent staff, poor salary. Friendly, helpful and hard-working colleagues Poor salary which does not improve much with progression, no incentive to work harder” | 0.783320963382721 |
“Over promised under delivered. Nice staff to work with. No career progression and salary is poor.” | 0.7829214334487915 |
“Some good people to work with. Flexible working. Out of hours language classes and aerobics. Morale. Lack of managerial structure. Doesn't seem to support career progression. No formal training.” | 0.7734369039535522 |
“Low salary, bad micromanagement. Easy to get the job even without experience in finance. Very low salary, poor working conditions, very little training provided but high expectations” | 0.7712834477424622 |
“Young colleagues, poor micro management. Very friendly and welcoming to new staff. Easy going ethic. Poor salaries, poor training and communication.” | 0.7680962085723877 |
Meanwhile, the review with the lowest score reflects a satisfied and motivated employee who enjoys the company, culture and colleagues — “The compensation package is fair, but it would be nice if they covered employee lunches. The overall work culture is great, with friendly colleagues and decent work-life balance.”
Case Study: How Siemens Runs Semantic Search for Their HR Survey Text on SingleStoreDB
One of the authors of this blog – Christoph Malassa, Head of Analytics & Intelligence Solutions at Siemens – leveraged semantic search on SingleStoreDB at Siemens to gain deeper insight into the responses from company-wide HR surveys. Siemens gathers pulse data from their employees from many sources across employee and customer surveys, and learning data (supplemental courses attended by employees).
Prior to implementing semantic search on this pulse data, Siemens was limited to searching for exact search terms to extract insights from their vast feedback data sources. However, by creating vector embeddings of the text feedback using OpenAI's embeddings API and storing the resulting embeddings in SingleStoreDB, Siemens now performs semantic search and gains deeper insights into employee satisfaction, company culture and retention.
SingleStore’s vector matching functions have also helped Siemens classify comments into categories like “IT processes,” “culture” and “work life balance” in their pulse.cloud platform. They also run a UMAP (Uniform Manifold Approximation and Projection) clustering on their embedded data to uncover common themes and trends amongst the reviews left by their employees. Their workflow follows the previous example:
- A user enters a search string or category uncovered by UMAP, e.g. “good leadership”
- That search string or category description is turned into a vector (using OpenAI GPT3 Embedding API)
- The dot product of the search vector is calculated with all embedding vectors in the database
- The text content with the highest dot product scores are displayed as best matches to the search
Christoph's results show this works well for Siemens — and the key is to have great embeddings that preserve the semantics of the input text.
Conclusion
Vector matching on SingleStoreDB helps you build advanced, high-performance semantic search capabilities into your transactional and analytical applications. To learn more, try the semantic search approach outlined in this blog with your own text data on a SingleStoreDB free trial.










-for-Real-World-Machine-Learning_feature.png?height=187&disable=upscale&auto=webp)