

Reducing or saving cost for historical/unused/archived data is a challenging task for any organizations playing with TBs or PBs of data volume.
With SingleStoreDB Self-Managed’ unlimited storage, it is very easy to reduce cost by ~85%. I’ll detail how in this article.
How to reduce cost by ~85%
Expense on STANDARD storage (non-archived) per month
By default, STANDARD storage class is used when you create any unlimited storage database on AWS S3. The following highlights the storage cost that, as of today, you will pay monthly:
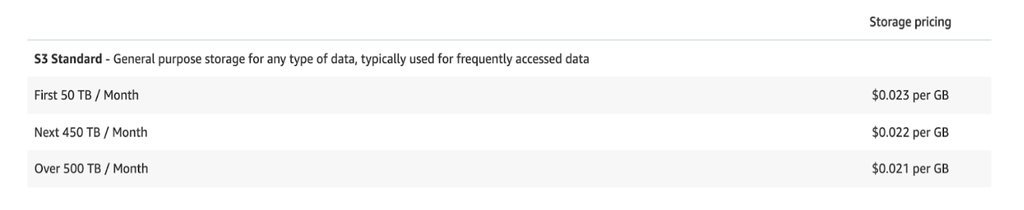
So, for 50TB/ Months you will pay: 0.023x5000GB= $115/Month
Expense on GLACIER storage class (archived data) per month
Now, if you have a good archiving (example in HOW section) policy then you can save cost by ~85% by converting your storage into a low-cost Glacier storage class. Here is a link for different Glacier storage class costs today based on your requirements:
Example (S3 Glacier Flexible Retrieval); For 50TB/ Months you will pay: 0.0036x5000= $18/Month
Cost reduced by %; Percentage Decrease=((Starting Value−Final Value)/Starting Value)×100: ((115-18)/115)*100= 84.34 = ~85%
How does it work?
Best for: Historical/Archived/Unused dataset, here are the high-level steps you can take to save money with SingleStoreDB Self-Managed:
- Create bucket in AWS S3 storage
- Create unlimited storage database on S3
- Create database archiving policy to move historical data from local database (or unlimited storage) database to unlimited storage database.
- Create Lifecycle Policy for unlimited storage database’s S3 bucket based on your requirement. (Ex. 3 months, 12 months , one year, 10 years, etc)
- After moving the data from local database to unlimited storage database for specified archived duration, take MILESTONE and DETACH database
- If you want to retrieve data from the glacier bucket you can restore it in STANDARD and ATTACH the database.
The following highlights the steps in more detail:
- Open your AWS account console. Search for S3 and create a bucket. Open this bucket and create a folder (Ex: dbdir) inside it.
2. Create an unlimited storage database on this bucket:
CREATE DATABASE testdb ON S3 "s2bottomless/dbdir" CONFIG '{"region":"us-east-1"} '
CREDENTIALS
'{"aws_access_key_id":"AKIA2B6I44NCXT7VFPFT","aws_secret_access_key":"hC+ZHSRJsuq
YFiYtIqPbAEDv/4AyIjHvigiRK69M"} ';
3. Create a database archiving policy to move data from your local database (or unlimited storage) to your unlimited storage database.
In this example, data older than 10 years is moving to an unlimited storage database using the scheduler (cron job). You can set your own policy based on your requirements:
Day 1: Insert into testdb.t1 select * from db1.t1 where ts < now()-interval 10 year;
Day 2: Insert into testdb.t1 select * from db1.t1 where ts < now()-interval 10 year;
...Run this for one year
Note: testdb is an unlimited storage database, and db1 is a local database on server.
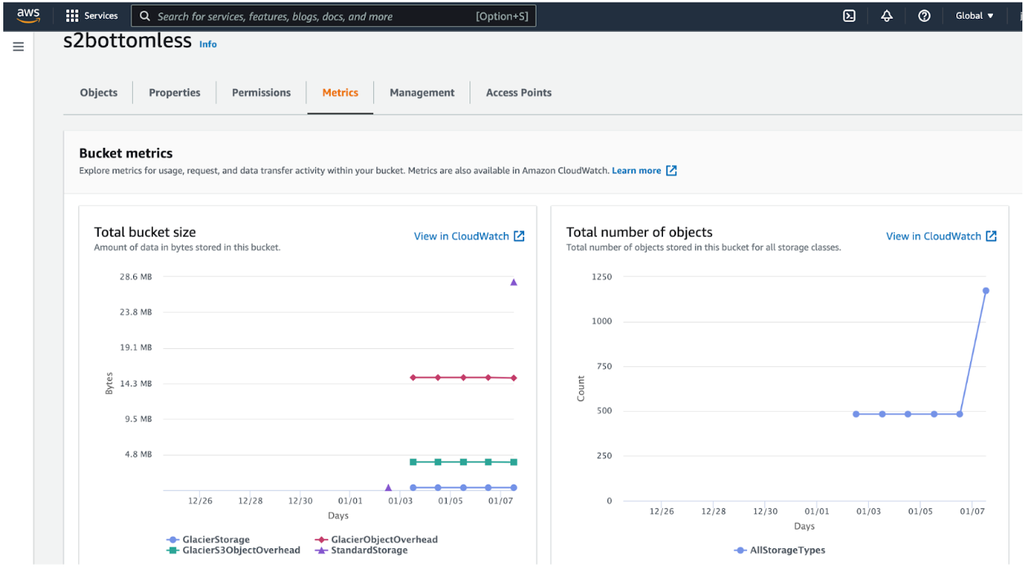
You can see the bucket size using metrics tab:
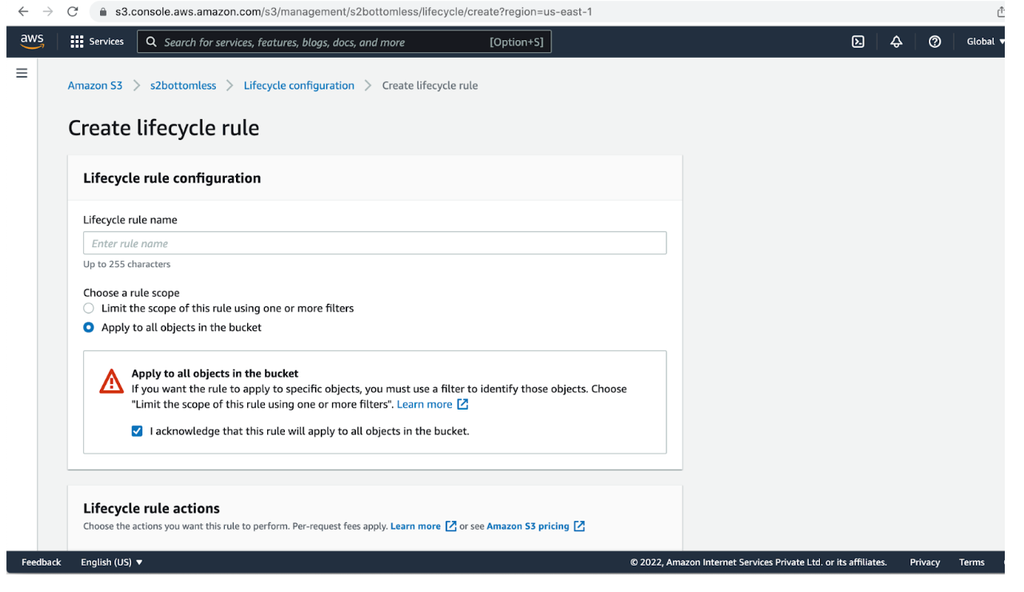
4. Create a Lifecycle policy for this bucket and folder (s2bottomless/dbdir). You can create this policy on day one, or when data is moved from the main to archive database (testdb). My choice would be after all data is moved to the archive database, (step 5) so that I can test records before it converts to glacier. Note that once your bottomless bucket is moved to a glacier, you can't fetch records from there.
Select “dbdir” folder -> go to management tab -> click on “create lifecycle rule” -> Enter some lifecycle rule name -> Select “Apply to all objects in the bucket” -> Select “Lifecycle rule actions” as per your requirement -> Choose glacier type from “Transition current versions of objects between storage classes” (I have chosen Glacier Flexible Retrieval) -> Enter the number of days when your folder should go in glacier storage after object creation -> Check all mandatory boxes -> Click on “create rule”
5. When you think the records are moved from main(db1) to archived/ unlimited storage database (testdb) then:
Create milestone:
CREATE MILESTONE "one_year_data" FOR testdb;Detach database:
DETACH DATABASE testdb;Then, create a lifecycle policy as seen in step 5.
When your bucket is moved to Glacier, you can’t attach (fetch) to a database. It will return the following error: (milestone name is different in the screenshot).

6. To fetch data from the glacier database you need to attach it. To attach this, we first need to restore it to STANDARD.
Method to restore into STANDARD storage:
- Install AWS Cli and s3cmd into any Linux machine using steps in the following links:
- AWS Cli: https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
- s3cmd: https://tecadmin.net/install-s3cmd-manage-amazon-s3-buckets/
- See the current storage type:
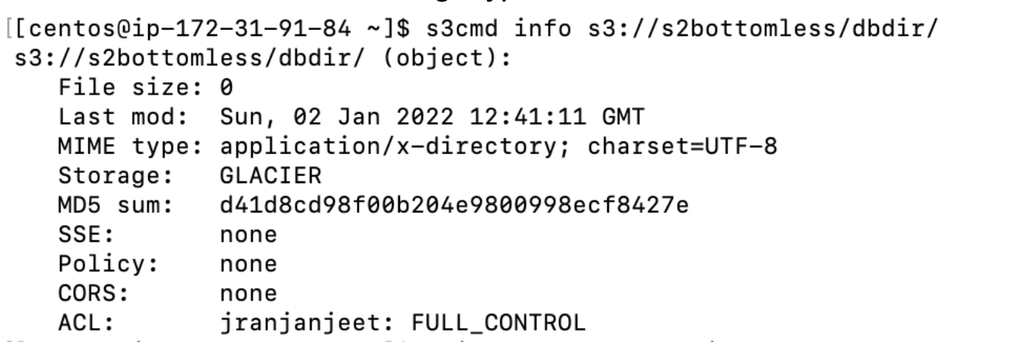
- Convert the bucket to STANDARD

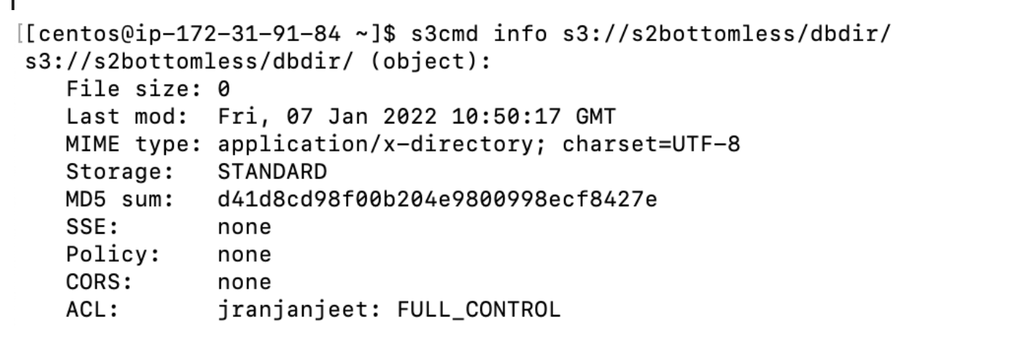
If you want to restore it for only few days (say, 7 days) then you can do this with following command, and the bucket will again go into GLACIER:
aws s3api restore-object --restore-request Days=7,GlacierJobParameters={Tier=Standard}
--bucket "s2bottomless" --key "dbdir/"- Lastly, attach the database


Additional steps to delete bucket and detach database:
singlestore> detach database testdb force;
Query OK, 1 row affected, 2 warnings (1.34 sec)
Delete Bucket









.png?width=24&disable=upscale&auto=webp)


.png?width=24&disable=upscale&auto=webp)